In this post, we will see what GraphQL is, how we can integrate it in C#, and whether it's worth using in a microservices environment.
Index
We will see the code inside the Distribt Course on GitHub, which has a separate branch called GraphQL-Example.
1 - What is GraphQL?
In short, GraphQL is an application-level query language that allows users or clients to specify exactly what information they want to receive from a service.
GraphQL resides in your application's presentation layer and is not just an interface but the entry point. In other words, it is an alternative to REST.
1.1 - Example of using GraphQL
To give an example, let's compare REST and GraphQL, since I believe most people are more familiar with REST. Technologies are always easier to understand with an example.
For the demonstration, let's go to the code of our distributed systems course, where we have an endpoint to read products by id:
app.MapGet("product/{productId}", async (int productId, IProductsReadStore readStore)
=> await readStore.GetFullProduct(productId));
Here we are returning a product built as follows:
public record FullProductResponse(int Id, ProductDetails Details, int Stock, decimal Price);
public record ProductDetails(string Name, string Description);
But often, the description, or even the stock, isn't relevant; all we care about is the name, which means we're sending a lot more data over the network than necessary.
If you have a small app that isn't heavily used, this usually isn't a problem. But when you have thousands of requests per minute and your returned objects have dozens of properties, your cloud bill starts to add up fast.
This is where GraphQL comes in: it allows us, from the client side or the consuming system, to specify which properties we want returned, and the rest are omitted.
NOTE: In REST, this is possible with OData.
1.2 - GraphQL functionalities
When you use GraphQL, you can both query and modify data, which are called mutations.
I won't talk much about the query part, because it's GraphQL's main strength. Personally, I'm not a big fan of doing mutations with GraphQL, but since it's possible, we'll see how to implement them.
In the workplace, I've worked with GraphQL quite a bit when I was using Ruby and, honestly, I've never worked professionally in .NET with it. But since it's a technology agnostic of the language you use, I think it's great to explain and understand it.
1.3 - The GraphQL schema
When you work with GraphQL, every microservice that will use or has integrated GraphQL will publish a schema. This schema is basically the API definition, including properties, types, and relationships between them.
When a client makes a call to a service through GraphQL, the schema will fully validate the call for correctness.
2 - Implementing GraphQL in C#
Let's move on to the hands-on part, where we'll see how to add GraphQL to our applications. In my case, I'm using the same project as before, and what we need to do is very simple: install the following NuGet packages:
GraphQLGraphQL.Server.Transports.AspNetCoreGraphQL.SystemTextJson(NOTE: If you use Newtonsoft, there is GraphQL.NewtonsoftSerializer)
You'll need these three packages in all projects where you want to integrate GraphQL. In our specific case, we'll start with Products.API.Read, so the first thing we'll see is queries with GraphQL.
2.1 - Generate GraphQL Schema in C#
The very first step is to generate the schema for what we want to expose via GraphQL. To do this, we'll create a new class that inherits from GrapQL.Types.Schema:
public class ProductReadSchema : GraphQL.Types.Schema
{
public ProductReadSchema()
{
}
}With this, we've generated the schema. Obviously, it has no functionalities yet, but it's available. So, let's add GraphQL to the API configuration. In program.cs, add GraphQL to the dependency container:
builder.Services.AddGraphQL(x=>
{
x.AddSelfActivatingSchema<ProductReadSchema>();
x.AddSystemTextJson();
});And then add the GraphQL middleware:
app.UseGraphQL<ProductReadSchema>();
Now, just with that, the app already generates the GraphQL Schema. Even though it's empty, what we need to do is add queries and mutations.
Additional point:
If you want to see the content of the schema.graphql file, just like Postman does when integrating, you can do so using the "IntrospectionQuery". In Postman (or any similar app), create a new HTTP POST request, and in the body, select GraphQL and paste the content from the following link. I put it in a link because it's very long.
If you want a shorter version, you can create an endpoint that prints the schema:
app.MapGet("graphql-schema", (ProductReadSchema readSchema)
=>
{
var schemaPrinter = new SchemaPrinter(readSchema);
return schemaPrinter.Print();
});
In its current state, it returns nothing, but in the next section, we'll include a query, and this would be the result:
schema {
query: ProductQuery
}
scalar Decimal
type FullProductResponse {
id: Int!
details: ProductDetailsType
stock: Int!
price: Decimal!
}
type ProductDetailsType {
name: String!
description: String!
}
type ProductQuery {
product(id: Int): Product
}As we can see, we have the schema and the types it uses.
2.2 - How to perform a query in GraphQL?
GraphQL is completely agnostic of the language we use, which implies some rules or considerations.
The first and most important is that the types we return from our original REST API DO NOT WORK for GraphQL, we must specify specific types inheriting from ObjectGraphType<T> where T is the inner type. Also, in the constructor, we must map from one type to the other using Field.
The good part is that 99% is done automatically, at least with Copilot. Here is what the mapping of ProductDetails and FullProductResponse looks like:
public class ProductType : ObjectGraphType<FullProductResponse>
{
public ProductType()
{
Name = "Product";
Field(x => x.Id);
Field(x => x.Details, type: typeof(ProductDetailsType));
Field(x => x.Stock);
Field(x => x.Price);
}
}
public class ProductDetailsType : ObjectGraphType<ProductDetails>
{
public ProductDetailsType()
{
Field(x => x.Name);
Field(x => x.Description);
}
}As we can see, mapping is as simple as specifying each property with Field() and Name, which overrides the name to use.
If you don't specify the name in ProductType, the object in the Schema will be named ProductType instead of FullProductResponse (you can name it whatever you want).
NOTE: Try to have unique type names throughout your application.
Once you have the types, you must create the Query. Here you should keep several things in mind.
The first is that GraphQL objects are Singletons, so if you're injecting anything as scoped, it won’t work. So you should access services through the context inside ResolveAsync, where you can do a GetRequiredService<T>.
In my case, I'm injecting the use case of reading a product by Id. and the response type for this use case is FullProductResponse.
Therefore, we must specify the Field to return, as well as the arguments we will receive and, finally, read the argument and pass it to the use case:
public class ProductQuery : ObjectGraphType<object>
{
public ProductQuery()
{
Field<ProductType>("FullProductResponse")
.Description("Get a full product by ID")
.Arguments(new QueryArguments(new QueryArgument<IntGraphType> { Name = "id" }))
.ResolveAsync(async ctx =>
{
var id = ctx.GetArgument<int>("id");
IGetProductById getById = ctx.RequestServices!.GetRequiredService<IGetProductById>();
return await getById.Execute(id);
});
}
}Now, we just need to inject the Query we just created into the schema object:
public class ProductReadSchema : GraphQL.Types.Schema
{
public ProductReadSchema(ProductQuery query)
{
Query = query;
}
}
And now, if we run the app, we can see in Postman (or any similar app) that it is reading the schema and we can make queries:
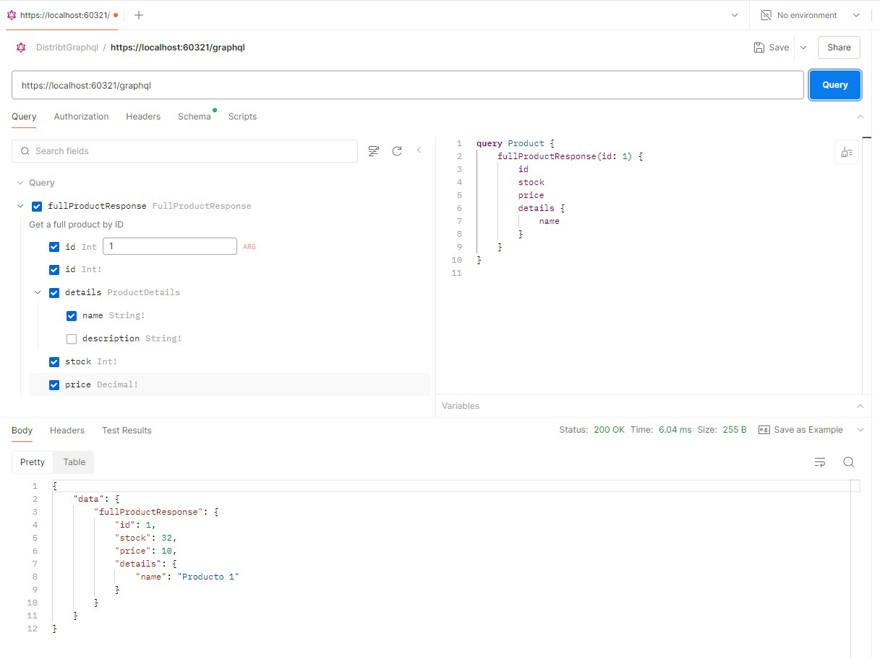
You can see in the query itself which elements you want returned. In this particular case, we are not requesting description, so it's not returned.
2.3 - Creating mutations with GraphQL
The process for creating mutations is very similar to that for queries: we need our schema and types. In our case, we will create the mutation for Distribt.Services.Products.Api.Write, which has an endpoint to create products and receives a CreateProductRequest:
public record CreateProductRequest(ProductDetails Details, int Stock, decimal Price);
public record ProductDetails(string Name, string Description);
These types must be converted to GraphQL types:
public class ProductDetailsType : InputObjectGraphType<ProductDetails>
{
public ProductDetailsType()
{
Name = "ProductDetails";
Field(x => x.Name);
Field(x => x.Description);
}
}
public class CreateProductRequestType : InputObjectGraphType<CreateProductRequest>
{
public CreateProductRequestType()
{
Name = "CreateProductRequest";
Field(x => x.Details, type: typeof(ProductDetailsType));
Field(x => x.Stock);
Field(x => x.Price);
}
}
public class CreateProductResponseType : ObjectGraphType<CreateProductResponse>
{
public CreateProductResponseType()
{
Name = "FullProductResponse";
Field(x => x.Url);
}
}
There are a couple of differences from the previous types: in this case, input types are InputObjectGraphType. We also have an additional output type.
Now, let's create the mutation.
As with the query, we need to specify a Field with its name, the arguments it will receive, and what the mutation will do, in our case, call createProductDetails and insert the product:
public class ProductMutation : ObjectGraphType<object>
{
public ProductMutation()
{
Field<CreateProductResponseType>("CreateProduct")
.Description("Create a product in the system")
.Arguments(new QueryArguments(new QueryArgument<CreateProductRequestType> { Name = "product" }))
.ResolveAsync(async ctx =>
{
var product = ctx.GetArgument<CreateProductRequest>("product");
ICreateProductDetails createProduct = ctx.RequestServices!.GetRequiredService<ICreateProductDetails>();
return await createProduct.Execute(product);
});
}
}
Finally, we must update the schema to include the mutation.
NOTE: In GraphQL, you can't have schemas that contain only mutations, I'm not entirely sure why, but you must create a Query object too. Here's the schema:
public class ProductWriteSchema : GraphQL.Types.Schema
{
public ProductWriteSchema(ProductMutation mutation, ProductQuery query)
{
Mutation = mutation;
Query = query;
}
}
public class ProductQuery : ObjectGraphType<object>
{
public ProductQuery()
{
Field<StringGraphType>("info")
.Resolve(_ => "Hello World");
}
}
And if we've added both the middleware and GraphQL to the dependency container in program.cs, as well as the schema endpoint, we should see the following:
schema {
query: ProductQuery
mutation: ProductMutation
}
input CreateProductRequest {
details: ProductDetails
stock: Int!
price: Decimal!
}
scalar Decimal
type FullProductResponse {
url: String!
}
input ProductDetails {
name: String!
description: String!
}
type ProductMutation {
createProduct(product: CreateProductRequest): FullProductResponse
}
type ProductQuery {
info: String
}Which means you can go to Postman and try to add a product:
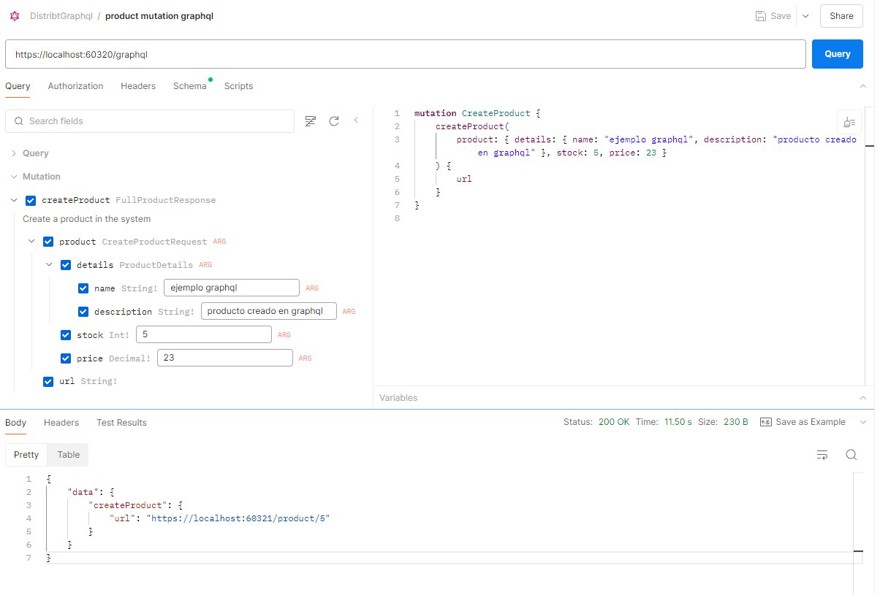
2.4 - Other GraphQL functionalities
GraphQL doesn't end here, it has more features, and I’ll show the ones I consider most important:
2.4.1 - Multiple Queries or Mutations in a Single Schema
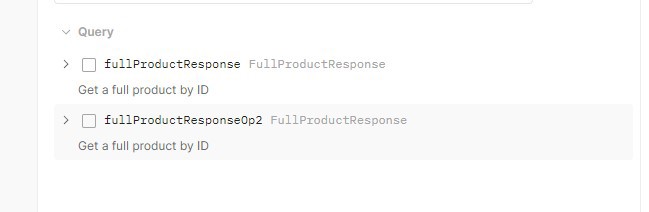
You can only have one query and one mutation per schema. What you usually do is have a class, in our case "ProductQuery", and inside this "ProductQuery" you can have multiple different queries or mutations:
public class ProductQuery : ObjectGraphType<object>
{
public ProductQuery()
{
Field<ProductType>("FullProductResponse")
.Description("Get a full product by ID")
.Arguments(new QueryArguments(new QueryArgument<IntGraphType> { Name = "id" }))
.ResolveAsync(async ctx =>
{
var id = ctx.GetArgument<int>("id");
IGetProductById getById = ctx.RequestServices!.GetRequiredService<IGetProductById>();
return await getById.Execute(id);
});
Field<ProductType>("FullProductResponseOp2")
.Description("Get a full product by ID")
.Arguments(new QueryArguments(new QueryArgument<IntGraphType> { Name = "id" }))
.ResolveAsync(async ctx =>
{
var id = ctx.GetArgument<int>("id");
IGetProductById getById = ctx.RequestServices!.GetRequiredService<IGetProductById>();
return await getById.Execute(id);
});
}
}
Note: In this case, they are the same, but the important thing is to see how you can have more than one in the schema:
2.4.2 - Multiple objects in a single query
With this particular code, I don't have an example, but let's assume a couple of things: imagine that in the product query, instead of returning the stock, we're returning an Id. In that case, we'd have to query another use case. You can also do that directly from the type itself using Resolve:
public class ProductType : ObjectGraphType<FullProductResponse>
{
public ProductType()
{
Name = "FullProductResponse";
Field(x => x.Id);
Field(x => x.Details, type: typeof(ProductDetailsType));
Field(x => "itemsInStock")
.Resolve(ctx=> 👈
ctx.RequestServices!.GetRequiredService<IProductStock>()
.GetStock(ctx.Source.StockID));
Field(x => x.Price);
}
}
Note: This Resolve can also help us map objects when grouping or changing values, etc.
2.4.3 - GraphQL Request Pipeline
The request pipeline is a very important piece in C#, in my opinion, it's one of the big changes from the old .NET Framework.
But let’s continue: at this point, we can use middlewares with no problem, and where it gets trickier is with filters. However, some, like authentication, are included in the GraphQL library:
public class ProductQuery : ObjectGraphType<object>
{
public ProductQuery()
{
Field<ProductType>("FullProductResponse")
.Description("Get a full product by ID")
.Arguments(new QueryArguments(new QueryArgument<IntGraphType> { Name = "id" }))
.ResolveAsync(async ctx =>
{
var id = ctx.GetArgument<int>("id");
IGetProductById getById = ctx.RequestServices!.GetRequiredService<IGetProductById>();
return await getById.Execute(id);
})
.Authorize() 👈
.AuthorizeWithPolicy("policy1") 👈
.AuthorizeWithRoles("role"); 👈
}
}
2.4.4 - HotChocolate library for working with GraphQL
Finally, the GraphQL request pipeline works similarly to how it does in C#.
If you're a bit familiar with GraphQL in .NET, you may have wondered why I haven't used HotChocolate in the implementation.
The reason is very simple: although HotChocolate includes projections, filters, and middlewares that make development easier, to me, it's much more important to understand the mechanics behind the abstraction, and the concepts behind it, before understanding an abstraction that is more likely to change.
If you want us to explore this library on the channel, leave your comment below!
3 - GraphQL federated
The real value of GraphQL is using it with GraphQL federation, which is an architectural pattern that allows you to combine multiple GraphQL endpoints into a single one. When working with microservices, this is a very powerful functionality because any client, whether it's the website, the mobile app, or even third-party apps, will query a single endpoint for all the information it needs.
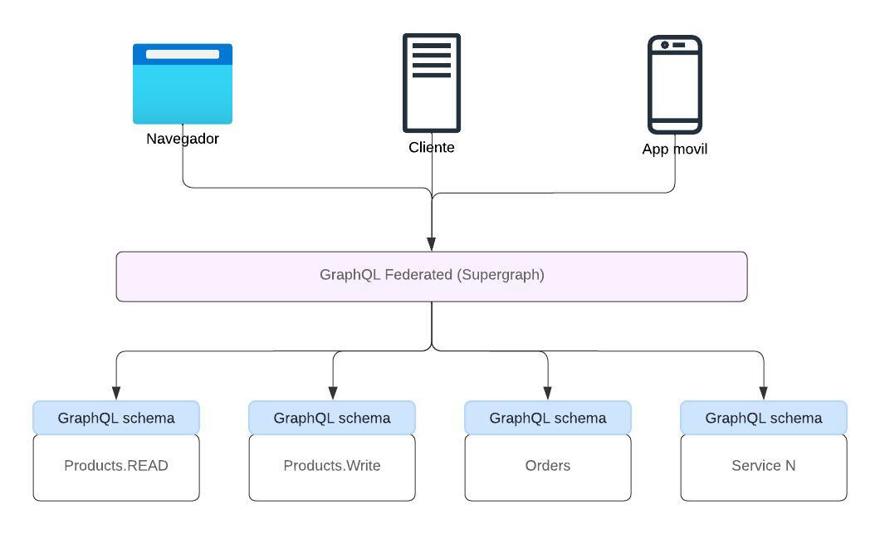
How it works is simple.
Each microservice, in our case the orders service and the product read and write services, generates a GraphQL schema. We call this schema a subgraph, and it is specific to each microservice.
Now comes the integration step, which is usually done through a gateway, similar to an API Gateway. Basically, it combines the subgraphs of the different services into a single one, which we'll call a supergraph.
Once you have your gateway/SuperGraph set up and receive a call, the supergraph knows where to retrieve the information from, allowing a single call from the client side and returning all the necessary information, even if it's stored in multiple microservices.
3.1 - Implementing GraphQL federation
Implementing a supergraph isn't as simple as it seems. When I worked professionally with GraphQL, we used Apollo Federation, which is a third-party service. I've been looking for alternatives because, in my opinion, it was pretty expensive. Here are some alternatives I found:
- Apollo GraphQL https://www.apollographql.com/
- Wundergraph OOS https://wundergraph.com/
- Hive https://the-guild.dev/graphql/hive
- Inigo https://inigo.io/
- Graphbase https://grafbase.com/
Whichever you choose, they all require management and architecture configuration, especially if you do it locally. All of them have a free tier, which is enough for a hobby app, but for businesses you'll need the enterprise plan.
If you want me to implement a federated layer with GraphQL and C#, leave your comment below or on the YouTube video, and if there's enough interest, I'll create it.
4 - Should I use GraphQL?
From my point of view (and if you follow me, I always joke that GraphQL is fine for messing around, but for serious development, not so much), I'll explain where my opinion comes from.
This doesn't mean my opinion is the only truth. In fact, there's a scenario where GraphQL excels: eliminating backend-for-frontend. Maybe I should do a video just on this. Summing up, backend-for-frontend is when, from your orders service, you respond with information from another microservice, such as the product name, image, etc.
What you're doing is accommodating the backend to perform operations needed only by the frontend. So both services, orders and products, are tightly coupled.
With GraphQL, you don't need to do this anymore. If you use a supergraph/federated layer, it is that layer which does all the necessary queries.
This is a double-edged sword and the reason why, by default, I don't recommend it. It also depends on the system, it's not the same to have a system receiving 3 requests per minute or 50 thousand.
Why? It's quite simple. In the aforementioned scenario, GraphQL is perfect, a dream come true. But what happens with a list? Instead of returning just one order with all its products, say we return all orders from the past month. Let's say we have 10,000 orders and, on average, three products per order, 30,000 products.
Assuming the orders backend only returns the product ID, GraphQL will make a query for each product to the products API, that means 30,000 queries, resulting in 30,000 database connections and a massive bottleneck at that particular time, plus possibly thread pool starvation.
On the other hand, if you don’t have GraphQL, you have two options: one, make a call for each product, just like GraphQL would do; or, collect all the product IDs (maybe 100 or 200 unique ones) and make a single call to the backend, which will connect just once to the database.
So, as with everything in programming, knowing whether to use GraphQL depends on your scenario. The key is to know when it's a good fit, why, and what consequences or benefits it brings. For some cases, this feature is impressive, but for others, not so much.
Apart from that, it brings additional features that can be considered as benefits.
GraphQL forces you to have types. In many languages, types are not necessary, Ruby, for instance, is typeless, but it's very common to have a GraphQL layer, which forces type definitions, at least for the client. In my opinion, this is an advantage, as it forces you to have a robust and solid API, which long-term is better.
