You've probably seen in recent years on LinkedIn or Twitter those typical images comparing one situation with another, claiming that one is completely wrong and the other is amazingly right according to its creator.
Personally, I'm not a fan of this kind of content, because 90% of it is either partially incorrect or simply an obvious truth, so I just ignore it, and if I see more cases, I mute whoever shares it. But in this post I'm going to talk not only about those situations, but also another trend that’s become quite common lately online: benchmarks.
Careful, not all of this content is wrong. As I said, in my opinion, 90% is, but the other 10% is usually very high quality.
1 - Low-bait Content in Programming
Let’s talk about the first case, where I hope the author doesn’t take offense because this isn’t an attack on them, it's just the last example that popped up for me and since I hadn’t done a code review in a few days, I felt like going for it.
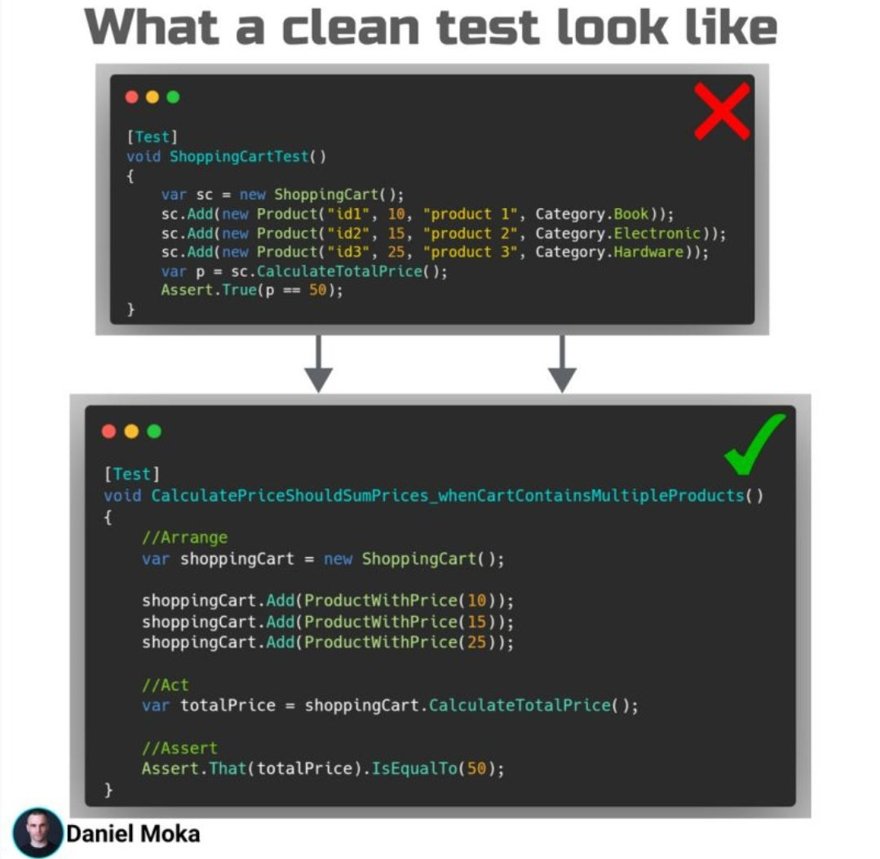
In this image, the author says the second version is much better code and much cleaner, which at first glance seems true.
But let’s analyze what makes that code "clean."
- They gave the test a proper name, or so they say.
- They used a variable with an appropriate name.
- They put AAA and empty lines for spacing.
There are more details, but that's what stands out at a glance. So let’s start there:
With the name of the test, it's clear things have improved. We've gone from a generic, totally useless name to one specific about what the test does. In my opinion, it should follow given_when_then; in this case, since it's simple, we can skip "given," which I think is fine: “CuandoElCarroContieneMultiplesproductos_EntoncesCalcularLaSuma.” But the error is obvious, they wrote the phrase backwards.
Regarding the variable name, there isn't much to add, this is indeed much better. But it's also just common sense, and I personally can't remember the last time I saw someone use one or two letters for variable names.
The use of AAA, for those who don’t know, AAA stands for arrange, act, assert, the three parts of a test. In my opinion, it’s totally unnecessary; I wouldn’t request to remove it in a PR, but it’s a comment that serves no real purpose.
Now let's analyze the rest of the changes to what’s called "clean code":
Instead of creating a product in the test itself, the author abstracts product creation into a method. At first, that’s a good idea. The problem is the execution is off. The method is called "ProductWithPrice:" the name doesn’t actually tell you what it does. But it doesn’t stop there; if you look at the first example, the product uses strings as IDs and has a name and category field.
So, what ID does the method pass in? What name? What category? Are they random, or is anything being calculated?
In my opinion, if that method were called "CreateDefaultProduct," it’d be fine because you’d assume parameters that are omitted use default values; but as it stands, I can only assume the ID, name, and category are all the same.
So, thanks to this extra level of indirection, doubts arise.
Looking at the assertions: the first one uses the default package in C#, and yes, it’s incorrect. But the reason it’s wrong is because it's comparing for assertion validation, NOBODY does this, NO-BO-DY. I’ve been programming for over a decade and seen a bit of everything, and I've never seen anyone do this.
If the assertion were correct, using Assert.equal(expected, actual) would be perfectly clear and much better than the second one. Because the second uses the fluentAssertions library, which is fine to use, unless in this case you're adding an extra dependency for something totally unnecessary. If it happens that this library is used throughout the project, fine, use it, but here, nothing indicates that.
Not to mention that the expected sum value should be in a variable and not hardcoded directly in the assertion.
TL;DR: The second test is just as much crap as the first one.
2 - Don't Trust Benchmarks!
The second topic I want to talk about is more complex and is getting much more popular lately: benchmarks comparing different languages.
Specifically, I want to discuss one example, the code on GitHub comparing Levenshtein distance across languages to see which is fastest.
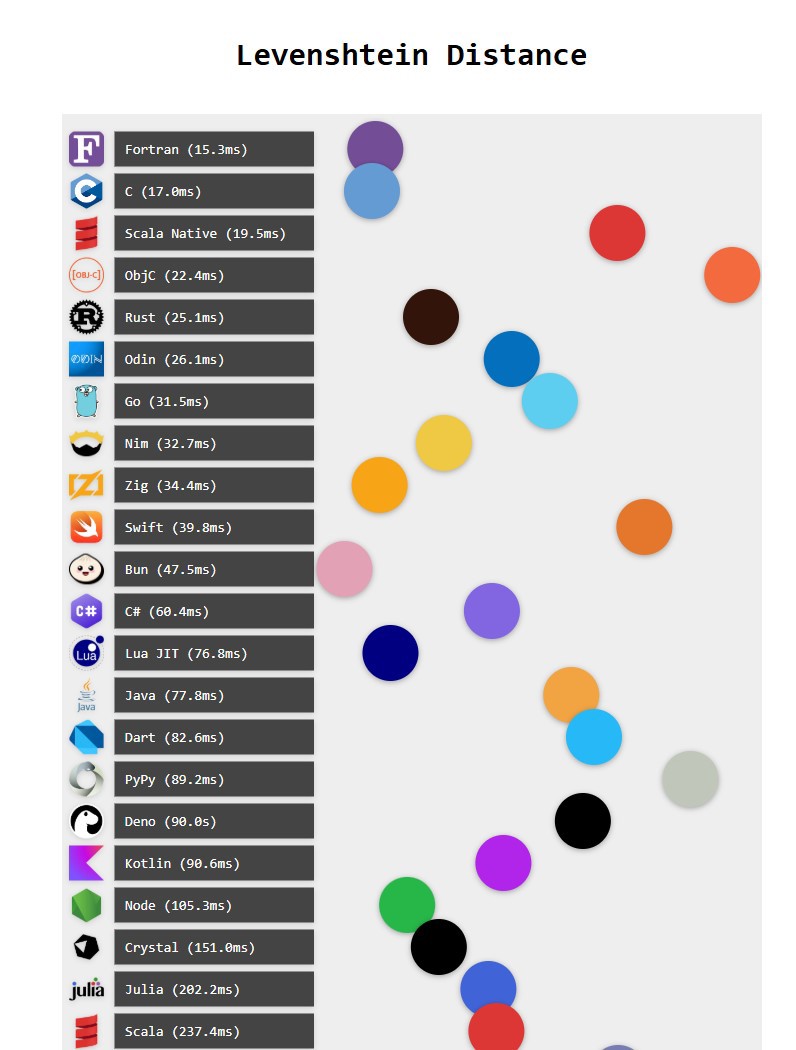 WEb: https://benjdd.com/languages3/ | github repo https://github.com/bddicken/languages
WEb: https://benjdd.com/languages3/ | github repo https://github.com/bddicken/languages
On the web there’s a neat animated graph, but let’s get to the point.
At first glance, what's surprising is that the fastest language is Fortran, and not just that, Fortran is 20% faster than C!
So you know, everyone, let’s all switch to Fortran.
Joking aside, if this doesn't raise red flags for the creators of that benchmark, anyone who knows a bit of Zig or Rust will realize that their execution time compared to C should be similar, within some margin of error; however, Rust runs 75% slower and Zig is almost three times slower. That makes no sense!
At this point, without knowing anything else about any other language, you should be suspicious.
I won't even get into the other languages, but just by looking at the top few you see that whoever did this comparison doesn’t know how to program in those languages. Let’s face it, by now we all know they used artificial intelligence..
To see what’s wrong with this benchmark, there’s a one-hour video (https://youtu.be/EH12jHkQFQk) in English you can watch, which goes into detail on the conclusion, but I’ll summarize.
Levenshtein distance compares two strings to see how different they are (Wikipedia: https://en.wikipedia.org/wiki/Levenshtein_distance).
For the test, there’s a file (https://github.com/bddicken/languages/blob/main/levenshtein/input.txt) containing a series of strings of various lengths, and each language runs what at first looks like the same code.
The video specifically compares Fortran and C.
The upshot, or the root of the problem, is very simple: in the variable definitions to be compared, they’re declared as strings of 100 characters.
character(len=100), allocatable :: args(:)
character(len=100) :: argCode (fortran -> code.f90-> lines 93, 94) - GitHub Link.
So Fortran is only comparing the first 100 characters, when the longest string is over 300, which obviously makes Fortran run faster because it has less to compare.
Once the bug was fixed, Fortran’s version was actually 30% slower than C’s. But it goes further, in the video they explain that for someone expert in Fortran, the code can likely be optimized to be much more like C’s, since there are plenty of seemingly unnecessary memory assignments. In both languages, the main logic loop was basically identical in assembly output.
This little analysis shows that for these kinds of results, especially micro-benchmarks, the author didn't do the right checks to verify everything works exactly the same. As it happened, the value being compared was always the same and the number of comparisons was the same, so they just assumed it worked, when it didn't.
This is just one example among many. Whenever you see a language efficiency comparison, you must consider how experienced the author is in that language. It’s very rare for both implementations to be perfect.
Conclusion
Before you like, retweet, heart, or share on LinkedIn, please take the time to carefully read and analyze the content.
Just because something has hundreds of likes or thousands of stars on GitHub doesn’t mean it’s right.
And of course, be wary of trusting certain benchmarks, since many languages or frameworks are intentionally coded to compete on specific benchmarks.
