Training an LLM takes a lot of time, an enormous amount, depending on the amount of data, it could take days. So, how do those LLMs have up-to-date data, and not only that, know where the information comes from and cite sources?
Table of Contents
1 - What is RAG?
RAG stands for Retrieval-Augmented Generation, where we have an LLM that we do not train but rather provide our own context on top for each question.
This brings advantages such as fewer hallucinations, knowing where the information comes from, and a very simple implementation.
A very common use case for RAG is support and documentation. We can have a model to which we give an entire company's content, and it can serve as a first-level chatbot since our model has all the context and "knows" everything we feed it.
RAG can receive information from anywhere; the most common sources are a database or a file system.
2 - Structure of a RAG System
To implement RAG, there are several steps, which we will see in this post.
First, we have to read the data, extract information (from a database, a file, or a website), and then chunk the data, known as chunking.
Second, we convert each chunk into numeric representations called embeddings. An embedding is a list of numbers (a vector) that captures the semantic meaning of the text.
We store these vectors in a vector database. (id, text, vector, metadata)
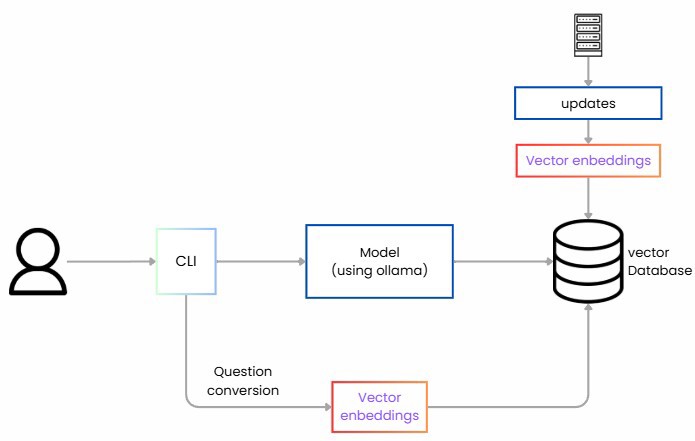
Later, for queries, we do the same: we convert the question into a vector and retrieve the most similar chunks.
We orchestrate the prompt with instructions and generate the LLM's response strictly from the retrieved content.
2.1 - What is a Vector Database?
The key part of RAG is the vector database, which is a type of database designed to efficiently search high-dimensional vectors.
To compare, when we search information in a more traditional database like SQL or NoSQL, we typically search using text or exact identifiers: by name, by text, etc. Most searches are exact. In a vector database, we're not looking for exact results but rather things that are "conceptually similar."
This is achieved because when we store text, images, or anything else, we don't store the literal value; instead, we store a numerical representation of its meaning. This numerical representation is the vector.
When we say that two vectors are "conceptually similar", we mean the following.
If we have a phrase like: "The ending of Game of Thrones is terrible" it might become a vector like [0.20, -4.45, 0.80, ...]
And then the phrase "The last episodes of House are really good" becomes a vector like [0.22, -4.50, 0.7, ...]
But by contrast, the phrase "The best omelette is with onion" might become a vector [0.8, 0.02, -0.3, ...]
These vectors represent what is conceptually similar: the first two sentences are very similar, so their vectors are close together. The last one, however, has nothing to do with them and is far away in vector space.
3 - Creating a Local RAG System
Here we will see how to build RAG using C#. For that, we need several elements.
3.1 - The Model to Use
The first thing we need is a model. You can use any open source model from Hugging Face or use Azure's own models.
In my case, I'm going to use llama3 because it's a small model that meets my needs.
NOTE: Before continuing, as we are going to run this process entirely locally, we need an embeddings model specialized in converting text to vectors. In my case, I'm using nomic-embed-text.
3.2 - Vector Database
The second step is having a vector database. For a small example like today, we could use the memory of our machine, but in production, we should use a real system. Options include Qdrant, Weaviate, Pinecone, PostgreSQL with the pgvector extension, or any of the cloud services.
Once we have chosen the system, in our case, PostgreSQL, we can spin it up in a container with the following code and continue:
version: '3.8'
services:
postgres:
image: pgvector/pgvector:pg16
container_name: rag-db-local
environment:
POSTGRES_DB: rag_db
POSTGRES_USER: user
POSTGRES_PASSWORD: password
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
2.3 - Semantic Kernel
Finally, we need to bring all the pieces together. We need to coordinate searching the vector database, making calls, and although we could do all this manually, Microsoft provides us with an incredible tool: Semantic Kernel.
Semantic Kernel is an SDK that acts as an orchestrator to put it all together.
In our case:
- It connects to the vector database for storing and searching information.
- It defines the RAG flow: receive a question, generate the embeddings, search, build the prompt, and call the LLM.
- Additionally, we can integrate plugins and features by connecting to other APIs or services.
With this, we're ready to build RAG locally.
3 - Implementing Local RAG with C#
Now let's simply put everything we've seen into practice.
3.1 - Preparing the Environment for Local RAG
The first step is to prepare the environment. We need to use the vector database already mentioned; in our case, it will be postgres with pgvector. Personally, I launched it with docker compose as shown above, now we just have to run it with docker-compose up -d.
If you've been following the previous chapters, you'll know we've been using Ollama, and we’ll continue with it. In my case, I have llama3 installed. If you don't have Ollama, I recommend checking the first video in the series, and to download it simply execute ollama pull llama3.
Additionally, you need an embeddings model specialized in converting text to vectors.
ollama pull nomic-embed-text
Once they're downloaded and Ollama is running on your machine, they're ready to receive requests.
3.2 - Configuring the C# Project for Local RAG
Now let's configure our C# project, you can use any kind of project; I’ll use a console project for the example, but you can choose whatever you like. All you'll need is a few NuGet packages:
Microsoft.SemanticKernel
Microsoft.SemanticKernel.Connectors.Ollama // <- preview
Microsoft.SemanticKernel.Plugins.Memory // <- preview
Npgsql // postgress
Now, in the same folder, you can create a file called data.txt. In my case, I put in a summary about myself because it’s easier to show that it’s working. For production, you’d use your own system’s data.
NetMentor is the personal brand of Iván Abad, Microsoft MVP and backend engineer specialized in .NET, C#, and distributed systems. Through his blog, YouTube channel, and courses, NetMentor makes complex topics like architecture, microservices, cloud, testing, and AI/LLMs accessible to Spanish-speaking developers in a clear and practical way.
With a direct and educational style, NetMentor blends theory with real-world experience from large-scale projects, sharing best practices, common pitfalls, and lessons learned from day-to-day software engineering. He is also the author of books such as Construyendo Sistemas Distribuidos and Guía completa full stack con .NET, reinforcing his commitment to accessible, high-quality learning.
NetMentor is not just a technical resource—it’s a growing community that fosters continuous improvement, curiosity for new technologies, and a passion for building robust, scalable, and well-designed software.
Now I’ll share the code. Normally, this is not done with C#. In fact, you may have noticed that most packages are in preview, so many features are experimental. We need to keep in mind that this code is valid today, but may change. That said, the overall idea or process will remain the same.
In the code, we do the following: first, we define all the default information, connection string, Ollama endpoint, models, and the files to read.
var connString = "Host=localhost;Port=5432;Database=rag_db;Username=user;Password=password;";
var ollamaEndpoint = new Uri("http://localhost:11434");
var textModel = "llama3";
var embedModel = "nomic-embed-text";
var collection = "datos_collection";
var inputFileName = "datos.txt";
var inputFilePath = Path.Combine(AppContext.BaseDirectory, inputFileName);
var builder = Kernel.CreateBuilder();
builder.AddOllamaTextGeneration(modelId: textModel, endpoint: ollamaEndpoint);
builder.AddOllamaEmbeddingGenerator(modelId: embedModel, endpoint: ollamaEndpoint);
var kernel = builder.Build();
var textGen = kernel.GetRequiredService<ITextGenerationService>();
var embedGen = kernel.GetRequiredService<IEmbeddingGenerator<string, Embedding<float>>>();
In a production world, all this information would be in configuration files or possibly have more files instead of just one (it's simplified for clarity).
3.3 - Database Connection
Now comes the part for connecting to the database and making sure everything we need is available.
var dimProbe = await embedGen.GenerateAsync("probe");
var dimensionLenght = dimProbe.Vector.Length;
var tableName = "rag_items";
var createSql = $"CREATE TABLE IF NOT EXISTS {tableName} (\n id TEXT PRIMARY KEY,\n content TEXT,\n embedding vector({dimensionLenght})\n);";
await using (var cmd = new NpgsqlCommand(createSql, conn))
await cmd.ExecuteNonQueryAsync();Just as before, in a production environment, this section would be abstracted away from this process.
3.4 - Data Ingestion
The most complex part now is the ingestion of our files into the vector table.
In this case, we read the file and convert it into chunks to enter into the database:
Console.WriteLine($"Reading and ingesting '{inputFileName}' into table '{tableName}'...");
var text = await File.ReadAllTextAsync(inputFilePath);
var chunks = ChunkText(text, maxChars: 1000, overlap: 100).ToList();
int i = 0;
foreach (var chunk in chunks)
{
var id = $"doc-{i++}";
var emb = await embedGen.GenerateAsync(chunk);
var embStr = ToPgVectorLiteral(emb.Vector.Span);
var upsert = $"INSERT INTO {tableName} (id, content, embedding) VALUES (@id, @content, CAST(@emb AS vector({dimensionLenght})))\n ON CONFLICT (id) DO UPDATE SET content = EXCLUDED.content, embedding = EXCLUDED.embedding;";
await using var cmd = new NpgsqlCommand(upsert, conn);
cmd.Parameters.AddWithValue("id", id);
cmd.Parameters.AddWithValue("content", chunk);
cmd.Parameters.AddWithValue("emb", embStr);
await cmd.ExecuteNonQueryAsync();
}
Console.ForegroundColor = ConsoleColor.Green;
Console.WriteLine($"Ingested {chunks.Count} chunks. Ready for questions.\n");
Console.ResetColor();
static string ToPgVectorLiteral(ReadOnlySpan<float> vector)
{
// Format like: [0.1, -0.2, ...] with invariant culture
var sb = new StringBuilder();
sb.Append('[');
for (int i = 0; i < vector.Length; i++)
{
if (i > 0) sb.Append(',');
sb.Append(vector[i].ToString("G9", CultureInfo.InvariantCulture));
}
sb.Append(']');
return sb.ToString();
}Where we have a ChunkText method that chunks the text:
static IEnumerable<string> ChunkText(string text, int maxChars = 1000, int overlap = 100)
{
if (maxChars <= 0) throw new ArgumentOutOfRangeException(nameof(maxChars));
if (overlap < 0) throw new ArgumentOutOfRangeException(nameof(overlap));
// Simple paragraph-aware chunker with character limit and overlap
var paras = text.Replace("\r\n", "\n").Split("\n\n", StringSplitOptions.RemoveEmptyEntries | StringSplitOptions.TrimEntries);
var current = new StringBuilder();
foreach (var p in paras)
{
var toAdd = p.Trim();
if (toAdd.Length == 0) continue;
if (current.Length + toAdd.Length + 2 > maxChars)
{
if (current.Length > 0)
{
yield return current.ToString();
// create overlap from end of previous chunk
if (overlap > 0)
{
var prev = current.ToString();
var tail = prev.Length <= overlap ? prev : prev.Substring(prev.Length - overlap);
current.Clear();
current.Append(tail);
}
else
{
current.Clear();
}
}
}
if (current.Length > 0) current.AppendLine().AppendLine();
current.Append(toAdd);
}
if (current.Length > 0)
{
yield return current.ToString();
}
}
Ideally, we'd have a library that does this by default. In theory, Microsoft.SemanticKernel.Connectors.PgVector exists, but it is in preview and either doesn't work as expected or is incomplete, so for now these steps are manual. Hopefully, this will change in the future.
3.5 - Creating a Local RAG Chat
Finally, all that's left is to build the chat, where in a continuous loop we’ll keep asking questions. Notice that we query the vector database each time we're asking a question.
Console.WriteLine("Ask a question (empty line to exit):");
while (true)
{
Console.ForegroundColor = ConsoleColor.Cyan;
Console.Write("Question> ");
Console.ResetColor();
var question = Console.ReadLine();
if (string.IsNullOrWhiteSpace(question)) break;
// Retrieve top-k relevant chunks using cosine distance
var embeddedQuestion = await embedGen.GenerateAsync(question);
var ebbeddedQuestionString = ToPgVectorLiteral(embeddedQuestion.Vector.Span);
var searchSql = $"SELECT id, content, (1 - (embedding <=> CAST(@qemb AS vector({dimensionLenght})))) AS similarity\n FROM {tableName}\n ORDER BY embedding <=> CAST(@qemb AS vector({dimensionLenght}))\n LIMIT 4;";
await using var sCmd = new NpgsqlCommand(searchSql, conn);
sCmd.Parameters.AddWithValue("qemb", ebbeddedQuestionString);
var sb = new StringBuilder();
await using (var reader = await sCmd.ExecuteReaderAsync())
{
while (await reader.ReadAsync())
{
var content = reader.GetString(reader.GetOrdinal("content"));
sb.AppendLine("- " + content.Trim());
}
}
var prompt = $@"You are a helpful assistant. Respond strictly based on the provided context.
If the answer is not in the context, reply that you don’t know.
Context:
{sb}
Question: {question}
Answer:";
try
{
var response = await textGen.GetTextContentAsync(prompt, kernel: kernel);
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine("Answer> " + (response?.ToString() ?? "(no answer)"));
Console.ResetColor();
}
catch (Exception ex)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("Error: " + ex.Message);
Console.ResetColor();
}
}
Additionally, we have passed a context to the prompt, and this is the final result:

NOTE: Keep in mind that running these systems locally is somewhat slow, but aside from that, everything works perfectly.
