We have been using artificial intelligence for several years, but very few of us have taken the time to understand how Large Language Models (LLMs) work. Do you remember that moment when you asked AI to generate C# code for you and in the middle of all the code there’s a function that doesn’t exist?
In this post, which kicks off the content for the C# With AI course, we’ll address three questions that we often assume we understand… but do we really?
Table of Contents
1 - Why Does Artificial Intelligence Hallucinate? Bug or Feature?
To understand why LLMs "hallucinate," we have to understand that these are models designed to detect or predict the probability of what token follows another. That’s why hallucinations happen, because they don’t really know what’s true and what isn’t. So, we could say that hallucinating is a consequence of how LLMs are designed.
Obviously, for practical implementations, we don’t want AI to hallucinate or make up information. Popular models are hallucinating less and less, and we do have ways to mitigate these hallucinations. If we ask very specific questions, the answer will focus only on those terms, while more ambiguous questions will make the model fill in the blanks with what seems best to it. Or even the temperature parameter, which adjusts the randomness in choosing the next token, the lower it is, the more deterministic the output.
Of course, with the recent introduction of RAG, which lets us force retrieval from sources and cite them, we can mitigate these hallucinations further.
2 - Can an LLM Know Where Its Information Comes From?
If you’ve been working with language models for a while, this is an answer that’s changed recently. By default, an LLM doesn’t know where its information comes from. Everything a language model learns gets blurred into its weights during training and doesn’t carry any information about its origin, so we can’t know if what we’re reading comes from a reliable source.
Source: https://microsoft.github.io/Workshop-Interact-with-OpenAI-models/llms/
Recently, with the advent of RAG or live searches, what we’re doing is having the model read documents or web pages and only answer based on what it has read, so in that case, we can attach the source since it becomes part of the context for the response.
3 - What Are Tokens and Why Do We Have a Context Limit?
To wrap up, let’s talk about tokens. Tokens are how language models process texts and each token is simply a sequence of letters. These tokens are the units the model reads and writes. In languages, we use letters, you can’t write half a letter, and in the same way, LLMs can’t write half a token.
When you send a text to an LLM, it doesn’t process the raw text as-is, but instead it is “tokenized,” where the most frequent words are typically a single token, but rare or more complex words are split into several tokens. Spaces, too, are grouped with the word that follows them.
For an example, check out the OpenAI tool (https://platform.openai.com/tokenizer):
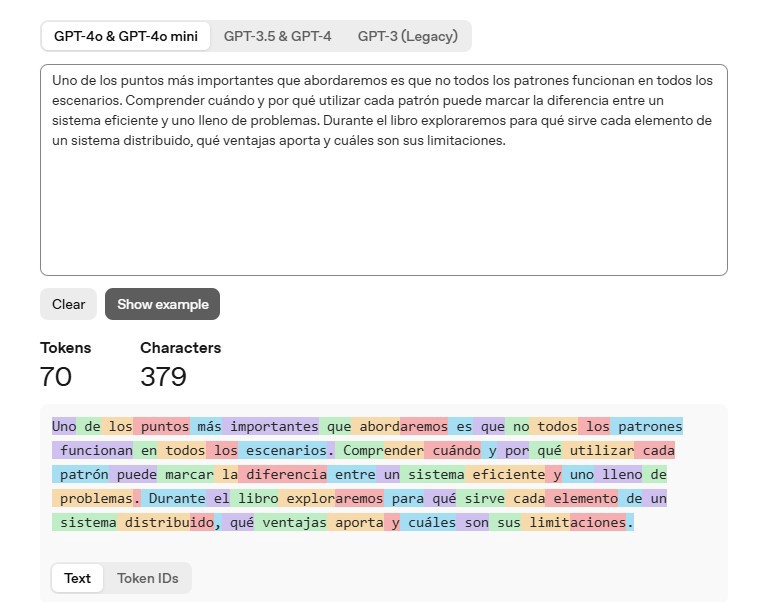
Uno de los puntos más importantes que abordaremos es que no todos los patrones funcionan en todos los escenarios.
Comprender cuándo y por qué utilizar cada patrón puede marcar la diferencia entre un sistema eficiente y uno lleno de problemas.
Durante el libro exploraremos para qué sirve cada elemento de un sistema distribuido, qué ventajas aporta y cuáles son sus limitaciones.There we can see the breakdown: simple words like “sistema” are a single token, while others like “distribuido” are two tokens. This particular paragraph from my book Construyendo sistemas distribuidos uses about 70 tokens.
Token usage is important because it’s directly related to the context. You might have seen in the latest Chat GPT-5 presentation that a context of 400k (k = thousand) tokens was shown for the API, while the ChatGPT interface supports 256k tokens, and other tools like Claude offer 200k context tokens. These numbers vary by provider and change over time, but it’s important to keep them in mind.
3.1 - What is Context?
That context is the amount of tokens an LLM can absorb or understand at once in order to predict the next token.
As you saw, a paragraph is about 70 tokens, so to fill 256k or 400k you would need a lot of text. That’s why in apps like ChatGPT, we can have memory or history, because the system adds the information it has about us into the context of the current conversation.
In programming, having this large context allows LLMs to create small applications. For large applications, though, things don’t work quite as well, precisely because of the context limit. 400k tokens is a lot, but if you go over it, the model loses the context or, well, the oldest stuff gets cut off, and remember it’s input tokens plus output tokens.
But of course, these larger contexts don’t come free, the more context, the higher the cost and latency, and tokens (along with context size) are directly tied to compute cost. Just a quick mention that the larger the context…
Another effect of large contexts is the risk that important information gets diluted, since the LLM internally normalizes the attention each token receives. This creates positional biases and of course, more text means more noise. That’s why it’s recommended to use things like numbered lists , because internally each item or request will get equal value instead of having the focus shift throughout the list.
Conclusion
I wanted to use this post as an introduction to a new series on the website, where we’ll learn to work with AI and C#.
With these three pillars, you’re now equipped to start working with and understanding the reasons behind everything you do with AI.
If there is any problem you can add a comment bellow or contact me in the website's contact form

