Qué sucede cuando utilizamos Eventos dentro de nuestro sistema después de guardar la información en la base de datos pero el evento falla y no se propaga. Esta es una pregunta que recibí en uno de mis vídeos recientemente y aquí vamos a tratarlo.
Índice
1 - Contexto del problema
Por situarnos vamos a ponernos que estamos creando un sistema el cual tiene que almacenar datos en la base de datos y de ahí enviar un evento, puede ser cualquier tipo de aplicación o sistema o incluso ser parte de un proceso dentro de una SAGA por ejemplo.
En este escenario tenemos dos acciones
1 - Actualizar la base de datos
2 - Enviar el evento
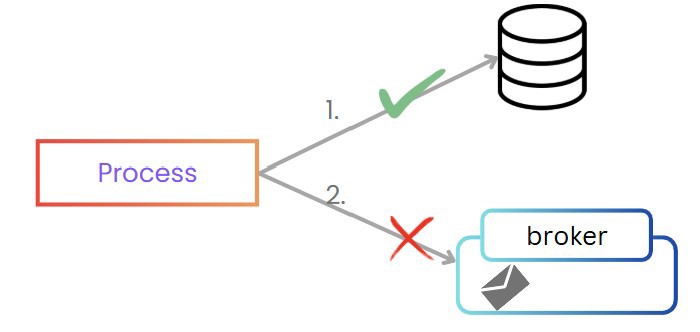
Y da igual en qué orden suceda, si el primer proceso funciona, nada garantiza que el segundo proceso vaya a funcionar.
Una posible solución sería añadir un fallback, si enviar el evento falla, deshacemos el cambio en la base de datos. Pero esta solución no es realista, porque entonces que sucede si el proceso en si peta.
Otra opción es implementar 2PC (two-phase commit) pero ni todas las bases de datos soportan esta funcionalidad, ni los message brokers lo hacen, así que la podemos descartar, por lo menos de forma automática.
Entonces, ¿cómo podemos garantizar que ambas acciones suceden?
2 - Patrón outbox | Outbox Pattern
Una de las soluciones más comunes es el patrón Outbox, en este patrón tenemos un par de pasos extra en el proceso. De primeras, nuestro proceso de insertar o modificar datos de la base de datos, no solo hace eso, sino que también inserta en una tabla llamada outbox_table_name el contenido del evento que va a ser enviado, en este caso, introducimos el evento entero.
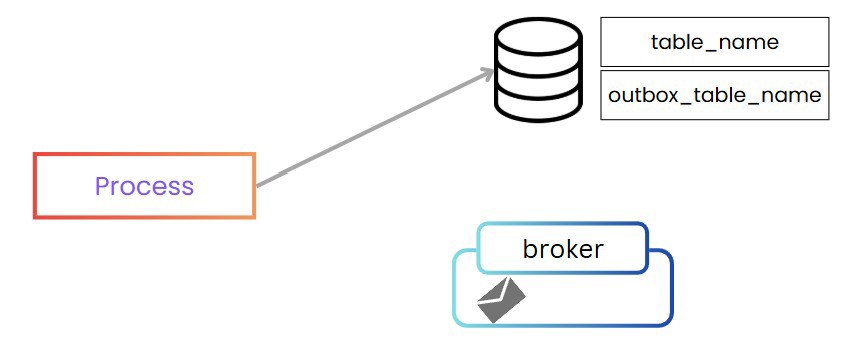
Por lo tanto ambas acciones suceden en una única transacción dentro de la misma base de datos.
Posteriormente, necesitamos una aplicación, la cual puede estar ejecutándose cada minuto o cada X segundos. El trabajo de esta aplicación consiste en leer dicha tabla, publicar el evento en el message broker y finalmente actualizar el registro como que ha sido enviado.

Puedes pensar qué pasa si la aplicación falla después de enviar el evento y antes de guardar la actualización de que ha sido enviado. En ese caso debemos asegurarnos de que los eventos que generamos son idempotentes por lo que el consumidor si le llega un evento que ya ha recibido lo descatará y problema solucionado.
NOTA: esta aplicación extra también puede ser un worker en la aplicación principal.
3 - Patrón escucharse a uno mismo | listen to yourself pattern
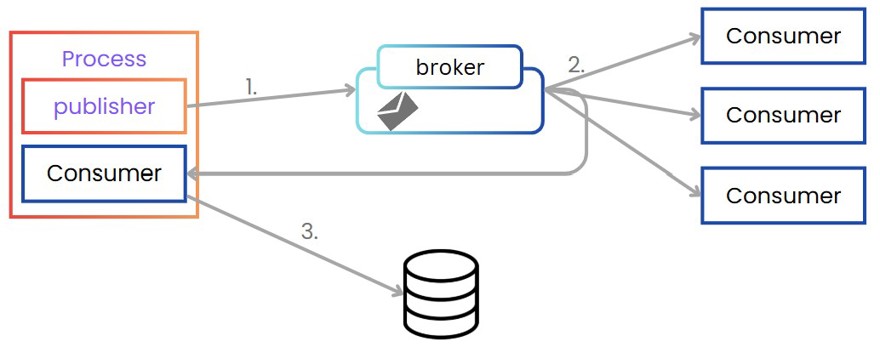
Otra alternativa, menos popular es es el patrón Listen to yourself, el cual consiste en primero de todo generar un evento, el cual será escuchado por los consumidores y uno de esos consumidores es la propia aplicación. Y será este consumidor dentro de la aplicación el sistema que actualice la base de datos.
Este escenario también tiene sus problemas ya que puede generar una race condition, donde nuestro consumidor “propio” por llamarlo de alguna manera, el que genera el evento, tiene un fallo y no inserta los datos en la base de datos. A su vez, otro consumidor ha recibido el evento y quizá quiera buscar algo en la base de datos. En este escenario la llamada a la base de datos fallará porque no tienes en el sistema la información debido a que el consumidor “propio” ha fallado.
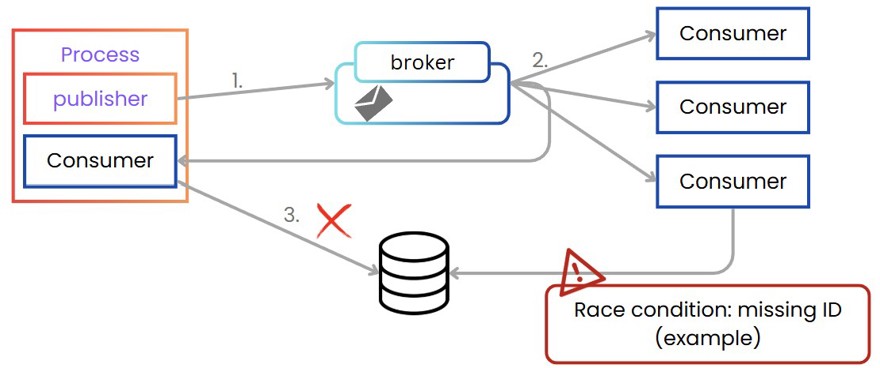
Por no mencionar que los eventos son siempre acciones del sistema que han sucedido, y en este caso, no estamos realizando esa acción. Por lo que tenemos otro problema. Una de las soluciones es, igual que vimos en el post de CQRS generar un comando o un evento de dominio, estos comandos son escuchados únicamente por un único consumidor, el cual actualizará la base de datos de lectura en el caso de tenerlas separadas, y genera los eventos que son escuchados por el resto del sistema.
Antes de pasar al punto final donde daré mi experiencia puedesd dejar en los comentarios la tuya sobre este tipo de patrones! Ya que aprender de las experiencias de otros siempre es muy válido.
4 - El uso real en empresas para garantizar consistencia
En el caso de la implementación de estos mecanismos en empresas varía mucho, no solo dependiendo de en qué tipo de empresa estemos trabajando, sino en que parte de la misma o del sistema.
El motivo es simple, en circunstancias normales e ideales, ni la base de datos, ni el message broker/colas/bus va a fallar, lo que significa que no tener este tipo de sistemas que garanticen que ambas acciones suceden no es un gran problema.
Por ejemplo, si tenemos un servicio que actualiza los detalles de un producto, como el nombre, la descripción o las imágenes.
La base de datos se actualiza pero el sistema de evento falla, lo que quiere decir que cualquier otro sistema que necesite esa información seguirá teniendo la información antigua.
Si esto sucede y el usuario se da cuenta, lo más normal es que vuelva a intentar hacer el cambio o contacte a soporte. Aquí tenemos que evaluar si el gasto de infraestructura, configuración y desarrollo, merece la pena en comparación a un 0.1% del tiempo que el mensaje bus va a estar caído durante el año.
Porque no es lo mismo ese sistema que otro que cobre los pagos con una tarjeta de crédito o incluso que actualice el stock de nuestras unidades. En el caso de un control de inventario si que es importante garantizar que los eventos suceden ya que de otra forma podemos vender (y por tanto cobrar) productos a los clientes de los cuales no tenemos stock y puede ser un problema gordo.
Ni que decir tiene en el caso de cobrar pagos, garantizar que estos eventos suceden y que solo se procesan una única vez es crucial para el sistema.
Como podemos ver, el uso de estos patrones depende de que parte del sistema estemos tocando y lo crítica que sea.

