In this post, we will continue with the Distribt course, and I say continuation because CQRS, our previous post, and Event Sourcing are often closely related, although not always.
Here, we will see in detail what Event Sourcing is and how to implement it in C#.
- Note: Event Sourcing and DDD (domain driven design) are often seen together since it's very common to use
aggregatesin Event Sourcing, which are part of the DDD pattern.
Index
Of course, the code is always available on GitHub in the Distribt library.
1 - Current situation
Before starting this new post, let's see how our current system works. We have a database, which we update every time we change a value.
In our case, we have the endpoints addproduct and updateproductdetails/{id}, which allow us to create and modify a product.
So, if we create a product named "item1" and with the description "description1" and then update it, we will have the following scenario:
We have a table with one record and when we update it, we overwrite the existing value, so the old value disappears from the database itself.
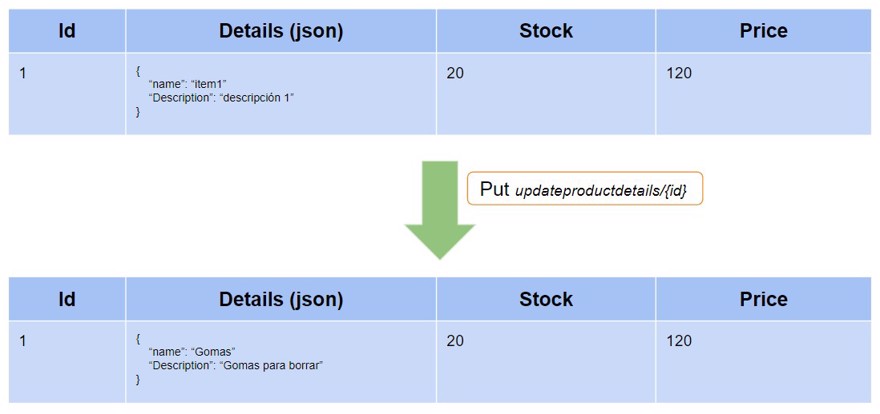
And this works, this is a normal update in the database. This is what's called the current state.
- It's common to have logs, either in the database or in files, that indicate changes, or even a copy of the table every time something changes.
2 - What is Event Sourcing
With event sourcing, what we do is have a database that will contain all the events that occur in our system.
By events we mean user actions. And when you combine them all, you reach the current state.
For example, if we have multiple events, the first one where the product is created, and then its updates.
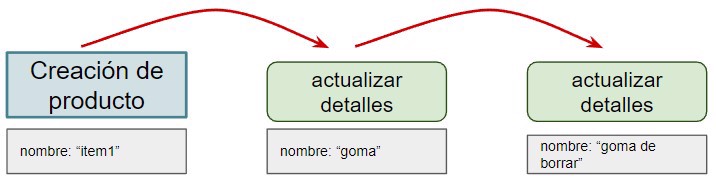
With this, we also reach the current state.
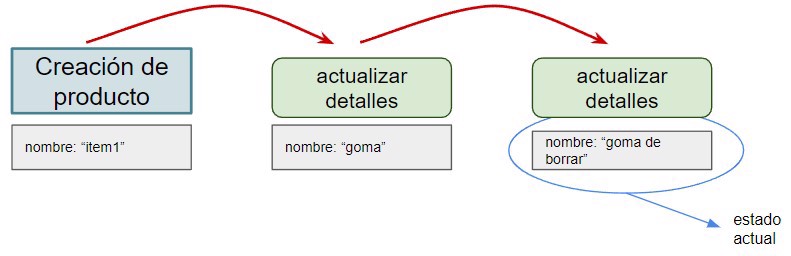
Technically, we could store only the event in the database, but it might be a good idea to also store other data such as the date, or as we’ll see in the implementation, the order in which these events happen.
2.1 - Importance of event naming in event sourcing
I want to give special mention to naming your events. Just like with variables when programming, event names must be self-explanatory and clear.
Imagine we have our Orders microservice (Distribt.Orders). We could have one event called "OrderUpdated" or we could have several event types: one indicating a sale was generated, "OrderCreated", another showing that the order was paid, "OrderPaid", another for when the order was shipped, "OrderDispatched", and so on. The more specific our event names, the clearer everything becomes.
Also, as we see, the first example is "OrderUpdated", which usually means sending all the information in each event, but if we specify each event type, we can send only the necessary data.
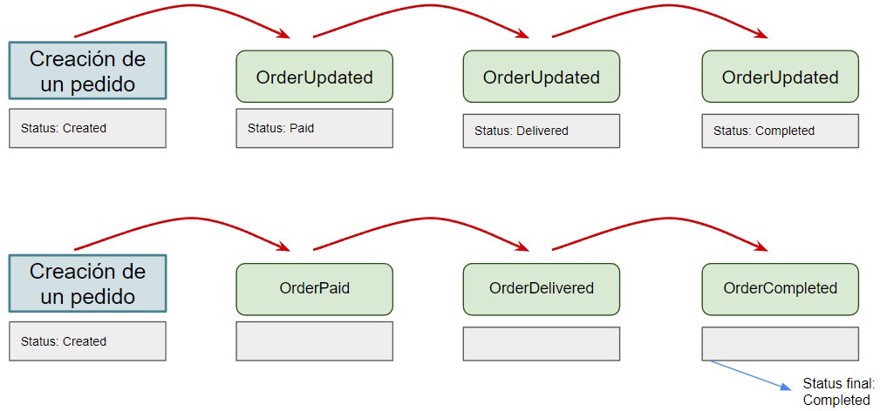
I'm speaking from experience here because I once joined a project where there were over 20 events called just "created" or "updated", the namespace gave you a hint, but it wasn't intuitive at all.
It’s also important to keep to a minimum the amount of data we store. For example, if we’re just changing the order status, there’s no reason to send the items or the shipping address.
2.2 - Source of reliability in Event Sourcing
With this change, what we achieve is using our events as actions that have occurred in the system. That’s why events are called the "source of truth", since they contain everything that has happened in the system for a specific ID.
We use what’s called an eventStore to store events, you can use any type of database, but document-based databases like MongoDB, DocumentDB, EventStoreDB, and similar are common.
In this example, we use MongoDb with a collection named "events".
If you’re going to use Event Sourcing with CQRS, remember this is only for the write database, and we’ll use it to keep a record of the state.
2.3 - Aggregating events
As you've seen, we are creating events strongly focused on a product. These events are all "linked" together into what we call an aggregate. When using Event Sourcing and we want to read the current state of an object, in this case, a product, we need to read all the elements from the eventStore that reference that object and use them to build the aggregate with the final data.
You might wonder if this is bad for the database and if it affects performance. And obviously, yes, you're loading more data than if you had just one row per record.
But even so, in practice, the difference is minimal. If it takes more time than is acceptable, you can always use what are called snapshots of the data, i.e., from day X, the new current state for each aggregate is the “new first event” and you can clean out all earlier information.
You'd lose the history (you can always store it in a cold storage), but you’d gain speed. Personally, I’ve worked with Event Sourcing for several years and have never run into this problem.
There’s no one-size-fits-all solution; every company/team has its own priorities that shape the final solution.
3 - When to use the event sourcing pattern
With all this added complexity, you may wonder whether it’s worth using this pattern. I'll name its benefits, and then you'll have to decide if you want to implement it. Like everything, there are scenarios where it’s very beneficial, and others where it's not as much, and it’s often seen along with DDD.
So we'll use it whenever we can take advantage of it with the following benefits.
3.1 - Benefits of using event sourcing
- Observability: Since you have all the events, you can identify why a record has a certain value, where, when, and why it was changed, giving us great confidence that the information is completely reliable.
- Fault tolerance: To me, this is Event Sourcing’s strongest advantage. By keeping a record of all events in our system, we can check that the information is correct in the read store. We can also experiment in the read store, and if something goes wrong, we can just replay all the events again.
- Asynchronous communication: Using Event Sourcing pretty much forces you to build your client APIs with this design. This can bring you many benefits if you implement good practices.
- Auditing/Logs: While its main purpose isn't just to audit system actions, it can be used perfectly for that. It’s a better alternative than just having a table for logs.
4 - Implementing Event Sourcing in C#
To further expand this project's content and show that different patterns can live together in the same system, to demonstrate Event Sourcing, we’ll work on the Distribt.Orders microservice.
So far, all we've got is an API that returns dummy data, and that’s what we’ll change. The first thing we need to do is create the connection between our code and the database.
4.1 - Persisting an aggregate using MongoDb
The code is pretty long, so I'll focus on the key parts. All the Event Sourcing logic is in the Distribt.Shared.EventSourcing project, which is linked to MongoBD. This is a personal choice; we could have used another database or eventStore to work with the events.
To use this library, from the client app you must call webappBuilder.Services.AddEventSourcing(webappBuilder.Configuration);
When you provide this service, interface IEventStore will be injected into the dependency container, and this is used in the aggregate to communicate with MongoDb
A - The Aggregate
The aggregate is the type we’ll use to hold the logic of our object.
This Aggregate type (also called AggregateRoot) contains the list of events, the Id, and the current "version", i.e., the number of events.
Finally, there’s some logic to distinguish whether a change is being loaded from the DB or is a new change to be stored
namespace Distribt.Shared.EventSourcing;
public class Aggregate
{
private List<AggregateChange> _changes = new List<AggregateChange>();
public Guid Id { get; internal set; }
private string AggregateType => GetType().Name;
public int Version { get; set; } = 0;
/// <summary>
/// this flag is used to identify when an event is being loaded from the DB
/// or when the event is being created as new
/// </summary>
private bool ReadingFromHistory { get; set; } = false;
protected Aggregate(Guid id)
{
Id = id;
}
internal void Initialize(Guid id)
{
Id = id;
_changes = new List<AggregateChange>();
}
public List<AggregateChange> GetUncommittedChanges()
{
return _changes.Where(a=>a.IsNew).ToList();
}
public void MarkChangesAsCommitted()
{
_changes.Clear();
}
protected void ApplyChange<T>(T eventObject)
{
if (eventObject == null)
throw new ArgumentException("you cannot pass a null object into the aggregate");
Version++;
AggregateChange change = new AggregateChange(
eventObject,
Id,
eventObject.GetType(),
$"{Id}:{Version}",
Version,
ReadingFromHistory != true
);
_changes.Add(change);
}
public void LoadFromHistory(IList<AggregateChange> history)
{
if (!history.Any())
{
return;
}
ReadingFromHistory = true;
foreach (var e in history)
{
ApplyChanges(e.Content);
}
ReadingFromHistory = false;
Version = history.Last().Version;
void ApplyChanges<T>(T eventObject)
{
this.AsDynamic()!.Apply(eventObject);
}
}
}
When you create your domain object, you must implement Aggregate for it to function as an aggregate, and also use the IApply<T> interface for each event that the object will handle
public class OrderDetails : Aggregate, IApply<OrderCreated>, IApply<OrderPaid>, IApply<OrderDispatched>, IApply<OrderCompleted>
{
//Code
}
As seen in the example, we have the OrderDetails aggregate, and then an IApply<T> for each event shown above.
B - Saving the Aggregate in MongoDb
When we store data we do it in a special way, as we don’t just store the event, but also information to identify and group it with others.
That information is what you see in the AggregateChange and AggregateChangeDto types, which contain:
Content: for the object’s content (includes the event).AggregateId: The aggregate ID, in this case, the Order ID.AggregateType: to know what type it is.Version: The aggregate’s version (each new event adds 1)TransactionId: combination between the Id and the version
Since this is the information we’ll store, we create an index in MongoDb with the Id, type, and version (the library does this automatically).
Inside the library itself there is a class called AggregateRepository<TAggregate> that your repository should implement.
The AggregateRepository<TAggregate> type has two methods
GetByIdAsync: Reads from the database by ID and correctly builds the Aggregate in order.SaveAsync: Saves new events to the database.
This lets you either inject IAggregateRepository<TAggregate> into your services, or create your own repository and implement AggregateRepository<TAggregate> (my recommended option):
public interface IOrderRepository
{
Task<OrderDetails> GetById(Guid id, CancellationToken cancellationToken = default(CancellationToken));
Task Save(OrderDetails orderDetails, CancellationToken cancellationToken = default(CancellationToken));
}
public class OrderRepository : AggregateRepository<OrderDetails>, IOrderRepository
{
public OrderRepository(IEventStore eventStore) : base(eventStore)
{
}
public async Task<OrderDetails> GetById(Guid id, CancellationToken cancellationToken = default(CancellationToken))
=> await GetByIdAsync(id, cancellationToken);
public async Task Save(OrderDetails orderDetails, CancellationToken cancellationToken = default(CancellationToken))
=> await SaveAsync(orderDetails, cancellationToken);
}As you can see, the implementation is very simple.
Note: The current version has a bug/feature, and events must be registered manually in the BsonSerializer during app startup.
public static class MongoMapping
{
public static void RegisterClasses()
{
//#22 find a way to register the classes automatically or avoid the registration
BsonClassMap.RegisterClassMap<OrderCreated>();
BsonClassMap.RegisterClassMap<OrderPaid>();
BsonClassMap.RegisterClassMap<OrderDispatched>();
}
}If you can help find the problem, I'd be grateful, thanks.
Finally, you need to specify, in the configuration file (using appsettings), to which database and collection we will connect, with the following section.
"EventSourcing": {
"DatabaseName" : "distribt",
"CollectionName" : "EventsOrders"
},
4.2 - Creating an Aggregate
Now let's go to the logic of our type, or how our type will change depending on the event.
Our use case is when we create an order, and its possible modifications, so we create the OrderDetails type and include the information our Order will contain.
Of course, we specify Aggregate and will need to have a constructor with a unique Id.
With this, all we get is an object with a default value and an Id, so now we need to start applying the events that can happen to our object.
The first event is the creation of the object:
public class OrderDetails : Aggregate, IApply<OrderCreated>
{
public DeliveryDetails Delivery { get; private set; } = default!;
public PaymentInformation PaymentInformation { get; private set; } = default!;
public List<ProductQuantity> Products { get; private set; } = new List<ProductQuantity>();
public OrderStatus Status { get; private set; }
public OrderDetails(Guid id) : base(id)
{
}
public void Apply(OrderCreated ev)
{
Delivery = ev.Delivery;
PaymentInformation = ev.PaymentInformation;
Products = ev.Products;
Status = OrderStatus.Created;
ApplyChange(ev);
}
}
As you can see, by implementing the interface, we create an Apply method that takes the event. Inside the method, we modify the object as needed and call ApplyChange, which stores the event as a new event, so when we save the aggregate via AggregateRepository it will detect this as a new event and save it.
Now we have to repeat this for the rest of the events
public class OrderDetails : Aggregate, IApply<OrderCreated>, IApply<OrderPaid>, IApply<OrderDispatched>, IApply<OrderCompleted>
{
public DeliveryDetails Delivery { get; private set; } = default!;
public PaymentInformation PaymentInformation { get; private set; } = default!;
public List<ProductQuantity> Products { get; private set; } = new List<ProductQuantity>();
public OrderStatus Status { get; private set; }
public OrderDetails(Guid id) : base(id)
{
}
public void Apply(OrderCreated ev)
{
Delivery = ev.Delivery;
PaymentInformation = ev.PaymentInformation;
Products = ev.Products;
Status = OrderStatus.Created;
ApplyChange(ev);
}
public void Apply(OrderPaid ev)
{
Status = OrderStatus.Paid;
ApplyChange(ev);
}
public void Apply(OrderDispatched ev)
{
Status = OrderStatus.Dispatched;
ApplyChange(ev);
}
public void Apply(OrderCompleted ev)
{
Status = OrderStatus.Completed;
ApplyChange(ev);
}
}
4.3 - Creating use cases with Event Sourcing
To keep the post simple I won't specify them all, just the one for creating the order and for marking it as paid, but all follow the same logic.
- Note: In the code, all use cases are specified.
First, we change the endpoint so that, instead of returning random info, it calls the service we created and returns real data:
[HttpPost("create")]
public async Task<ActionResult<Guid>> CreateOrder(CreateOrderRequest createOrderRequest,
CancellationToken cancellationToken = default(CancellationToken))
{
OrderDto orderDto = new OrderDto(Guid.NewGuid(), createOrder.orderAddress, createOrder.PersonalDetails,
createOrder.Products);
await _domainMessagePublisher.Publish(orderDto, routingKey: "order");
return new AcceptedResult($"getorderstatus/{orderDto.orderId}", orderDto.orderId);
}
[ApiController]
[Route("[controller]")]
public class OrderController
{
private readonly ICreateOrderService _createOrderService;
[HttpPost("create")]
public async Task<ActionResult<Guid>> CreateOrder(CreateOrderRequest createOrderRequest,
CancellationToken cancellationToken = default(CancellationToken))
{
Guid orderId = await _createOrderService.Execute(createOrderRequest, cancellationToken);
return new AcceptedResult($"getorderstatus/{orderId}", orderId);
}
}And now we create our OrderService. As you see in the endpoint, besides storing the data in the database, it also generates a domain message.
In the logic, we create a new aggregate through OrderDetails and apply a change, in this case OrderCreated with the .Apply() method, and then save it in the repository.
- Note: for now, the domain event is being published, but if we’re not using CQRS, it would probably have to be changed to an integration message.
4.3.1 - Adding a new event
Once we have the aggregate created and saved (you can check in the database), let's create another event, in this case to indicate that it's paid.
Here, we create the OrderPaidService use case; we just need to apply the OrderPaid event and save:
public interface IOrderPaidService
{
Task<bool> Execute(Guid orderId, CancellationToken cancellationToken = default(CancellationToken));
}
public class OrderPaidService : IOrderPaidService
{
private readonly IOrderRepository _orderRepository;
public OrderPaidService(IOrderRepository orderRepository)
{
_orderRepository = orderRepository;
}
public async Task<bool> Execute(Guid orderId, CancellationToken cancellationToken = default(CancellationToken))
{
OrderDetails orderDetails = await _orderRepository.GetById(orderId, cancellationToken);
orderDetails.Apply(new OrderPaid());
await _orderRepository.Save(orderDetails, cancellationToken);
return true;
}
}If we go to the database now, we can see there are only two events stored.
We also see that these events only contain the data to be changed, not the entire object. In the case of OrderPaid, there's no data, since the event itself changes the state.

And if we read the order via GetOrder, we see that the information is correct:
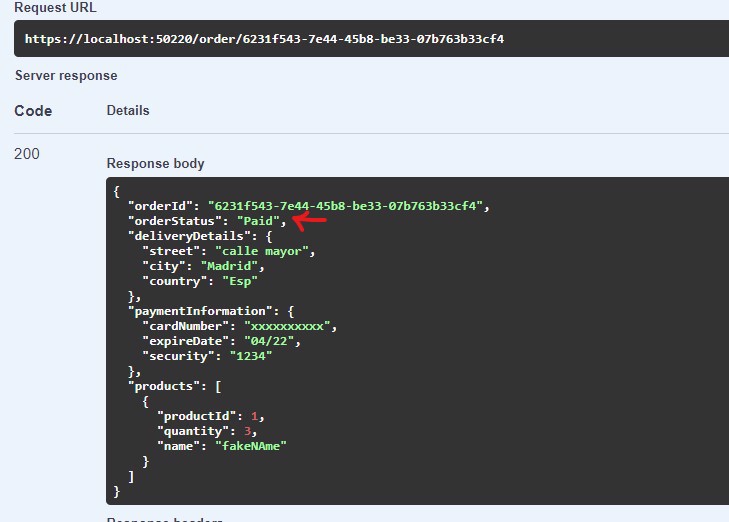
5 - Event sourcing vs Event driven
Finally, don't confuse event sourcing, which is about maintaining a state or the history of events, with event driven, which is about using events to communicate with other parts of the system, either internally, with domain events, or externally, with integration events.
Conclusion
In this post we have seen what Event Sourcing is
What is the difference between event sourcing and event driven
How to apply Event Sourcing to our code
How to implement Event Sourcing with .NET and MongoDb
