Have you ever wondered what goes on behind the scenes of systems for shortening URLs?
In this post we'll look at the architecture of such systems. This is a very common question in design interviews, and this one in particular could be classified as easy level.
Table of Contents
1 - Requirements for a URL shortener system
The first thing we should think about are the requirements we need to have a complete application or system.
These types of applications have one main functionality:
When you click on a short URL, it redirects you to a completely different one.
Along with this main functionality, there are two main characteristics:
- This URL must be short, after all, that's the point of our application.
- The application must always be available (99.9999% uptime) and fast (<200 ms).
Those are the main requirements, but there are others that are not as obvious at first glance. In an interview it’s always useful to mention several points, even though, in most cases, you won’t be required to go further:
- No two URLs can be the same.
- Detect malicious URLs.
- Custom alias: instead of an auto-generated URL, the user can define an alias, even if it’s longer.
2 - API Design
Once we have the requirements, we’ll move on to the API itself. In this case, we should mention/define or draw (depending on where you're being interviewed) all the key endpoints of our API. Here we have four, so let's define all of them.
POST /urls: create a new resource (a resource, in this case, is a URL)GET /{short-url}: Read a resource and redirect to the original URLPUT /urls: modify a resourceDELETE /{short-url}: Delete a resource
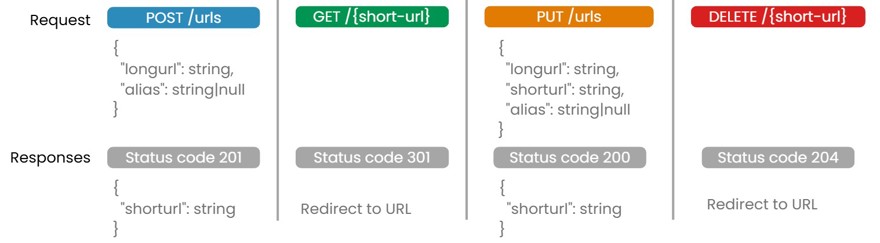
Things to consider with this design:
For PUT /urls, you could debate what kind of modifications you’d want to allow, whether it would be possible to modify the short URL with a new alias, or if this action would simply mean creating a new URL. Or even discuss whether a URL should be immutable once created.
Remember that there’s never a single correct or incorrect solution. What really matters is your ability to debate the different options.
2.1 - HTTP status code for a redirect
Within our GET method we will redirect to another URL, so we must indicate the correct status code in our application's response. We have two options for this.
- Status code 301 for a permanent redirect. In our case, as long as the URL is in the system, we’ll redirect, which means we should return a 301.
- Status code 302 for a temporary redirect. In other systems, you might have a temporary redirect. In our current system, we could modify it so that it has an expiration date (DateTime field) for when the URL should redirect, in which case we'd use 302. This point is important to mention if you’re in an interview.
One thing to keep in mind is that when you use 301, the browser caches the redirect itself. This means that, even if the user clicks the link, the request will never reach our system. That may not be ideal in a real-world production environment since often these links are tied to analytics, usage statistics, region, etc.
If you like this format, you’ll also enjoy my book Construyendo Sistemas Distribuidos, where we discuss many of the topics from this post in depth.
3 - Architecture Design for a URL Shortener
The most important thing when designing is to start with the most basic use case, and from there evolve the solution. That way, especially if you're in an interview, you have time to think and interact with your interviewer as you go.
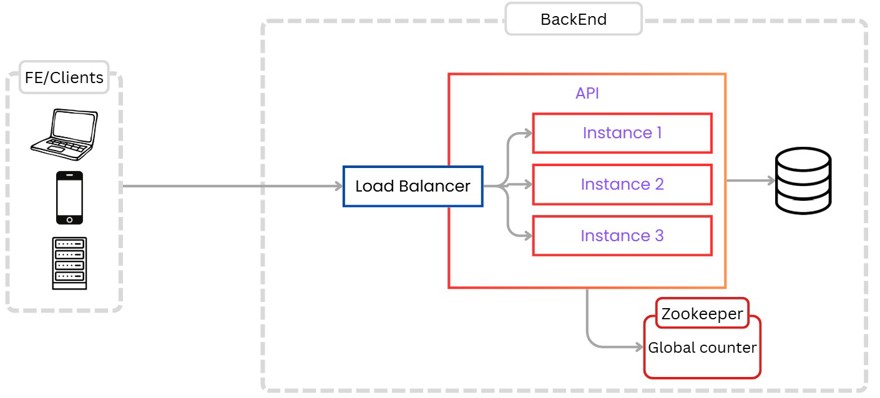
For our first requirement, we need a user to be able to create links, in addition of course to reading, updating, and deleting. For this we create a simple solution.
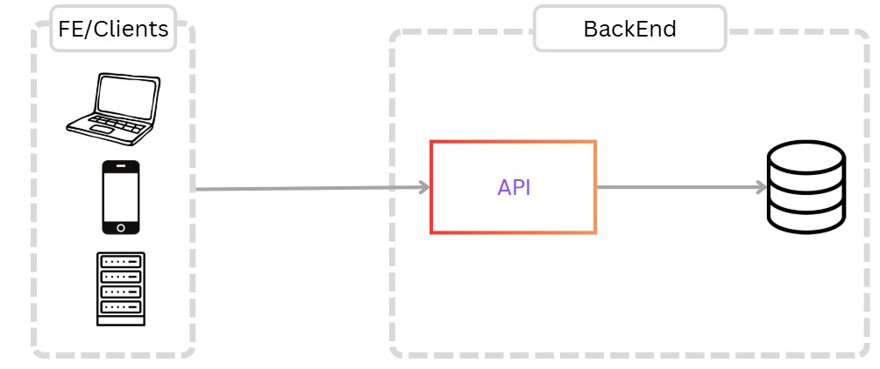
This solution has the following entities:
- Clients, either the UI or an external client, who call our API.
- A single instance of the code, which handles all operations.
- The database.
Also, although it's not shown in the diagram, we have user management for creating/updating links.
The process is straightforward: a user sends a request to the API, which creates the record in the database and returns it to the user.
If the user has provided an alias, or if we've implemented an expiration date field, we also have to take that into account when creating the record.
For reading, it’s the same. The user does a GET with the short URL, which looks up the record in the database and returns the actual URL with status code 301 (Permanent Redirect) or 302 (found redirection).
As a simple solution or MVP, this simple architecture works, but obviously we can't stop here since there are more requirements.
3.1 - To create short URLs, which characters do we use and how many?
A very common solution for this kind of situation is the use of base62. Why? It’s simple. Just as base10 is the numbers 0-9, with base62 we use numbers 0-9 as well as letters A-Z and a-z, meaning the full alphabet, both uppercase and lowercase. This remarkably reduces the number of characters we’ll need when converting a number from base10 to base62.
For example, the base10 number 123456789 has a base62 value of 8M0kX.
Now that we know the range [0-9][A-Z][a-z], we need to decide the URL length we require. To do this, let's calculate and compare different options. It’s simple: just raise 62 to the power of the desired number of characters to know how many possible combinations we have.
For example, a one-character URL gives us 62 different options, two characters would be 62^2, which is 3844, which doesn’t seem enough.
But let's see other options:
62^1 = 62
62^2 = 3844
..
62^6 = 56 billion URLs
62^7 = 3.5 trillion URLs
62^8 = 218.3 trillion URLsAs you can see, each extra character grows the numbers exponentially and most likely we want a value between 6 and 8. Six seems low, and with just one more digit we could use 7 characters, as 8 would be way too many.
It's very likely our service would never reach such a large number.
Additional note: If you use C#, unsigned int allows a maximum number of 4,294,967,295, which is four billion and fits in 6 characters; but you always have the option to use unsigned long, for which the maximum number allowed is 18,446,744,073,709,551,615 (18 quintillion), and in base62 that is 11 characters (LygHa16AHYF).
Let’s assume that 7 is enough, and the reason is simple: 3.5 trillion is this number: 3500000000000, and in one year there are 31.5 million seconds (31,536,000), which means we’d need almost 110 years at 1000 creations per second to use up all the records, so it’s never going to happen.
3.2 - Keeping track of URLs
In the previous point we saw which characters we’ll use and how many, now we need to generate these values.
A solution could be to generate a random number, hash it and trim to 7 characters. That value would be saved in the database.
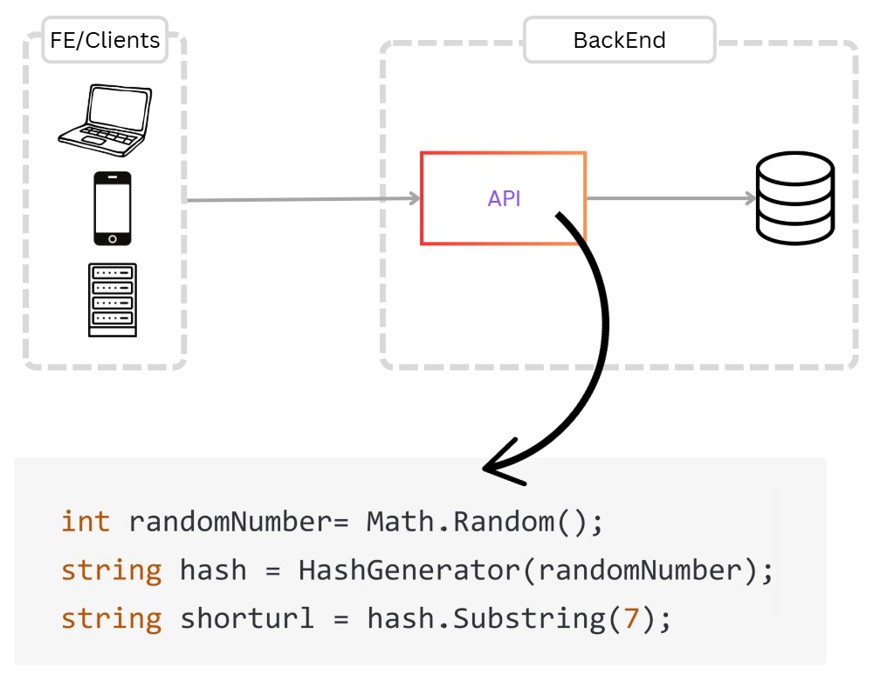
But this solution could result in collisions at some point – maybe not in our lifetime, but technically it’s possible for them to happen.
The best solution here is to use a service coordinator with several options. A very common one is Redis. Why? Redis is a distributed, single-threaded cache, meaning it performs one action at a time so you'll never have a collision.
But an even better solution is to use a dedicated service like Zookeeper, which handles value assignment correctly and independently.
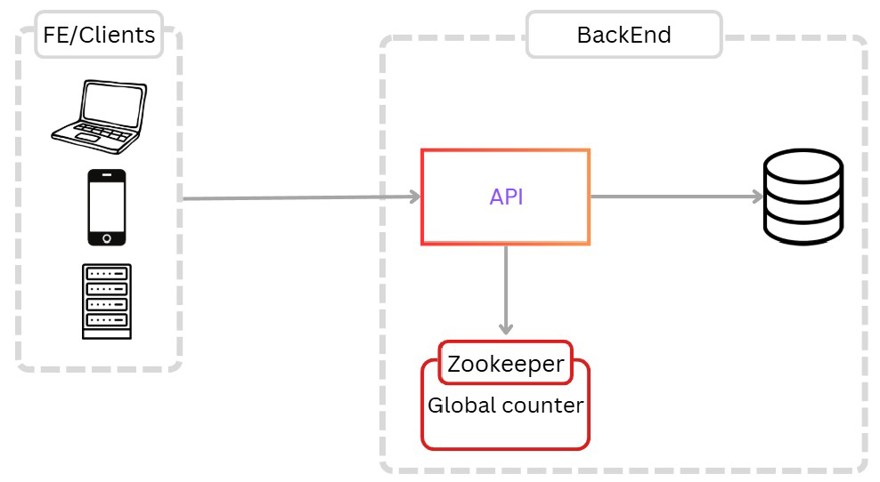
The main reason is that scaling could complicate things, especially if we need to scale Redis, as it would require a lot of configuration and extra steps to avoid giving duplicate IDs to the requesting instances.
That’s why we’ll use a practice or pattern called counter-batching, where, when an instance starts up, it connects to the service coordinator and gets back a range of IDs to use.
For example, instance 1 works within the range 1 to 1,000,000, keeping the current range in memory so it doesn’t need to call the coordinator every time. When instance 2 connects, Redis gives it the range 1,000,001 to 2,000,000, and so on. When the maximum is reached, we query Redis again for two operations: firstly, to indicate that the range is complete, and secondly, to receive a new range.
Of course, the coordinator (whether Redis, Zookeeper, or whichever we want) only returns the range in base 10 to use. The conversion to base62 will be performed by the instances themselves.
3.3 - Scaling a URL Shortener Application
Scaling is crucial nowadays in cloud services, as it helps keep infrastructure costs to a minimum. For that, we need to be able to automatically identify when to scale our applications vertically or horizontally. For our case, the most common would be horizontal scaling, adding more instances.
But in our particular case, it doesn't stop there, because due to the nature of the application, our volume of reads will be much higher than our volume of writes.
As an example, we can use Twitter, which no longer shortens links but used to, and let's take a random Betis tweet:

This tweet was written only once – for this, a POST request with the link is made and the short link is returned.
At the time of this screenshot, this tweet had been seen by 9,400 people. Assuming only 0.1% click, that's 9 people who have visited the link already. So we can safely assume the read usage will be 10 times higher than write usage.
That means we might be interested in splitting the API in two, one for reads and one for writes.
Additionally, when performing reads we will also write in a distributed Redis cache the redirect values for the URLs. This way, repeat requests don't hit the database but Redis instead, which is much faster and requires fewer resources.
The final process would look something like this:
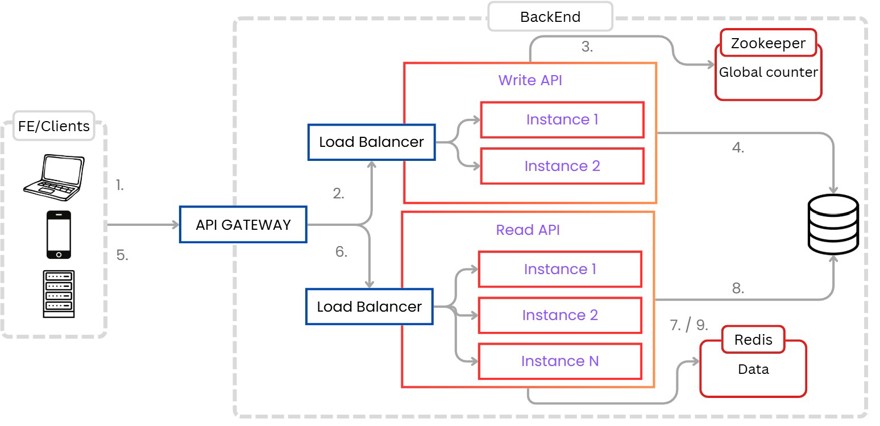
When creating new resources the process is the following:
1 - The client sends a request to the API Gateway.
2 - As it’s a POST method, we use the Load Balancer for the write API and assign an instance.
3 - We get the range from the coordinator, or, if we already have it, calculate the next value
4 - We store the record in the database and return the short URL.
4.1 - optionally, we could also save the newly created URL in the distributed Redis cache that stores URL data.
Once created, let’s move onto accessing that URL.
5 - The user clicks the link and goes to the API Gateway
6 - As it’s a GET, we use the Load Balancer for the read API.
7 - We check whether the record is in Redis.
8 - If not, we read the record from the database
9 - We add the record in Redis and return the long URL, using status code 301 or 302 to redirect the user.
Finally, it’s worth mentioning that when we save in cache, we do so with a specific TTL, so that the cache isn’t an exact 1-to-1 copy of the database, but instead it has the hottest values.
An example is specifying a TTL of two days, since in the Twitter case most clicks will happen in the first few days, and after a week or two, no one will click anymore.
With this, we have the complete architecture of a URL shortening system.
