For over a decade, most of us have not worked with local files; we do so through the cloud to avoid losing our work if the computer breaks. Have you ever wondered how these kinds of systems work?
In this video, we’ll see how file systems like Google Drive or Dropbox operate.
Table of contents
As I always say in these videos, there is not a single valid solution; there are several, and the important thing is to understand the process and how it works so you can discuss aspects in interviews.
1 - Requirements for an online file system
For our scenario, the basic functional requirements are:
- Upload files.
- Download files.
- Share files.
- Propagate file changes to all clients.
This is basic functionality for a file sharing system, where you have an app running on your machine, basically what Google Drive or Dropbox do.
Additionally, our system must have the following features, which are the non-functional requirements:
- The application should always be available (99.99% uptime).
- Support for large files.
- Low latency.
- The application should be able to scale.
NOTE: Real-time collaboration won’t be covered in this post as that feature is a design topic on its own.
2 - Working with large files
One of the most important parts of how these applications work is understanding that files are not transmitted as a whole over the network. Let me explain: if you have a text document, with images, etc., that’s 100MB in size and you make a small change, you’re not going to send the whole file to the server to replace it, as that would mean sending those 100MB to all clients every time you update something.
To avoid this situation, what is done is to split the file into what is called chunks, blocks of a certain size, and only synchronize the chunks that have changed.
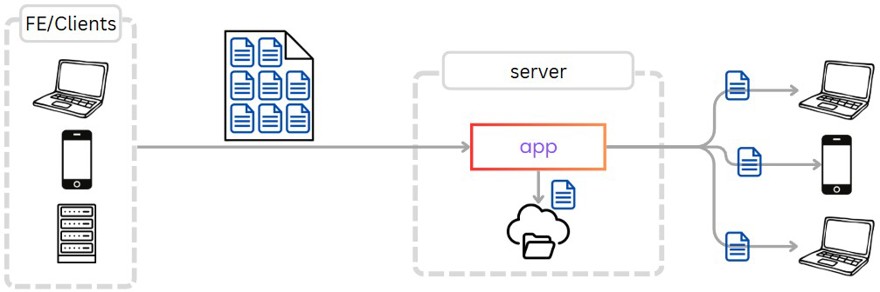
As you can imagine, this adds complexity when designing the client applications, as they have to figure out the difference between what was there before and what’s there now to synchronize files properly.
Likewise, we need to maintain the information about the chunks in the system database.
This database should contain the file’s ID as well as each of its chunks, which would be its hash (I’ve simplified for the example) and their location in the file system we use.
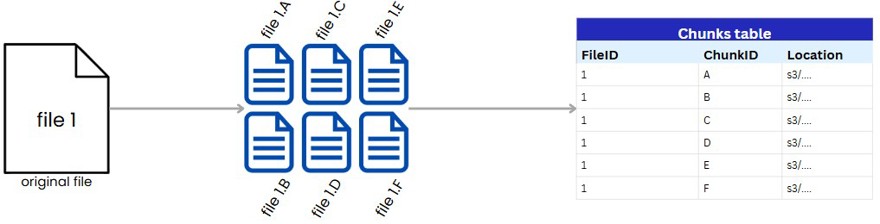
NOTE: If you wanted to add versioning, this is where you can add it, since every time you sync a chunk you can assign a version, and simply indicate it in the table. Or you could even have a table row per version with all the chunks inside. The idea should be clear.
3 - System entities
I know I’ve already mentioned one of the entities our system will include in the previous point, but I thought it was crucial to separate that section to understand how these types of applications work.
With that in mind, we have several primary entities:
- File: which later will be split into chunks, but we still need the file as such.
- File metadata: contains information such as the user, file name, last modified date, etc.
- User: Users in our system.
- Devices: We’re designing dropbox/google drive, which means we have applications both on PC and mobile, etc. We can store the machine ID, which user it’s linked to, and most importantly, the date of last sync.
- Sharing: a table (I am terrible at names) where we indicate which users have access to other files. You can go further and even add a team, which would work similarly to google workspace, where X users are in a team and can share files within that team.
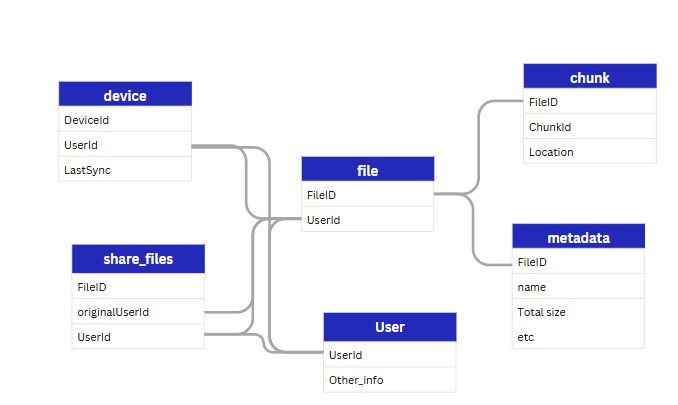
NOTE: Metadata and file can be combined into a single table.
4 - Cloud file system architecture design
Let’s start with the uploading part; earlier we saw that we need to split files, and when downloading we need to reassemble them.
To split files, there’s no other way but to do it on the client application. Thus, the client must be able to receive the file, split it, and upload the new chunks to the server. So the app itself has three sections:
A section that monitors the files we have; this works both for local files and files on the remote server, as we always want them synchronized.
To identify which local files have been modified, we have to use specific functions from the operating system in use. For those updated on the server side, we’ll see more on that later.
A section that is responsible for splitting and joining files.
And another section responsible for synchronizing files, to make sure we always have the latest version of each file.
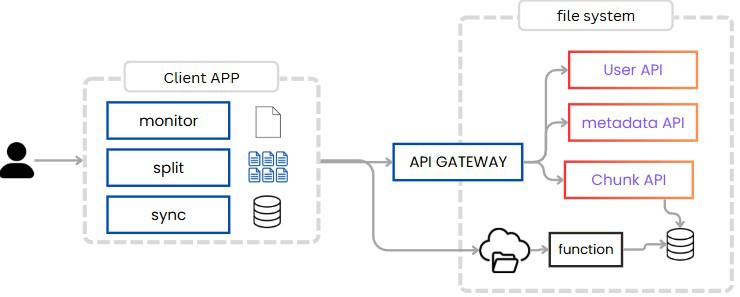
As we can see, we maintain information about what we’re doing locally, which means we can pause uploads and complete them later. The reason this is possible is because we have the files split into chunks.
Similarly, when uploading files, we don’t upload them through our application, but we send a request from the client app to the web app, indicating that we have to upload a chunk. This call goes through the API Gateway to our chunk service.
The chunk service is responsible for storing the state of the process in the database. It receives a request like the following:
//request
{
id: 1,
name: "file1"
size_in_kb: 100000,
status: in_progress,
chunks:[
{
id: 1_A,
},
{
id: 1_B,
},
{
id: 1_C,
},
]
}
->
//response
{
chunks:[
{
id: 1_A,
location: s3....
},
{
id: 1_B,
location: s3....
},
{
id: 1_C,
location: s3....
},
]
}Here we can see that it contains the file’s metadata and some information such as the chunks.
For each of those chunks, the app responds with a link, which is a direct link to the storage service. If we’re using AWS S3, for example, it’s a direct S3 link, known as a pre-signed URL, which means the file itself doesn’t have to go through our system.
This same functionality exists in AWS, Azure, GCP, etc., and the URL provided has a limited lifetime, e.g., one hour.
Each time we upload a complete chunk, we have to notify the chunk API that this file has been uploaded. There are two options: the first is to make a call from the client app to indicate the chunk has been uploaded. The second is to use S3 events (I guess this is also possible with Azure/GCP/etc.), which will notify us when the element has been uploaded, so we can have a queue or a cloud function listening for these events.
Of course, if you’re in an interview you have to say that in front of each of these services there’s a load balancer and multiple instances.
If you’re not familiar with these terms or their importance, I recommend you read my book Building Distributed Systems.
Also, for each chunk we generate an event where the final objective of said event is to notify all clients that a file or chunk is available. Of course, if the file doesn’t have all the chunks available yet there’s no reason to notify, but this action only happens during the first upload.
To do this, we need to check our metadata system to ensure all chunks are uploaded and, with the permissions system, to know which users have access to that file, since they should also be able to read it.
This is done with a native function we can call chunk post-processor.
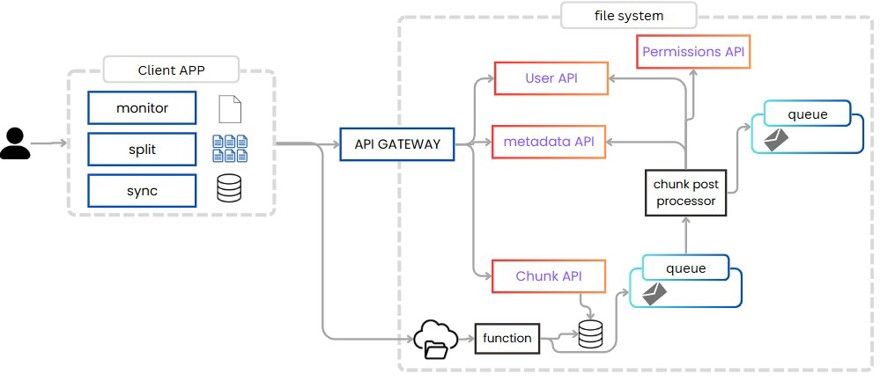
And here we have several options to implement it.
One is to generate an event and listen to it from a notification system, which communicates with the client application and asks the server for the chunks and files it’s missing.
My idea here would be to send a notification to the application and from there it refreshes the data; this can be done using Websockets or SSE, which means having an open connection with each client when a notification happens.
Alternatively, we can do polling from the application: every minute we send a request to the server asking if there’s any new chunk since the last time we synced with this device. It’s a bit slower but much simpler than websockets, and it works.
Or as a final option, we could do long polling, meaning the user’s request stays open until it receives new data or times out.
All three options are valid and correct. The important thing is to be able to show the interviewer the pros and cons of the one you choose compared to the others.
4.1 - Application flow
With this, we have completed the design. Now we just need to explain the process:
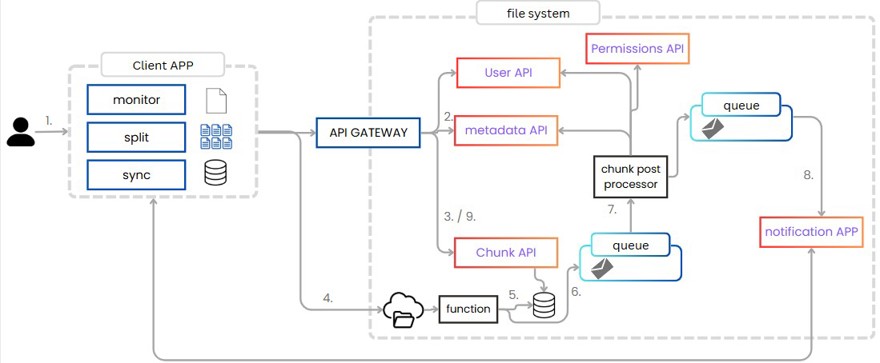
1 - The user adds a file in the application. Several actions take place here; first, the file is split into chunks, and from there we synchronize with "the cloud".
2 - If the file is new, we add its information to metadata; if it isn’t, we validate that the user has permissions (if this has been implemented), returning the file’s ID, which will be used to identify the chunks.
3 - Each chunk works individually; it is added to the database with state ‘in process’ and we return a pre-signed URL.
4 - From the client, we use the pre-signed URL to upload the file.
5 - Each time a file is uploaded, we have a native function that updates the database with the chunk’s information.
6 - Each time a chunk is uploaded, we need to propagate the information, for which we generate an event.
7 - We read that event with a consumer, which reads all file information, including which users have permissions for it, and for each, generates an event.
8 - That event is sent to an app that has the users’ clients connected and tells them that there’s a new version of a file.
9 - The app asks the API for all links to new chunks since the last sync. It downloads them and updates the files accordingly.
4.2 - Advanced design details in a file system
Now I’ll mention some key elements in these systems that you have to bring up in interviews while you design them.
Chunk size
Deciding how big each chunk should be isn’t easy, Dropbox, for example, uses 4MB, but in an interview you can discuss pros and cons of having 1MB, or even 10MB chunks.
CDN
Sometimes a file is accessed by thousands of people in different parts of the world, in which case you can use a CDN and have copies of these popular files in the CDN. This way, even if the primary user is in Europe, access from anywhere in the world will be very fast. Note that to access CDN data you must also be logged in and have the right permissions.
Security
The app should encrypt chunks in transit, both when uploading and downloading files. For that, you can indicate that they use TLS 1.3 and once stored, apply AES-256 + KMS (at least on AWS). If the data is extremely sensitive, you might consider client-side encryption, but you may lose some extra functionalities like previews.
Conflicts
In this post, we haven’t tackled what happens when two users have write access to the same file. But have you wondered what if two people modify a file at the same time? For that we have to choose what to do: whether the last write wins or use a CRDT strategy (which is more costly to implement).
In fact, there's a third option, which is optimistic locking with manual merge: the app notifies about the conflict and the user decides what to do. If I’m not mistaken, that’s what Dropbox does.
Versions
As previously mentioned, we could have versioning if we version the chunks. That way, we can retrieve each file in different versions. Always with a hash for each version (what I called chunkid) so that we can avoid chunk duplication.
Mastering all these terms, understanding them, and of course knowing how to explain them can make all the difference in a technical interview.
