This is possibly one of the questions I've received the most in the content I've created about Entity Framework. Here we'll take a detailed look at multi tenancy.
Index
1 - What is multi tenancy?
Multi tenancy is simply the term we use in programming when we have a system that works for multiple clients or tenants, which is a very common situation in day-to-day work life.
2 - What strategies can we apply to implement multiple clients?
We can implement the solution in various ways, the ultimate goal is to avoid data contamination between clients. That should be the main objective, as data contamination is very bad for business.
2.1 - Database separation
Generally, all clients have the same tables, with the same columns and the same business logic; what usually changes is the data itself.
For this reason, one of the approaches we can implement is the physical separation of those data, meaning we have one database per client.
The advantages at the database level are clear: we access data as we wish, there is no need for filters or extra checks, and we should assume that if we're querying that database, it's from an application that should have access.
The disadvantages are also obvious: we no longer have a single database but several, which comes with a higher administrative burden for updates. This is because, instead of running migrations once, we now have to do it once per database.
Note: This solution can also be implemented using schemas within a single database.
At the application level, we have two ways to implement this solution:
2.1.1 - Application separation
The first is that each client has their own application, or cluster, etc. In other words, each client has their own version of the system, and in my opinion this is a problem. We're not going to dig deep into why this is an issue, but if bugs appear, you have to fix them in older versions, maintain incompatibilities, and deal with similar situations.
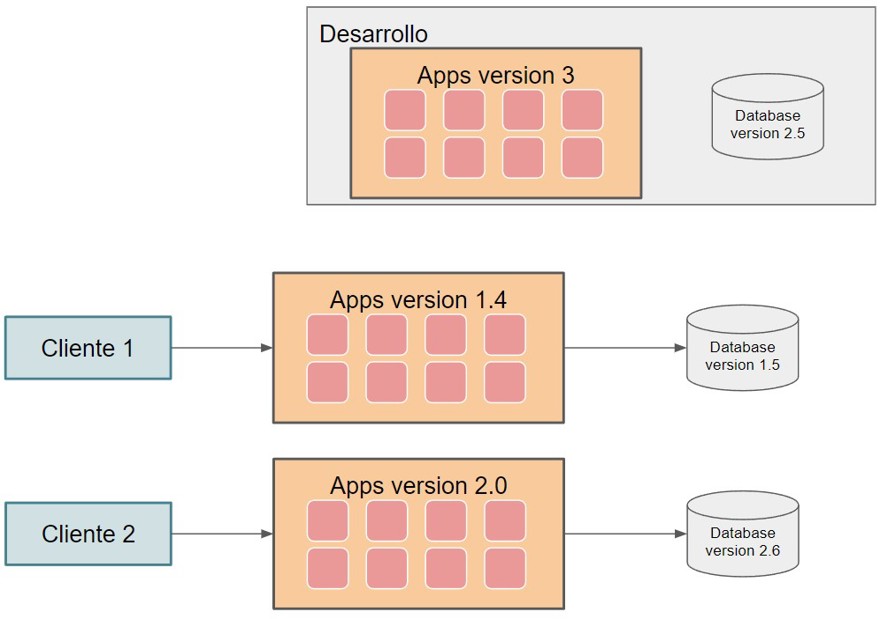
The good part of this approach is that you manually specify the database connection in the client's own code, so it is very difficult to have a data contamination issue. The only way would be if the connection was written incorrectly.
2.1.2 - Connection administrator
The second approach inside database separation is one that is named differently in each company: connection administrator. I've seen it called connection pooling, connection multiplexing (I often call it database connection multiplexer), or just connection administrator. It refers to the process of, given a client, determining or receiving the necessary connection, pointing to different databases.
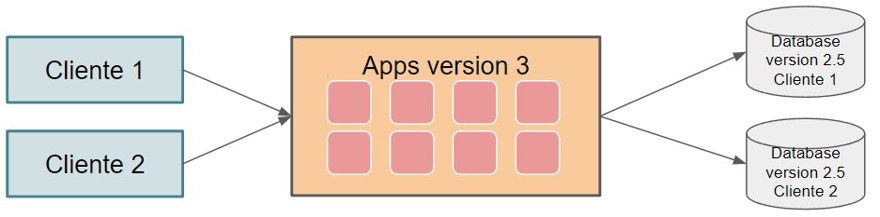
In this way, we keep all clients in the same codebase and database version, but their physical databases are different. So in this case, we've eliminated one of the issues from the previous approach.
2.2 - Separation by Id column
As the name suggests, in each table in our database, we add a column referencing the client Id, so everyone uses the same code and the same database.

This is usually one of the most common implementations, as it ensures you have only one deployed set of applications and a single copy of the database.
On the other hand, we must make sure that the code always checks the client's Id field, because if we don't, we could have data contamination.
2.3 - Which version to choose
When deciding how to separate clients, several things must be considered.
First of all, there are legal issues. For example, some companies require that their information not only stays in their region but is also isolated. If you've worked with clients from the United States, having the data hosted in the U.S. is mandatory. There are also companies that want their data isolated.
Number of clients: If you have an application that works with banks, you'll know there is a finite and relatively small number, so you could have physical separation of data. But if your clients are construction or transport companies where there are thousands, it is common to have a client Id field in every table in the database.
Number of resources in the company: The number of employees/teammates in your team limits these actions, since it's not the same to manage 30 database copies with 2 people as with 15.
Usually, except for specific cases, what we'll do is to have the client ID field in the database, which covers 95% of companies.
There is another percentage, those with a single client that requires their data to be separated. In that case, we can isolate only that client. Obviously, we'll need a connection administrator, but we know that besides the connection, we'll have the client's ID, so there won't be data contamination.
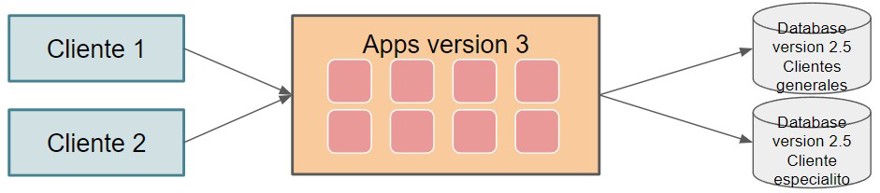
In my case, I saw this implementation when I worked for an airline, and one of the clients (other airlines) said they had to have the data in a certain country. The database was simply duplicated, and all their data went there.
3- Implementing a connection manager in C#
In reality, the implementation is not all that mysterious. Generally, we have two options: inject during application deployment or use a combination between configuration and credentials.
Alternatively, we could have a connection where all information is the same and only the database host changes, which contains the client id. For example, something like:
server=dbserver-id1
server=dbserver-id2But the rest of the connection is exactly the same, so all you have to do is replace the tenant information in the string.
But most commonly, you'll have multiple connections, which requires a few changes in your code.
For this example, we'll use the code we've been using throughout this Entity Framework course. And the code we originally use to connect to MySQL is this:
services.AddDbContext<CursoEfContext>((serviceProvider, options) =>
options
.UseLazyLoadingProxies()
.AddInterceptors(new ReadExampleInterceptor(),
new SecondLevelCacheInterceptor(serviceProvider.GetRequiredService<IMemoryCache>()))
.UseMySQL("server=127.0.0.1;port=4306;database=cursoEF;user=root;password=cursoEFpass"));NOTE: this example is with MySQL, but it works the same with all databases.
What we need to do is change that code to allow multiple connections. This is very easy because AddDbContext uses AddScoped behind the scenes, which means the lifetime of the dbcontext is the execution of the request.
So, we only need to create a class that returns the connection.
public interface IDbConnectionManager
{
string GetConnectionString();
}
public class DbConnectionManager : IDbConnectionManager
{
private readonly IHttpContextAccessor _contextAccessor;
public DbConnectionManager(IHttpContextAccessor contextAccessor)
{
_contextAccessor = contextAccessor;
}
public string GetConnectionString()
{
//_contextAccessor.GetTenant();
//Calculate the database URL by tenant
return "server=127.0.0.1;port=4306;database=cursoEF;user=root;password=cursoEFpass";
}
}The implementation isn't complete, since our current code does not require authentication. But the idea is simple: you take the token, read the tenant, and from that tenant you calculate the database connection, however you want—as I said before, it could be by configuration + secrets or simply with the client's name in the connection string.
The next step, besides injecting the service into the dependency container, is to use it within the dbContext definition:
services.AddScoped<IDbConnectionManager, DbConnectionManager>(); 👈
services.AddDbContext<CursoEfContext>((serviceProvider, options) =>
options
.UseLazyLoadingProxies()
.AddInterceptors(new ReadExampleInterceptor(),
new SecondLevelCacheInterceptor(serviceProvider.GetRequiredService<IMemoryCache>()))
.UseMySQL(serviceProvider.GetRequiredService<IDbConnectionManager>().GetConnectionString())); 👈
And that's it—now you can calculate the connection for every specific tenant, since the information is computed in each HTTP call.
By the way, I haven't mentioned this, but with this implementation, using Database First is not as straightforward, since migrations, if they're in the application itself, only run once when the application starts. In this case, what I've seen done is to have a database project that is run on all databases.
