In this post, we will explore the difference between value types and reference types, and we'll also show how C# works with both data types and the options we have.
Index
1 - Difference between value types and reference types
To determine when we should create or use a struct, a class, or even a record, we must know their characteristics, limitations, and how they work in terms of memory.
1.1 - Value types
When we use value types in C#, we are referring to structs.
But what does value type mean?
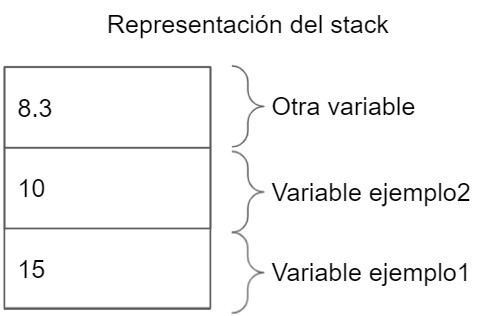
It means that when we use that object, we are using the object itself, reading and writing to the stack (we'll see what the stack is below), and when we write an object to the stack, we do so in full, not as a pointer like with reference types.
The most common case of a struct is when it represents a single value, such as a primitive type (double, int, decimal, etc). Also, it should be less than 16kb.
When we use the assignment operation (=) with a struct, what we are doing is copying the value into a new variable, not assigning the reference. So, if we modify one of the objects, the value of the other doesn't change:
int ejemplo1 = 15; // asignamos un valor inicial
int ejemplo2 = ejemplo1; // asignamos ejempo2 con el valor de ejemplo1
ejemplo2 = 10; // modificamos el valor de ejemplo 2
Console.WriteLine(ejemplo1); // imprime 15;
Console.WriteLine(ejemplo2) // imprime 10;This is important because reference types do not work in this way.
1.2 - Reference types
When we use reference types in C#, we are talking about classes, i.e., class, and since C# 9, also records. All instances of classes are located in the heap.
Ultimately, the variable itself is a pointer to that object in the heap, not the actual object.

What does it mean that classes are pointers to memory?
Imagine we have a class called Vehicle that contains properties such as make, model, and number of doors.
When we do an assignment like the following:
Vehiculo vehiculo1 = new Vehiculo(“Opel”, “Astra”, 4);We are creating vehiculo1 in the heap and assigning its memory position to its value;
So if we create a vehiculo2 and assign it the value of vehiculo1, what we are actually doing is assigning the variable the pointer to the same memory position.
Vehiculo vehiculo1 = new Vehiculo("Opel", "Astra", 4); //Creamos un vehículo
Vehiculo vehiculo2 = vehiculo1; //asignamos el vehiculo2 con el valor de vehiculo1
vehiculo2.Model = "Vectra";
Console.WriteLine(vehiculo1.Model); // imprime vectra;
Console.WriteLine(vehiculo2.Model) // imprime vectra;And as we see in the example, when we change the value of one object, "both" are updated.
All this pointer usage, unlike in other languages like C, C# does automatically behind the scenes.
The main reason why we have to do a lot of checks in C# to see if our objects are null is because of this, as the variable is actually a pointer and not the actual value.
Note: the pointer adds another 8 bytes of memory to the object's weight (in a 64-bit program), and another 16 bytes per object are added for C#'s internal use, such as the garbage collector.
Since C# 9, we have the option of using records. We mainly use them to create immutable reference types in C#.
2 - Difference between Heap and Stack
When we create an object in code, it takes up space in memory, and for that, we have two options: the heap and the stack. Here we will see how they differ and how they work.
2.1 - What is the stack?
The stack is a contiguous memory area, which is allocated from the lowest to the highest memory position, in order. And when we want to free it, we do so from the highest to the lowest position.
This means that to free a position in the middle, we must free everything placed at a higher position.
To know if a memory point is allocated, we use a pointer that points to a position in memory, and when we deallocate memory, all we do is move the pointer one place down; we do not clean the memory space. The next time we assign a value, it will just overwrite the upper value.
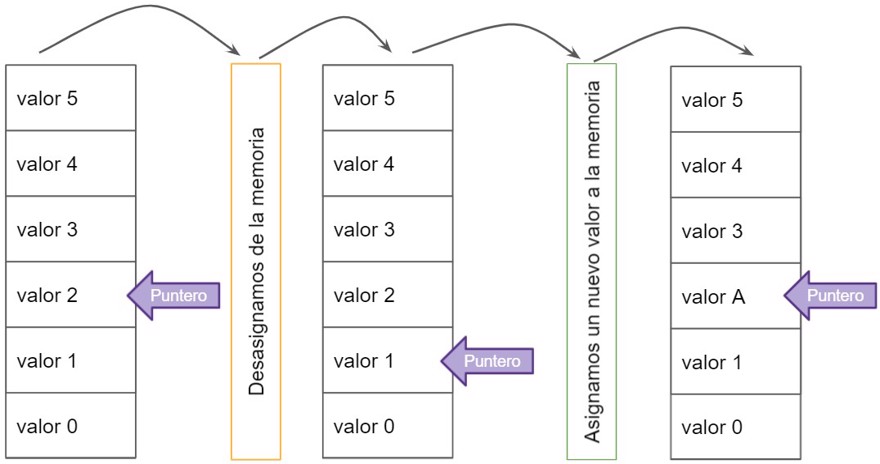
As we see in the image, when deallocating the value, what we do is move the pointer to the position with "valor 1", but the previous position still keeps its value.
Once we assign a new value, in this case "valor A", we overwrite it at the previous position.
One of the great benefits of using the stack for allocations is that it is very efficient and works great for example in local functions. When you define a function in your code, all variables go to the stack and when you exit the function, they are wiped out.
As a final note, in C# we have a 16-byte limit for structs (they go to the stack). This is because, since they're passed by value, the whole element must be copied, and with 16 bytes, it can be done with just a couple of processor instructions. If it were larger than that, you'd lose the stack's performance advantage, due to the cost of copying the entire element.
2.2 - What is the heap?
As we have seen, the stack has some restrictions, so we can't always use it. This is where the heap comes into play.
Heap is the memory we use for dynamic memory allocation.
And as its name suggests, we allocate (and deallocate) memory in a disorganized way, which may cause fragmentation.
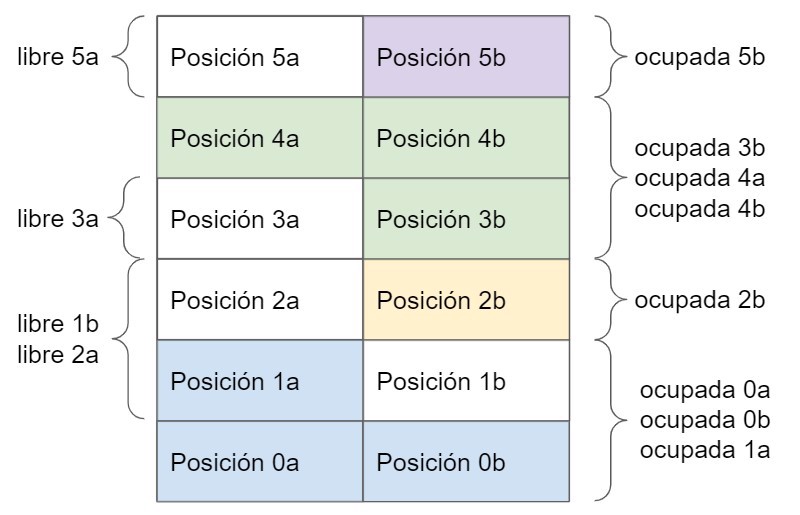
What do I mean by fragmentation?
As we can see, we have several blocks of allocated memory (blue, orange, green, purple colors) and several free blocks (white). If we wanted to store an object that takes up 3 blocks, we couldn't, as we don't have 3 consecutive free blocks.
Usually, we use the heap for all those objects whose lifespan goes beyond a function or a process.
Finally, we mentioned that the stack is cleaned up automatically when exiting the function. In the heap this is not the case , the developer has to clean up the heap. Luckily, C# knows, thanks to the extra 16 bytes stored per object, when an object in memory will no longer be used, and then the garbage collector goes through that memory and cleans up what's still allocated but not going to be used again.
3 - When to use struct, class or record
Now comes the big question: with all this information, when we're writing code, which data type should we use?
3.1 - When to use struct
We can create our type as a struct if it meets the following characteristics (all of them):
- The instance is small (16 bytes) and its lifetime is usually short, for example we only use it within a function.
- It's also common if it's going to be part of another object and never an independent "root" object.
- One of the main characteristics of value types: if it is going to be immutable.
- Finally, if it will not be constantly converted to a reference type (boxed).
If our type meets all these characteristics, then it should be a struct.
Otherwise, it should be a reference type.
3.2 - When to use record
Our type is going to be immutable.
Note: for me, the perfect example of a record is a DTO of our API. Since we will never want to change its content and at the same time it saves us from having to write a lot of code.
3.3 - When to use class
If our object does not comply with the previous properties (of structs or records), the type we should use is class.
There are a few more things to consider, for example records do not implement the IComparable interface or that structs do not support inheritance. But in 99% of cases, the guidelines above apply.
Conclusion
- In this post, we've seen what value types and reference types are, and their differences.
- We've seen the difference between memory located in the stack and memory located in the heap.
- Finally, we've seen when to use struct, when to use record, and when to use class in C#.
