In this post we’re going to look at what cache means in software and how to implement a distributed cache server using Redis and C#.
Table of Contents
1 - What is cache storage
When we use the term cache, we can refer to two main things. The first is the cache memory located in our computer’s processor.
The second, and the one we’ll focus on today, is the cache we refer to when developing software. This type of cache is a memory storage for our data.
For example, in a web environment, keeping a List/Dictionary in memory all the time could be considered a "cache"; obviously not the best solution, but you get the idea.
2 - Why do we want to use cache
As I mentioned, the information stored in cache is located in memory, which means access to it is practically instantaneous.
With this in mind, we can assume that cache is useful for data we need to use multiple times.
Of course, using memory only reduces the resources the application needs. For example, if we access another microservice, it uses a network service.
Another benefit is that by not consuming the external service, we reduce its load, making it less likely to fail or become overwhelmed.
2.1 - Cache use case
Many times we need to keep cache information in a single application.
For example, we have an app that performs a certain action on all our users and then prints it together with the company name.
In a world of microservices, we get the company information by making a call to the company microservice.

But this can get out of hand, since nothing guarantees that we’re only making one call per company, we’ll be making one call per user, which means if two users are in the same company, we’ll fetch this info multiple times.
To fix this, we usually call the microservice in advance, right before the loop, but if this process will run more than once, and not just for a single request but for many.
Note: The code is not structured in the best possible way; it’s focused on using and showing how the cache works.
To see how to properly structure your applications, visit: Application structure.
A very common example is having a list of users and wanting to print the user and the company they work for, but in our user microservice, we only have the company ID, not the company details:
public record UsuarioEntity
{
public string Nombre { get; init; }
public string Apellido { get; init; }
public int IdEmpresa { get; init; }
}To get the company data, we query the company microservice, which returns the following object:
public record EmpresaDto
{
public int Id { get; init; }
public string Nombre { get; init; }
public string Ciudad { get; init; }
public string Pais { get; init; }
}
The logic is very simple: we read all users and loop through them, making a call for each one.
public async Task<List<UsuarioDto>> GetAllUsuarioDto()
{
List<UsuarioDto> resultUsuariosDto = new List<UsuarioDto>();
List<UsuarioEntity> usuarios = await _dependencies.GetAllUsers();
foreach(var usuario in usuarios)
{
EmpresaDto empresa =await _dependencies.GetEmpresa(usuario.IdEmpresa);
UsuarioDto usuarioDto = new UsuarioDto
{
Nombre = usuario.Nombre,
Apellido = usuario.Apellido,
NombreEmpresa = empresa.Nombre
};
resultUsuariosDto.Add(usuarioDto);
}
return resultUsuariosDto;
}
Of course, we must implement _dependencies, which is where we’ll make the calls to both the database and the company microservice:
public class ListUsersWithCompanyNameDependencies : IListUsersWithCompanyNameDependencies
{
private readonly IHttpClientFactory _httpClientFactory;
private readonly IUsuarioRepository _userRepo;
public ListUsersWithCompanyNameDependencies(IHttpClientFactory httpClientFactory, IUsuarioRepository userRepo)
{
_httpClientFactory = httpClientFactory;
_userRepo = userRepo;
}
public async Task<List<UsuarioEntity>> GetAllUsers()
{
return await _userRepo.GetAllUsers();
}
public async Task<EmpresaDto> GetEmpresa(int id)
{
HttpClient client = _httpClientFactory.CreateClient("EmpresaMS");
return await client.GetFromJsonAsync<EmpresaDto>($"empresa/{id}");
}
}The result would look like the following image, a query to a microservice for every user we need to fetch.
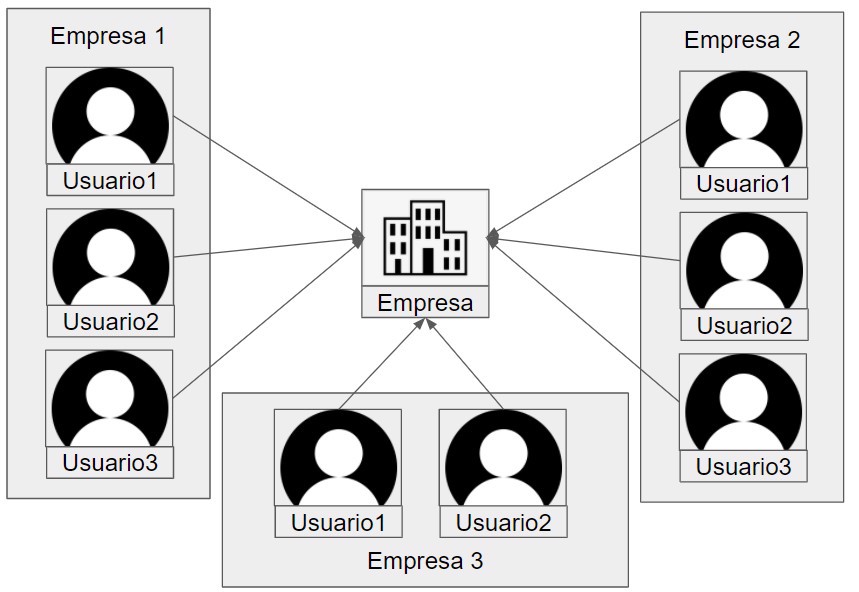
In the long run, this solution isn’t viable as it puts a lot of load on the network, increases latency, etc.
Note: Visit the following link to learn how to properly implement HttpClient.
3 - In-memory cache for a single application
To solve the problem of so many calls, we can implement an in-memory cache within our application. To do this, Microsoft provides a class for cache called MemoryCache.
With this feature, our goal is to reduce the number of calls to our company microservice, reducing it to one call per company and using the cache for the rest.
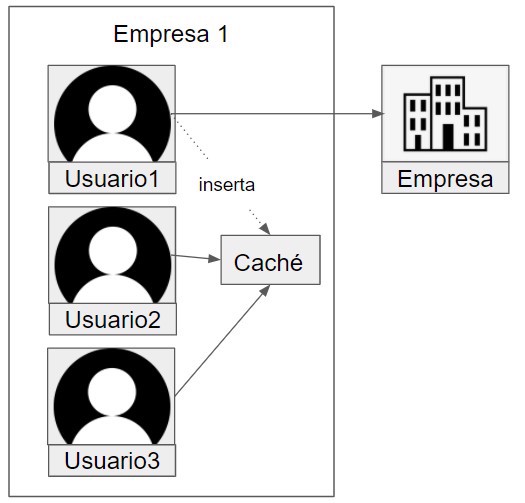
To implement this feature, we just need to create a service that wraps our calls to the second microservice.
In our new service, we instantiate the cache in the constructor:
public class EmpresaServicio
{
private readonly MemoryCache _cache;
public EmpresaServicio()
{
_cache = new MemoryCache(new MemoryCacheOptions());
}
}Then we implement the service, where we'll make an HTTP call to the microservice if the item we’re looking for isn’t in the cache:
public interface IEmpresaServicio
{
Task<EmpresaDto> GetEmpresa(int id);
}
public class EmpresaServicio : IEmpresaServicio
{
private readonly MemoryCache _cache;
private readonly IHttpClientFactory _httpClientFactory;
public EmpresaServicio(IHttpClientFactory httpClientFactory)
{
_cache = new MemoryCache(new MemoryCacheOptions());
_httpClientFactory = httpClientFactory;
}
public async Task<EmpresaDto> GetEmpresa(int id)
{
//Check if it exists
if(!_cache.TryGetValue(id, out EmpresaDto empresa))
{
//Query the microservice if not in cache
empresa = await GetFromMicroservicio(id);
_cache.Set(id, empresa);
return empresa;
}
return empresa;
}
private async Task<EmpresaDto> GetFromMicroservicio(int id)
{
HttpClient client = _httpClientFactory.CreateClient("EmpresaMS");
return await client.GetFromJsonAsync<EmpresaDto>($"empresa/{id}");
}
}Remember to register it as a singleton in dependency injection, since we want to keep this cache shared across all incoming requests.
services.AddSingleton<IEmpresaServicio, EmpresaServicio>();Finally, we just need to update our dependencies to use the EmpresaServicio we just created instead of using the HTTP calls
public async Task<EmpresaDto> GetEmpresa(int id)
{
HttpClient client = _httpClientFactory.CreateClient("EmpresaMS");
return await client.GetFromJsonAsync<EmpresaDto>($"empresa/{id}");
}
//New GET Empresa
private readonly IEmpresaServicio _empersaServicio;
public async Task<EmpresaDto> GetEmpresa(int id)
{
return await _empersaServicio.GetEmpresa(id);
}If you run the app, you’ll see that from the client’s perspective, the result is the same, but internally the network load and speed are dramatically improved.
3.1 - MemoryCache vs Dictionary<string, T>
It used to be common to solve this with a dictionary in C#, but this isn’t the best solution because when we define MemoryCache we get some options.
These options include the ability to remove expired objects or set a maximum size for our cache.
Meanwhile, if we use a dictionary, the data stays there forever unless we remove it manually.
Also, MemoryCache is thread-safe.
4 - Distributed cache for multiple microservices
But what happens if we want to access this same information from another microservice?
For this example, let’s say we have another microservice for cars that does something similar, shows the brand and model and also the company the car belongs to.
We could do the same thing as before, creating a cache for company data inside the cars microservice.
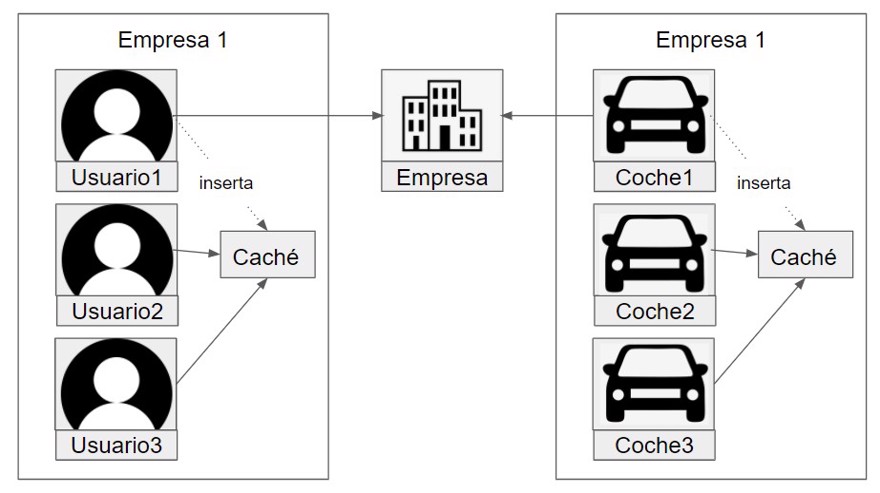
But this isn’t really the best approach, since the info is going to be read not by one, but by two microservices. So why have it duplicated?
The ideal solution would be a shared cache for all services that need to access this info.
Here is the diagram:
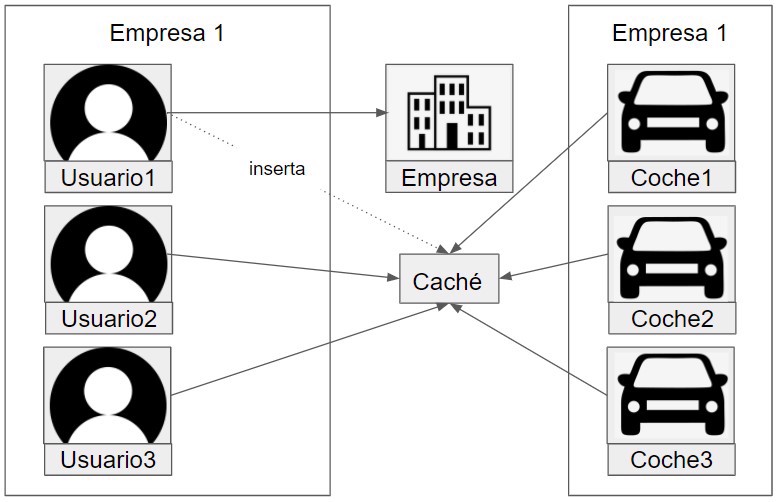
As we can see, there’s only one call to the microservice, while the rest go through the cache server.
And for this cache server, we’ll use Redis.
5 - What is Redis?
Redis is open source software that allows us to store data structures in memory, use it as a cache layer, or as a message broker.
Unlike the in-memory cache from earlier, Redis is a "server" itself, and as such, we can deploy and configure it as one.
Note: Technically, it’s not a server but an application running on the server, but usually the whole server is dedicated to Redis.
Data in Redis is stored in RAM, so our limitation is memory, not disk. This setup gives us much faster data access.
Redis also offers data persistence if you need it, or expiration policies for the data.
6 - Implementing a Redis cache server in C#
First of all, before we begin, in order to follow the example you need a Redis server or a docker container with Redis running.
In my case, I created a small docker-compose file that contains the Redis info.
version: '2'
services:
redis:
image: 'bitnami/redis:latest'
ports:
- 6379:6379
environment:
- REDIS_PASSWORD=password123Once you have your server up and running, we’ll move on to the code.
First, install the Nuget package Microsoft.Extensions.Caching.Redis which is built on top of StackExchange.Redis, an open-source package maintained by the StackOverflow team. Install it in all projects that will use this cache.
The process is similar to before, but we need to swap MemoryCache for IDistributedCache, and this time, inject it via DI instead of instantiating it.
public interface IDistributedEmpresaServicio
{
Task<EmpresaDto> GetEmpresa(int id);
}
public class EmpresaServicio : IDistributedEmpresaServicio
{
private readonly IDistributedCache _cache;
private readonly IHttpClientFactory _httpClientFactory;
public EmpresaServicio(IHttpClientFactory httpClientFactory, IDistributedCache cache)
{
_cache = cache;
_httpClientFactory = httpClientFactory;
}
public Task<EmpresaDto> GetEmpresa(int id)
{
throw new System.NotImplementedException();
}
}The logic in our GetEmpresa method is the same. Check the cache first; if it’s not there, call the company microservice then insert it into the cache.
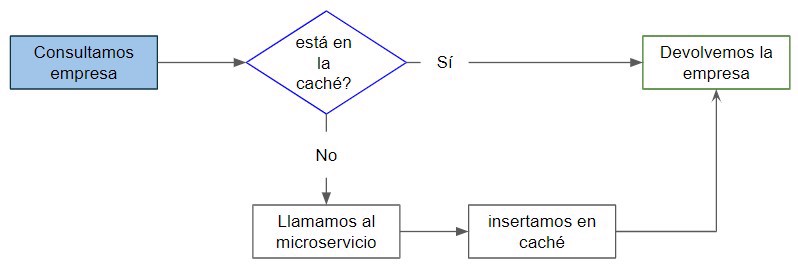
One thing to note, when you add something to IDistributedCache, use the SetAsync method, which takes a string key and a byte[] value.
This means you need to convert your value to bytes before storing it and also when reading it.
public async Task<EmpresaDto> GetEmpresa(int id)
{
byte[] value = await _cache.GetAsync(id.ToString());
if (value == null)
{
EmpresaDto empresaDto = await GetFromMicroservicio(id);
if (empresaDto != null)
await AddToCache(empresaDto);
return empresaDto;
}
return FromByteArray(value);
}
private async Task<EmpresaDto> GetFromMicroservicio(int id)
{
HttpClient client = _httpClientFactory.CreateClient("EmpresaMS");
return await client.GetFromJsonAsync<EmpresaDto>($"empresa/{id}");
}
private async Task AddToCache(EmpresaDto empesa)
{
await _cache.SetAsync(empesa.Id.ToString(), ToByteArray(empesa));
}
private byte[] ToByteArray(EmpresaDto obj)
{
return JsonSerializer.SerializeToUtf8Bytes(obj);
}
private EmpresaDto FromByteArray(byte[] data)
{
return JsonSerializer.Deserialize<EmpresaDto>(data);
}Of course, you must register IDistributedCache as one of the services:
//hardcoded values for demonstration
services.AddDistributedRedisCache(options =>
{
options.Configuration = "localhost:6379,password=password123";
options.InstanceName = "localhost";
});
And now, if we have another microservice, we would use similar code: first check the cache, then call the microservice and add to the cache.
7 - Implementing in-memory cache and Redis
Another solution for data that’s accessed constantly is to use both options, each microservice having its own in-memory cache and, if the data isn’t found there, check in Redis and finally use the HTTP call
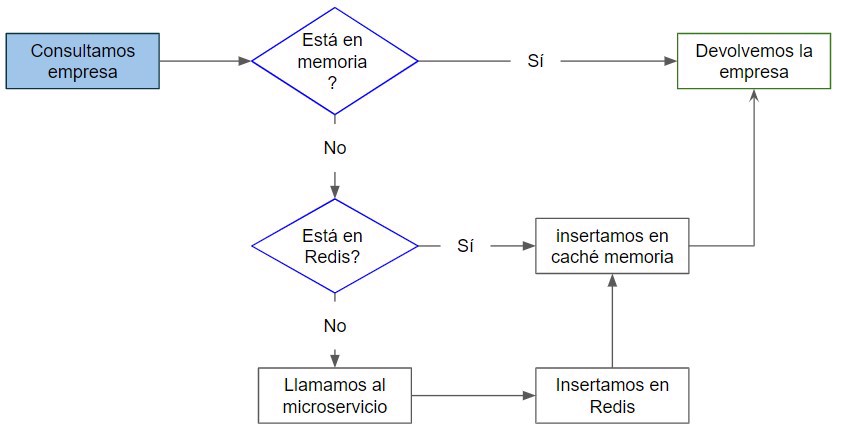
Conclusion
- In this post, we’ve seen why to use cache in our microservices.
- We looked at how to implement an in-memory cache when we have only one application accessing the information.
- We gave an introduction to Redis and how to use Redis in our microservices to have a distributed cache.
