I've been wanting to make this post for a while, and the truth is that I've been postponing it due to the break I wanted to take from YouTube, but what happened this week with CrowdStrike has sped things up, so let's see what I'm talking about.
Table of Contents
1 - The Fateful Ending
The very first thing to look at, is how we even got here at all.
This Friday, July 19th (2024), the whole world was affected by an issue caused by CrowdStrike, a security software installed on Windows, used by lots , and I mean lots , of companies. Virtually the whole planet was hit by this problem. If you live in South America or somewhere in those time zones, you may not have noticed it or the impact might have been smaller, since it all started around 12PM on the East Coast, which is 5/6AM in Central Europe.
Basically, CrowdStrike released an update that broke Windows systems with a blue screen of death.
This affected every company running Windows servers and depending on these machines , banks, airlines, even hospitals. The everyday user didn't see it because it's not consumer software, it's aimed at businesses.
Here’s an image from Amsterdam airport, where nothing could be done , every screen was blue:
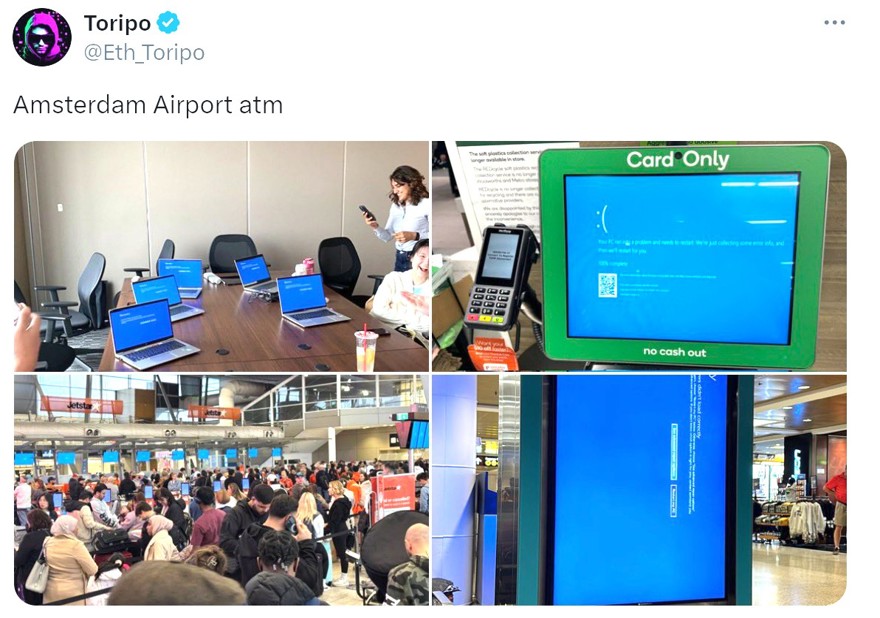
Unfortunately, this kind of event isn’t isolated , maybe not usually this big, but just a few months ago Colossal Order, the developers of Cities Skylines 2, did something similar. They deployed a version that caused in-game offices, the primary income source, to empty out. After you’d put over 100 hours into a game, your save became unplayable.
Obviously it’s not quite the same scale: one’s a game, the other affects millions , yes, millions , of people. But the reasons that led to these outcomes are very similar. And those reasons are what matter, because they affect anyone working in software.
2 - Where is QA?
QA is the team within each company that ensures that developer changes work properly and shouldn't break anything.
While it's true that in small companies, the developer does QA, in bigger companies these roles are usually separated. That's because when a developer tests their own code, they already know how it works and, even if subconsciously, won't try to break it. So, it’s common to have another team/person to verify everything works.
And when we talk about QA, it's not just the people; it's also about the process that software should go through before being released to production. That includes not only reviews, but also automating the test suite and/or running manual tests as well.
The QA phase is crucial in software development. If your company doesn’t have any Quality process, my recommendation is to share this blog post with them , although, well, there are plenty of lessons to be learned from what happened with CrowdStrike.
NOTE: For me, deployments to pre-production environments are part of QA.
3 - Deployments to Production
Once QA is done, the only thing left is to deploy to production , and this is the most important part we’ll look at today, and the main reason I wanted to make this post.
When we deploy, there are different ways to do it. The choice depends on several factors including your company’s size and customer base. I'm not going to cover them all, but I’ll cover three, matching the three main company sizes (small/medium/large).
3.1 - Blind Deployment / Big Bang
This deployment type is common in small companies with a handful of employees and only a few clients.

From QA (which was probably just the same person who did the development), you go straight to production and then just give the okay. Possibly without any manual testing , maybe you go open the site (if it's a website) and check if everything seems fine, and then give the OK.
As I said, this is common in small companies, and it makes sense. There’s no budget to maintain constant monitoring, and if something isn't working for 20 minutes or an hour until someone notifies you, it’s not as expensive as spending an hour or two monitoring every deployment.
3.2 - Gradual Deployment / Rolling
This type of deployment happens in mid-sized companies, where you start having replicas of applications behind a load balancer , in other words, you have a significant number of clients.
As the name suggests, this is a progressive or rolling deployment. What does this mean?
If you have three instances of an app, you'll deploy to one, point the load balancer at it, run your healthchecks (usually /health) to confirm it’s working, and then, if all is well, move on to the next one. If something fails, you cancel the deployment and point the load balancer back to the previous instance.
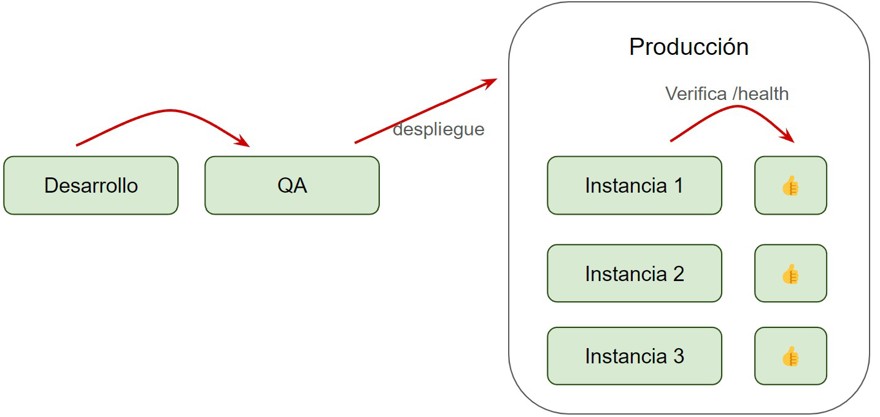
When you finish with all instances, you run the tests. Most likely, the system will have monitoring and alerting in place which will automatically notify you if anything goes wrong, so you can catch errors before end users do.
3.3 - Canary Deployment
Finally, a deployment approach that is very expensive both in human and infrastructure terms, but the right way to go if you have millions of customers.
Let's talk about canary deployment. This means rolling out functionality to a subset of users and monitoring them intensively to make sure everything works.
Of course, this takes a lot of resources: you need to set up and maintain the infrastructure to make it possible and have personnel in charge. It’s not just hitting a button and everything running automatically; you (usually) need to manually check stats and reports to ensure everything is working.
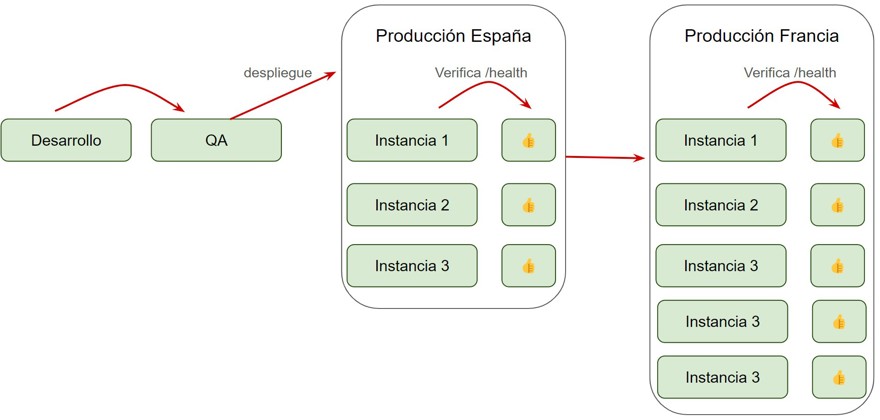
A very common example, for a company with customers in regions worldwide, is to deploy the change in just one country (say, Spain). Once you verify everything's fine in Spain, you roll it out to the rest of Europe, and then to the other continents.
This way, if something breaks, only your Spanish users are affected first. You have several filters before rolling out globally.
Don't forget, aside from deploying by region, you can also implement techniques like gradual deployment within each individual zone, for even more safety.
Of course, the downside is that it takes a lot , and I mean a lot , of time. Having worked in all three types of companies, canary deployment seems like a waste of time, until something goes wrong and you're glad you used it.
The problem with CrowdStrike is that they're a company with millions of customers; they should have used canary, but they went with a blind deployment for everyone.
4 - Deploying on Friday
I didn't want to finish this post without telling you: don't deploy on Friday if you don’t want to ruin your weekend.
Obviously, I'm joking , unless your company uses the first (or similar) deployment method I described, you can pretty much deploy on a Friday without a problem.
But still, make sure everything works as it should, and don’t take a two-month vacation the day after deploying, like everyone at Colossal Order did with CS2.
