What happens when we use Events within our system after saving data to the database but the event fails and is not propagated? This is a question I recently received in one of my videos, and here we are going to address it.
Table of Contents
1 - Problem Context
Let’s give ourselves context: imagine we are building a system that needs to store data in the database and from there send an event. This could be any type of application or system, or even be part of a process within a SAGA, for example.
In this scenario, there are two actions:
1 - Update the database
2 - Send the event
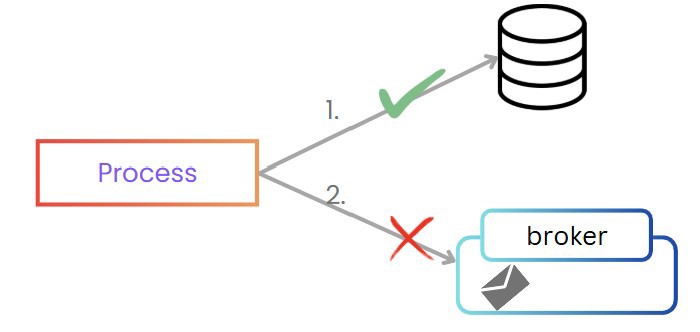
And it doesn’t matter in which order they happen , if the first process succeeds, nothing guarantees the second process will work.
One possible solution would be to add a fallback: if sending the event fails, undo the change in the database. But this solution is not realistic, because what happens if the process itself crashes?
Another option is to implement 2PC (two-phase commit), but not all databases support this functionality, nor do all message brokers, so we can discard it, at least automatically.
So, how can we ensure both actions happen?
2 - Outbox Pattern
One of the most common solutions is the Outbox Pattern. In this pattern, we have a couple of extra steps in the process. Initially, our process of inserting or modifying data in the database doesn’t just do that, it also inserts into a table called outbox_table_name the content of the event to be sent, here, we include the entire event.
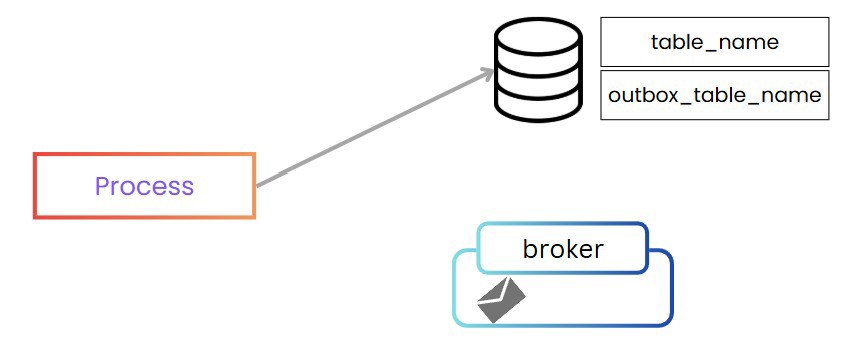
Therefore, both actions occur in a single transaction within the same database.
Afterward, we need an application which could run every minute or every X seconds. The job of this application is to read that table, publish the event to the message broker, and finally update the record as sent.

You might wonder what happens if the application fails after sending the event and before saving the update marking it as sent. In this case, we need to make sure that the events we generate are idempotent, so if the consumer receives an event it already received, it will discard it and the problem is solved.
NOTE: This extra application could also be a worker within the main application.
3 - Listen to Yourself Pattern
Another less popular alternative is the "Listen to Yourself" pattern. This involves first generating an event, which will be listened to by consumers, and one of those consumers is the application itself. This internal consumer in the application is the system that updates the database.
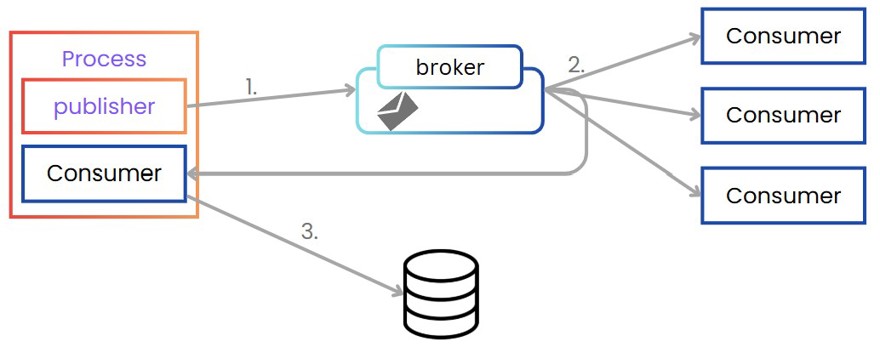
This scenario also has its issues, as it can create a race condition, where our “internal” consumer (the one generating the event) fails and does not insert the data into the database. At the same time, another consumer has received the event and may try to look something up in the database. In this situation, the database call will fail because you don’t have the expected information in the system since the “internal” consumer failed.
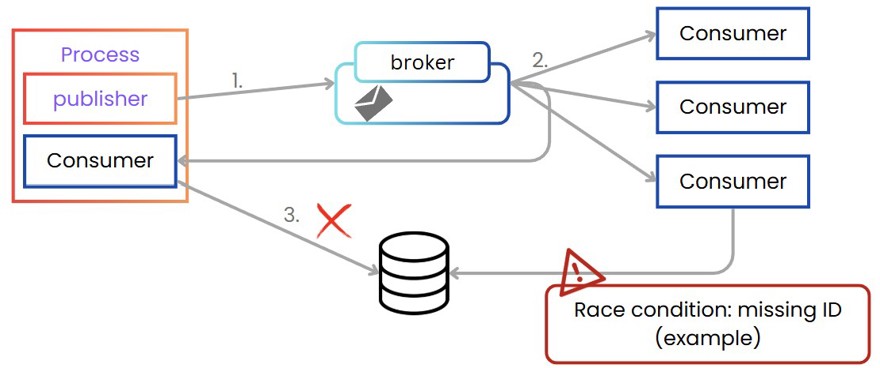
Not to mention that events are always system actions that have already happened, and in this case, we are not actually performing that action. So that’s another problem. One solution is, just like we saw in the CQRS post, generate a command or a domain event, these commands are listened to by a single consumer, which will update the read database (if you have separated read/write stores) and generate the events to be listened to by the rest of the system.
Before moving to the final point where I’ll share my experience, feel free to leave your own about these kinds of patterns in the comments! Learning from others’ experiences is always valuable.
4 - Real Usage in Companies to Ensure Consistency
In practice, the implementation of these mechanisms in companies varies a lot, not only depending on the type of company but also on what part of it or what system you are touching.
The reason is simple: under normal, ideal conditions, neither the database nor the message broker/queue/bus will fail, meaning that not having systems that ensure both actions happen is not a big problem most of the time.
For example, if you have a service that updates product details (like name, description, or images):
The database is updated, but the eventing system fails, so any other system that needs that information will still have the old data.
If this happens and the user notices, the most normal thing is for them to try the change again or contact support. Here, you have to weigh if the cost of infrastructure, setup, and development is worth it compared to the 0.1% of the time the message bus will be down in a year.
That’s not the same as a system which charges payments on a credit card or updates inventory stock. In inventory control, ensuring events happen is crucial, because otherwise you might sell (and therefore charge) for products you don’t actually have in stock, and that can be a big problem.
Needless to say, when processing payments, ensuring these events happen, and that they are only processed once, is critical for the system.
As we can see, the use of these patterns depends on what part of the system you are working with and how critical it is.
