Today I want to talk about what, for me, is the ideal architecture for an application.
Unlike other posts where I am completely objective, here we're going to look at my opinion, why I like it, and what benefits it brings or doesn't bring, since many of you ask which architecture I use.
Table of Contents
1 - What is Core-Driven Architecture?
Understand that I'm talking within the context of professional environments or large applications. If you just need to make a small script or a minor feature that does X, I wouldn't do it this way, write a script for that.
But let's get to the point. On this channel we've looked at different architectures, mvc, clean, vertical slice, or hexagonal. While I don't have a predefined preference, what I do is mix a little of everything so that I can work comfortably, and that's what matters in the end.
Surely this architecture resembles another by 90%, but the truth is there are so many it's not worth arguing about which one. What matters is not the name, I actually made it up while writing this post, but the concept itself.
2 - Separation of Concerns in Core-Driven Architecture
The principle I stick to most strictly is separation of concerns.
What I mean by this is that within each application I have different layers, and each layer has a clear responsibility.
It's a mix of clean, hexagonal, and layered architecture: we have a layer where business logic is the most important part (CA); then we use dependencies via interfaces (hexagonal's ports and adapters); as well as a separation between layers and a direction toward the inside, similar to layered architecture.
For example, in an API, we would have something like:
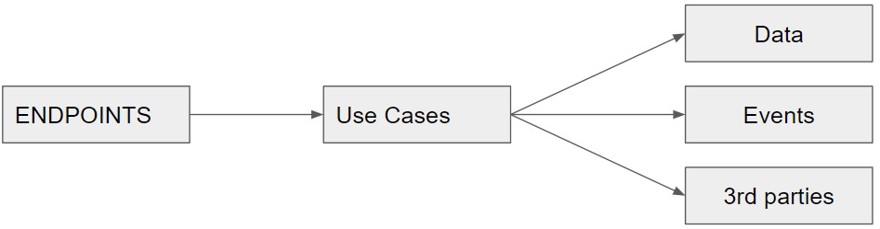
If you work with C#, you can use folders or projects within a solution. Personally, I don't care as long as things are separated and there's a clear division.
2.1 - Application Entry Point
As we can see, the endpoint is only acting as a proxy between the request and the use case we're about to execute. The endpoint's function is to route and check authorization. Process anything in the request pipeline, configure OpenAPI, in short, only elements related to being an API exist at this point.
This means that if instead of being an API, it's a consumer of distributed architectures, the only change is that we won't have an endpoint triggering the action, but a handler that reads an event, checks if we haven't already processed that event, etc.
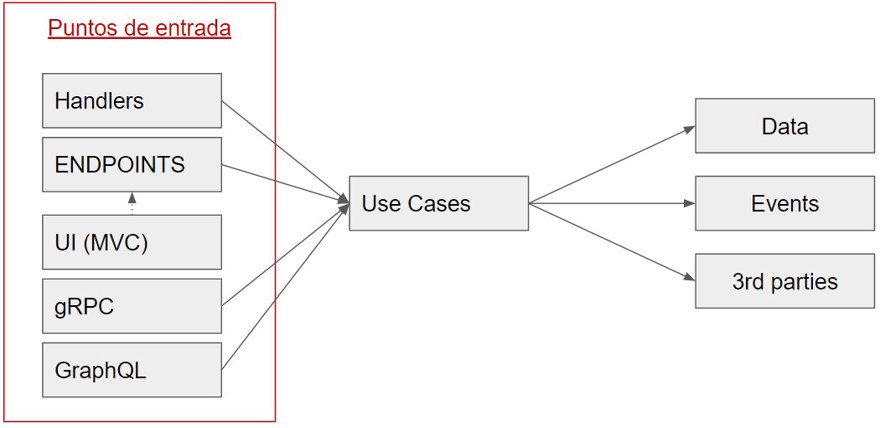
Exactly the same happens in the interface: if we use MVC, the interface might trigger the call to the proper controller.
The important thing is to know that this layer is the entry point from outside into our application and acts as such.
2.2 - Use Case Layer
The middle layer is the most important, because it's the one that contains the business logic and is truly what we should be testing. This layer performs all the necessary checks and actions required by your use case.
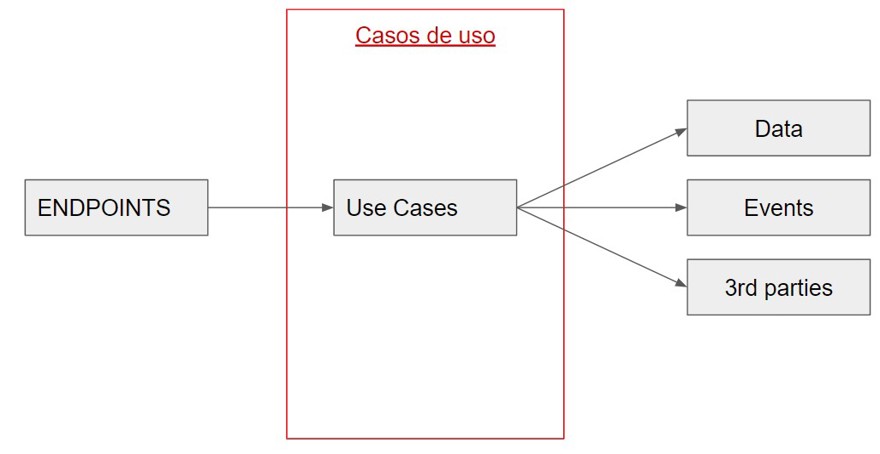
For example, if we're creating clients in the database, we verify all the data, insert it, and as a final step, publish an event indicating that an item has been created. All these actions happen within this use case.
For me, it's important that this layer implements the single responsibility principle. This means each use case performs a single action.
Executing an action doesn't refer only to validating or inserting into the database, it's about the entire set of business rules needed for something to happen. Which means, for creating a client, you'll have one use case; for updating a client, you'll have a different one. In C#, this translates into various classes instead of one massive class doing everything.
So, by nature of how you work, the API will comply with CQRS, separating reads from writes inside our application.
And each use case contains everything it needs to work. For example, if we use the database, we inject the database, be it the dbcontext, or the repository if using the repository pattern or unit of work. If after finishing the process we're going to send an event to notify that we've created an item, we also inject the interface that will launch these events:
public class AddVehicle(IDatabaseRepository databaseRepository,
IEventNotificator eventNotificator)
{
public async Task<Result<VehicleDto>> Execute(CreateVehicleRequest request)
{
VehicleEntity vehicleEntity = await databaseRepository.AddVehicle(request);
var dto = vehicleEntity.ToDto();
await eventNotificator.Notify(dto);
return dto;
}
}Here, I use the same logic as hexagonal architecture with ports and adapters.
This use case layer is where a lot of people use Clean Architecture and add a mediator pattern. If you read my post on Clean Architecture, you know my opinion about the mediator pattern, I personally don't use it because it adds little, especially when misused (handlers calling other handlers), so what I do is have, as I said, one class per use case or action, and then another class for each “group” that includes them.
public record class VehiclesUseCases(
AddVehicle AddVehicle,
GetVehicle GetVehicle);And while the code is more coupled, I don't see a problem because it's a microservice and there’s no drawback.
As a general rule, I don’t use interfaces in this layer, which means we inject concrete classes into the dependency injection container. The reason is simple: interfaces in this layer add no value.
2.3 - External Elements
Finally, the last layer is where I define all the external elements of the application. Here is where I find reasons to use async/await because we're communicating with the application's external elements.
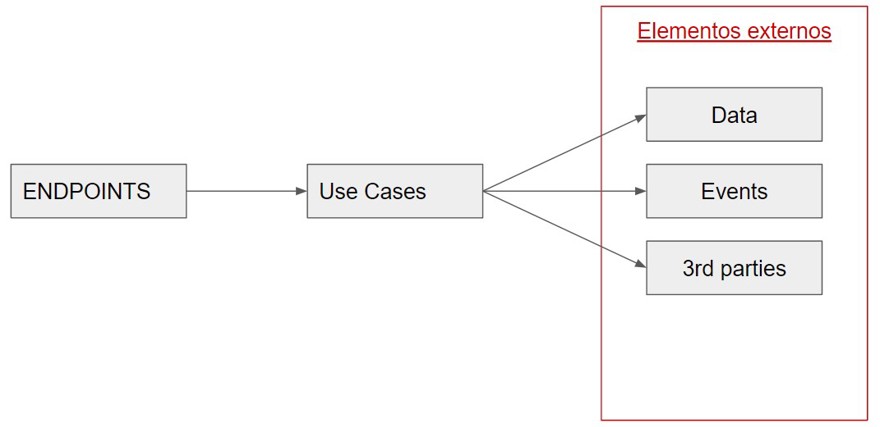
In my personal way of working, I usually divide this layer into different projects within a single solution for clearer separation. For example, I create a project called Data for everything that has to do with the database, whether you use the repository pattern or dbcontext, it’ll be placed in this project along with the database entities.
If I use RabbitMQ for event communication, all rabbitMQ configuration and its implementation will go in that specific project.
As you can imagine, all access to different parts of the infrastructure or external services goes here. You can use either projects or folders, it depends on how much you'll have, your personal preferences, or your organization's standard.
2.4 - Dependency Injection
This architecture heavily relies on dependency injection, as we'll be injecting all elements into the upper layers.
For example, I inject the use cases into the controller and inject the database into the use cases. So far, so normal. But what I also do is declare all the elements I need to inject in the project where they're defined.
This means that inside my use case project, I have a static class with a single public method called AddUseCases, and, in addition, I have a private method for each group of elements to insert. This is the result:
public static class UseCasesDependencyInjection
{
public static IServiceCollection AddUseCases(this IServiceCollection services)
=> services.AddVehicleUseCases();
private static IServiceCollection AddVehicleUseCases(this IServiceCollection services)
=> services.AddScoped<VehiclesUseCases>()
.AddScoped<AddVehicle>()
.AddScoped<GetVehicle>();
}
///this in program.cs
builder.Services
.AddUseCases()
.AddData()
.AddNotificator();Then, in the upper layer (API), we simply invoke this AddUseCases.
Something to keep in mind here: this setup is simplified to improve speed and ease when working with dependencies. Five years ago, when I started with the website, I created this library that I have on GitHub and nuget that lets you specify in the dependency project which modules you'll need and checks whether they're already injected; if not, it fails. The idea is good and works (at least up to NET5) but I don't think it's worth it anymore.
Though you could do something like
var serviceProvider = new ServiceCollection()
.ApplyModule(UseCases.DiModule)
.ApplyModule(Database.DiModule)
.BuildServiceProvider();
// in UseCases:
.AddScoped<UseCaseX>
.RequireModule(Database.DiModule);Now what I do is lean toward simplicity.
2.5 - Best Practices for Core-Driven Architecture
As a final point, I want to include certain preferences I have regarding how I build applications.
Personally, I've been using the Result<T> pattern for over 5 years, even before it became popular. The reason is that it lets me have an object with two states, success and failure, and then in the API, I can map to a ProblemDetails with the correct HTTP status code.
Unless the application is tiny, I always use "normal" controllers, not minimal APIs. The reason is that for making APIs compatible with OpenAPI, it's much better, we'll see a post on this soon.
Use cases will always return a DTO, which can safely be sent outside the application. You can use entities in the use cases, but never return an entity from a use case. Difference between DTO and entity. Lastly, I keep DTOs in a separate project so I can create a nuget package if needed.
Not all APIs need to be Backend For Frontend (BFF), understanding BFF as an API that receives a request and returns all the information. For example, we have our vehicles API, where we create vehicle properties like brand, doors, color, etc.
The number of vehicles in inventory is part of the inventory service, not the vehicles service. Therefore, if you want to show the number of available vehicles along with their name, for instance, on the UI, you have several options.
1 - Call the inventory API from inside the vehicle API to check how many are available
2 - Create a BFF app that aggregates information from both services (or use federated GraphQL)
3 - The interface performs both calls
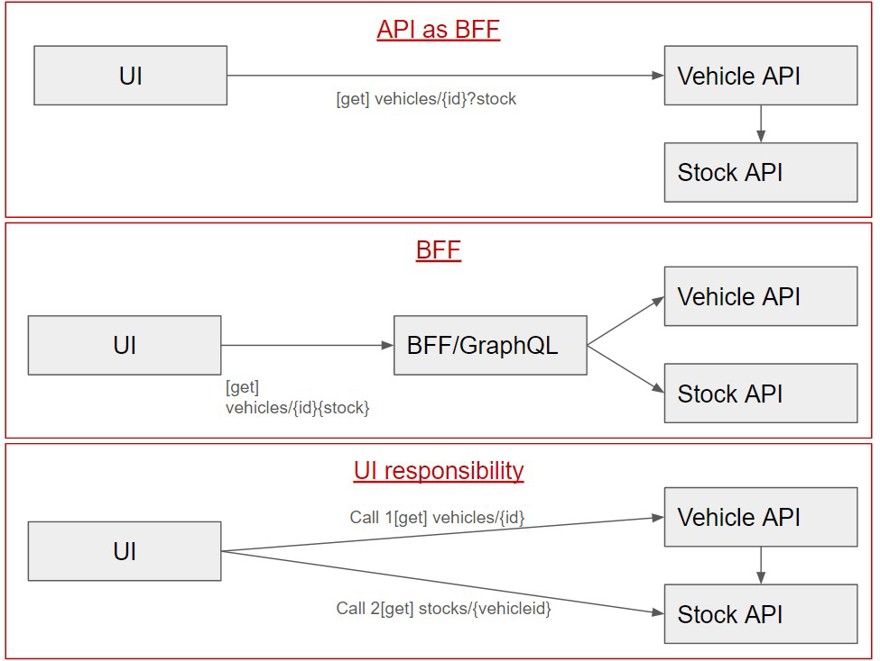
In my view, stock information isn't the domain of our vehicles API, so the first option shouldn't be valid. Between the second and third options, it depends on the user experience you want to deliver.
The use of CQRS, when we separate reads from writes, doesn't mean we can only query the database. What we do with the database is irrelevant. What matters is, to the consumer of our use case, if we say GetVehicle, we return a vehicle, not make a modification in the database. Common sense.
3 - Testing in Core-Driven Architecture
I know you might be thinking that tests aren't part of an application's architecture or whatever you want.
But in reality, tests are necessary, so I wanted to include a small section. Ideally, we should do all kinds of tests and have everything covered, etc. This isn't realistic and isn't always possible. But because of how we've designed the application, it's very easy to have tests for our use cases, which are the core of our app.
As you could see throughout this post, each use case has a single entry point, which means we'll only have one method to test. This doesn't mean we only need a single test, but rather one test for every possible output of our use case. If you're using exceptions for validation, you should validate those exceptions. If you use Result<T>, you must validate each possibility.
public class AddVehicleTests
{
private class TestState
{
public Mock<IDatabaseRepository> DatabaseRepository { get; set; }
public AddVehicle Subject { get; set; }
public Mock<IEventNotificator> EventNotificator { get; set; }
public TestState()
{
DatabaseRepository = new Mock<IDatabaseRepository>();
EventNotificator = new Mock<IEventNotificator>();
Subject = new AddVehicle(DatabaseRepository.Object, EventNotificator.Object);
}
}
[Fact]
public async Task WhenVehicleRequestHasCorrectData_thenInserted()
{
TestState state = new();
string make = "opel";
string name = "vehicle1";
int id = 1;
state.DatabaseRepository.Setup(x => x
.AddVehicle(It.IsAny<CreateVehicleRequest>()))
.ReturnsAsync(new VehicleEntity() { Id = id, Make = make, Name = name });
var result = await state.Subject
.Execute(new CreateVehicleRequest() { Make = make, Name = name });
Assert.True(result.Success);
Assert.Equal(make, result.Value.Make);
Assert.Equal(id, result.Value.Id);
Assert.Equal(name, result.Value.Name);
state.EventNotificator.Verify(a =>
a.Notify(result.Value), Times.Once);
}
}
Although it's important to test every output, the most important thing is to test the happy path, in short, the sequence your code will follow when everything goes right.
As you can see, I use Moq as the mocking library, although there are other alternatives.
I also usually create a class that acts as a "base" for the happy path and contains the dependencies that are going to be used.
And then each test describes in the name what it does and what it validates.
