In C#, we use a wide range of architectures, designs, and patterns. One of the most popular architectures is hexagonal architecture, which we also call ports and adapters due to its structure.
1 - What is hexagonal architecture?
We call it hexagonal architecture because what we have is a central core, where the business logic resides, and then surrounding it we have another layer made up of the ports and adapters that let us interact with external services, whether they be services from other companies, a database, the file system, or the user interface itself.
A key aspect of hexagonal architecture is that the core (or whatever you want to call it), the business logic, doesn't know anything about how the data is processed or received; instead, all the rules and processes are in one place. This makes testing and development much simpler.
Now it's time to explain ports and adapters.
We can think of ports as interfaces that we inject into our business logic. These interfaces contain the contracts the logic will use.
So, an adapter is nothing more than the abstraction or implementation of such a port, with the implementation being completely transparent and irrelevant to the use case.
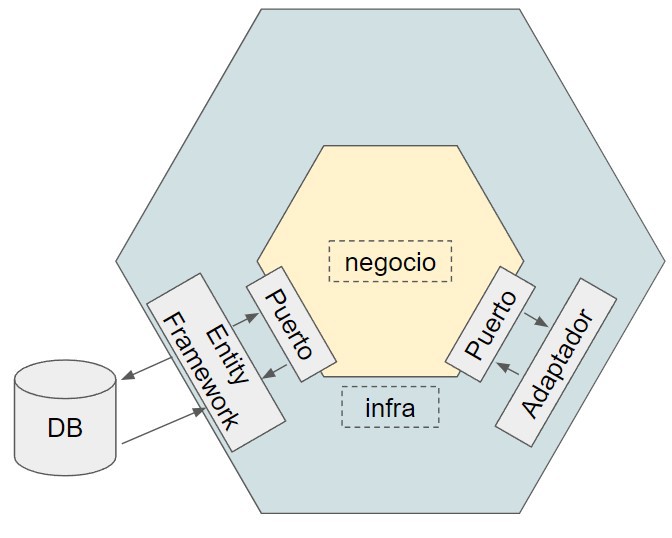
In my opinion, using the terms "ports and adapters" complicates things when, in reality, it means interface and implementation. But anyway, minor details.
2 - Features of hexagonal architecture
As with everything in programming, there are benefits and drawbacks.
From my point of view, there are two drawbacks:
The first is obvious: to implement Hexagonal properly, you have to create ports and adapters, which leads to a lot of code. Another important point is that you need to make a clear separation between Entities and DTOs.
For example, I've seen the following: we read a user from the database using Entity Framework and convert that user into a DTO, modify the DTO by changing a value and save it again. However, you're sending a DTO to your abstraction (adapter) for the database and not the Entity Framework entity, so you need to read the entity again in order to save it.
Additionally, this particular company returned the updated user to the caller as a response, which means yet another conversion (although you could return an IUser interface).
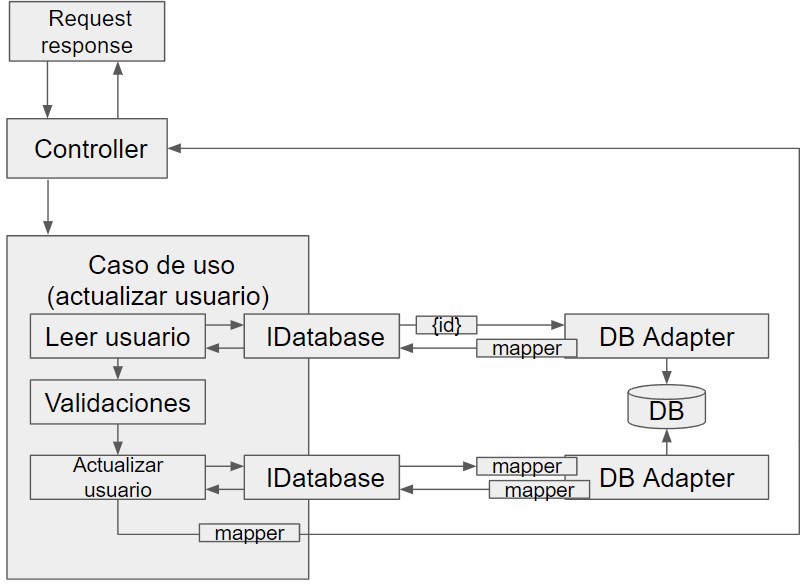
I think this example clearly illustrates what I mean; here, there are clearly "extra" steps, when this particular process can be done in just four lines of code.
Another negative point, though it depends more on the company you work at, is that all the business logic is located in a single file. They create a file called UserRepository, and all the logic related to the user is there. The problem is that all the actions, reading, updating, deleting, validating, etc., are in the same file.
Note: in this case, UserRepository is the user logic, not data access... Yes, naming conventions deserve a separate post.
And that's if it's even split up, because often the whole app is in just one file: it would be AppRepository and all user-related logic in there. If your app is about books, everything related to books would be in that same file. In the end, you have a file that's three thousand lines long, which could be split up quickly and easily, but no one wants to do it for fear of breaking something.
If instead of having everything in a single file we separate the use cases, we'll drastically improve the application, since we're already separating responsibility with ports and adapters, so why not separate use cases as well. When the time comes for another developer to make a change or implement something new, they only have to worry about the feature they're working on.
Putting all of this together, we can see that testing is very simple, or at least it seems simple at first, since all your dependencies are behind interfaces, which means you can easily use a test double.
Testing hexagonal is very straightforward as long as we keep use cases separated, as you'll only inject the ports (interfaces) you need for each use case. However, if you have a God Object, you'll be injecting lots of unused ports for every use case.
