This post comes as a result of a bug that was found in a client's software.
To summarize the situation, there were two entries for an item in the database when theoretically there should only be one. After investigating and discovering the bug wasn't in my application, I reported it and was told they couldn’t do anything since the event had been processed twice.
Since it wasn’t my company, I didn’t insist, although I did send them a link to the idempotency Wikipedia page.
Table of Contents
1 - What is idempotency?
In software, idempotency is a technique that allows us to perform an operation multiple times and always obtain the same result.
For example, if we process an event twice, the second execution should not alter the outcome. In programming, we specify a property in an event or request to prevent it from being executed more than once.
For this example, let’s use the Distribt project, since idempotency is very important in distributed systems. Later, we will also see an example of idempotency in REST.
A common example is when you have a product with an inventory of 10 units and you create an order that requires two items. You need to generate an event to decrease the inventory. This action follows the same logic as we saw in the post about event sourcing.
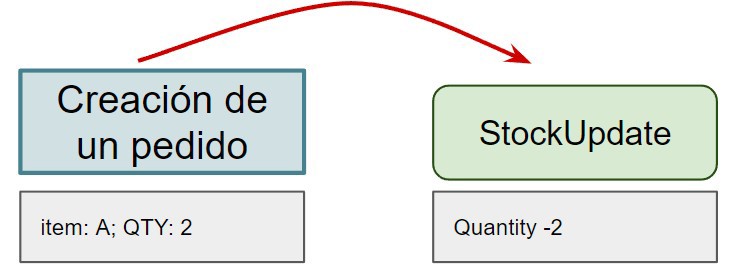
So far so good, but what happens if the system fails and the event is processed twice?
In this case, the current situation would process the event twice, reducing inventory to 6 instead of 8, resulting in an incorrect count. This is because the event has been processed twice, but only one purchase order was created.
This is where idempotency comes into play.
2 - Implementing Idempotency in a System
The first step is to add a property to all your events that carries this unique ID. Names like “IdempotentId” or “messageidentifier” are very common, though of course you can name it whatever you like.
For this example, I am using my Distribt library, and that property is included in the IMessage interface, meaning both integration and domain messages will have it.
public interface IMessage
{
/// <summary>
/// Must be unique;
/// </summary>
public string MessageIdentifier { get; }
/// <summary>
/// Name for the message, useful in logs/databases, etc
/// </summary>
public string Name { get; }
}When creating messages, a GUID is automatically assigned to this property.
Personally, automating this with a property you know won’t be duplicated is my favorite choice. Technically, you could use the ID or a combination, but anything you define “manually” runs the risk of being repeated. However, if you can guarantee it’s a unique key, you can use whatever you want.
private static IntegrationMessage<T> ToTypedIntegrationEvent<T>(T message, Metadata metadata)
{
//The first parameter is the message identifier 👇
return new IntegrationMessage<T>(Guid.NewGuid().ToString(), typeof(T).Name, message, metadata);
}
Now all events have the property assigned with a different value.
Note that idempotency won’t prevent a bug from generating two simultaneous events, as technically those are two different events. What idempotency does prevent is the same event being executed multiple times.
Finally, what you need to do on the consumer side is check whether that event has already been processed, and if so, act accordingly.
Idempotency is very popular in distributed systems, but I also personally recommend using it in APIs in certain scenarios to avoid the same HTTP request being executed twice.
If you’re using an HTTP call, you will normally send the IdempotentId as a header, although every system is different.
3 - How to Approach Creating an Idempotent System
When building a system, there are several things to keep in mind.
You should identify whether it’s a synchronous system (HTTP calls) or an asynchronous system (distributed system), as the available actions depend on the type of system you’re using.
The main thing is to know when a call or event has already passed through the system. There are multiple ways to handle this, I’ve seen all kinds of approaches.
One solution is to create a table with the IdempotentId as the primary key and a column containing the full event. Everything else is optional: a second column with the date and time, a fourth with the operation status, and a last one with the process result.
This kind of table can reside in a cache like Redis, in a database, or even in memory, though the latter is probably not the best option for production.
If you’re in a distributed system, you could simply store the ID, as you won’t need to return any information.
The status field is also optional, and maintaining it requires additional work.
Next comes an explanation about the date and time field. Some people will say saving all information is good, while others will argue against it. In reality, this is called TTL (time to live), and many businesses and systems retain data for 24 hours, meaning that if an event arrives after 48 hours, it will be processed again.
Whether to store IDs or even the events themselves indefinitely depends not only on your domain but also on the economic aspect, since distributed systems with lots of messages can be costly.
My recommendation is to store them for 24 hours or even a week, but no more than that.
Now comes the main difference between a synchronous and an asynchronous system.
If you have an asynchronous system where no one is waiting for a response, you can simply end the process there: check if the ID is already in the database, and if it is, terminate the process.
3.1 - Idempotency in Synchronous Systems (REST)
In a synchronous system, things change because the caller expects an immediate response.
At this point, you have two options.
The first is to fail the second call (and all subsequent calls):
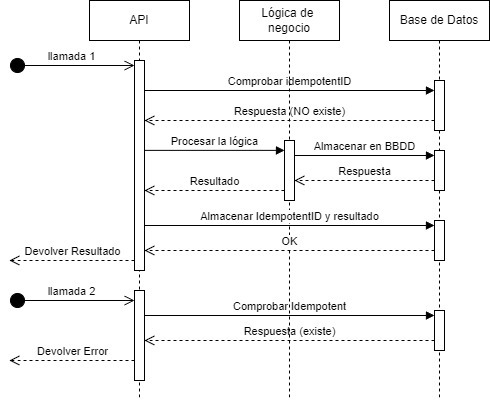
At first glance, this might seem the most logical since the second call is obviously erroneous and should not occur.
However, in the real world, that second call often happens because whoever is sending the information has no clue what happened to the first one, whether due to a bug, a network failure, etc. So, in this case, the most recommended approach is to respond to the second call with the result of the first.
This means you do need to store the result temporarily. But by doing so, you make things much easier for the client, since the system is much simpler and easier to manage. If you don’t return the result, you’ll have to create another system so users can retrieve whatever it is they’re looking for.
For a purchase order, simply return the ID.
This way, you ensure the API behaves more consistently.
