Llevamos utilizando la inteligencia artificial durante varios años, pero muy pocos nos hemos preocupado en entender cómo funcionan los modelos de lenguaje (LLM). Recuerdas ese momento donde le pediste a la IA que te genere código en C# y en medio de todo el código hay una función que no existe?
En este post, con el que iniciamos el contenido del curso de C# Con IA, veremos tres preguntas que solemos dar por entendidas… ¿pero las entendemos de verdad?
Tabla de contenidos
1 - ¿Por qué la Inteligencia artificial tiene alucinaciones? ¿Bug o funcionalidad?
Para comprender por qué las LLM “alucinan” tenemos que comprender que son modelos diseñados para detectar o predecir las probabilidades de que una palabra siga a otra, bueno no palabras, sino token. Por ello alucina, porque no sabe qué es lo que es cierto o no lo que no. Por lo que podríamos decir que alucinar es una consecuencia del diseño de las LLM.
Obviamente, para implementaciones prácticas, no queremos que la IA alucine ni invente información. Los modelos populares van alucinando menos cada vez, aunque tenemos formas de mitigar estas alucinaciones. Si hacemos preguntas muy específicas la respuesta se centrará únicamente en esos términos, mientras que si son preguntas más ambiguas va a ir rellenando los huecos con lo que le parezca. O incluso la temperatura, que es el parámetro que ajusta la aleatoriedad al elegir el siguiente token, cuanto más baja, más determinista.
Por supuesto, recientemente con la llegada de RAG, que nos permite obligar a recuperar fuentes y citar estaremos mitigando estas alucinaciones.
2 - Puede un LLM saber de dónde saca la información?
Si llevas tiempo trabajando con modelos de lenguaje esta es una respuesta que ha cambiado recientemente. Por defecto un LLM no sabe de dónde ha sacado la información, todo lo que un modelo de lenguaje aprende se difumina en pesos tras el entrenamiento y no lleva información de la procedencia por lo que no podemos saber si lo que estamos leyendo es de una fuente fiable.
Fuente: https://microsoft.github.io/Workshop-Interact-with-OpenAI-models/llms/
Recientemente con la llegada de RAG o de las búsquedas en vivo lo que estamos haciendo es leer documentos o webs donde obligamos a contestar únicamente con lo leído, así que en ese caso, podemos adjuntar la fuente ya que forma parte del contexto de la respuesta.
3 - Qué son los tokens y por qué tenemos un límite de contexto?
Para terminar hablemos de los token, los tokens es como los modelos de lenguaje procesan los textos y cada token es simplemente una secuencia de letras, estos token son las unidades de lectura y escritura. En los idiomas nos regimos por letras, tu no puedes escribir media letra, pues los Tokens funcionan igual para los LLM, no pueden escribir medio token.
Cuando envías un texto a un LLM este texto no se procesa tal cual sino que se “tokeniza”, donde las palabras más frecuentes suelen ser un token, pero palabras más raras o complejas se dividen en varios tokens. Igual que los espacios, que van junto a la palabra que va después del espacio.
Podemos ver un ejemplo en la herramienta de openAI(https://platform.openai.com/tokenizer):
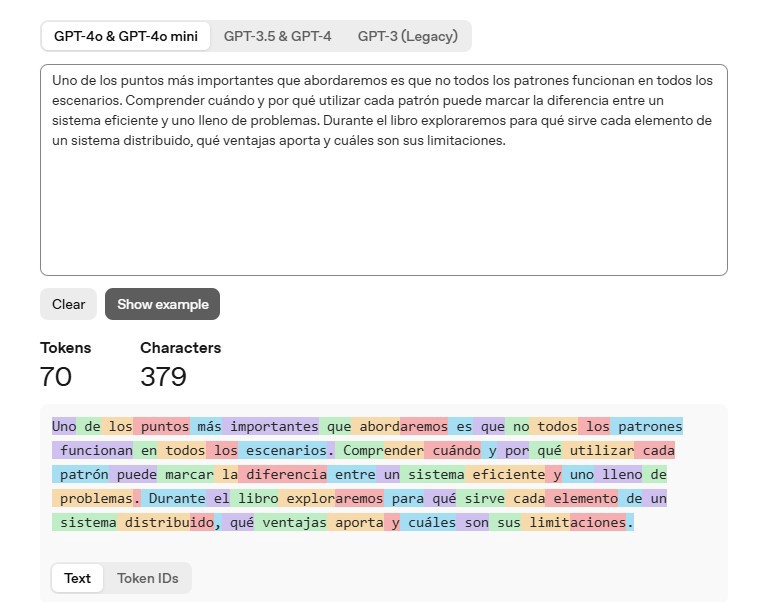
Uno de los puntos más importantes que abordaremos es que no todos los patrones funcionan en todos los escenarios.
Comprender cuándo y por qué utilizar cada patrón puede marcar la diferencia entre un sistema eficiente y uno lleno de problemas.
Durante el libro exploraremos para qué sirve cada elemento de un sistema distribuido, qué ventajas aporta y cuáles son sus limitaciones.Ahí podemos ver la división, como palabras simples como sistema son un único token, mientras que otras como distribuido son dos tokens. Este párrafo en particular sobre mi libro Construyendo sistemas distribuidos utiliza aproximadamente 70 tokens.
El uso de tokens es importante, porque tiene una relación directa con el contexto; Habrás visto en la última presentación de Chat GPT-5 que se mostró un contexto de 400k (k = mil) tokens en la API, mientras que la interfaz de ChatGPT soporta 256k tokens, otras herramientas como claude tiene 200k tokens de contexto. Aunque estas cifras varían por proveedor y cambian con el tiempo es importante tenerlas en cuenta.
3.1 - Qué es el contexto?
Este contexto es la cantidad de tokens que un LLM puede absorber o entender a la vez para predecir el siguiente token.
Como has visto, un párrafo son aprox 70 tokens, así que para llenar 256k o 400k necesitamos muchísimo texto. Por ello, en aplicaciones como chatgpt podemos tener memoria o historial, porque por detrás el sistema añade lo que tiene sobre nosotros al contexto de la conversación actual.
Dentro de la programación, tener este contexto tan grande hace que las LLMs sean capaces de crear aplicaciones pequeñas. Con aplicaciones grandes todavía no funciona bien, precisamente por el límite del contexto. 400k tokens son muchos, pero si te pasas el modelo pierde el contexto o bueno, se corta lo que no quepa (normalmente lo antiguo), y recuerda que son los tokens de entrada junto a los de salida.
Pero claro estos contextos más grandes no vienen gratis, a más contexto más coste y latencia y es que los tokens (junto al contexto) tienen una relación directa al coste de computación, haciendo una pequeña mención a que cuanto más contexto.
Otro efecto que tenemos con los contextos grandes es el riesgo de que la información importante se diluya, ya que la LLM normaliza internamente la atención que cada token va a recibir, luego hay sesgos de posición y por supuesto a más texto más ruido. Por ello se recomienda poner listas numeradas por ejemplo, porque internamente cada punto o petición tendrá el mismo valor en vez de ir balanceando lo que se pide.
Conclusión
He querido utilizar este post como introductorio para la nueva serie dentro de la web, donde aprenderemos a trabajar con IA y C#.
Con estos tres pilares ya estás capacitado para trabajar y comprender el porqué de todo lo que realices con IA.

