Cuando empezamos a crear sistemas distribuidos y buscamos información en internet un montón de términos nuevos empiezan a aparecer. Uno de ellos es CQRS el cual vamos a ver hoy.
Índice
1 - Qué es el patrón CQRS?
CQRS es un patrón de diseño de software que nos muestra cómo separar la lógica de nuestras aplicaciones para separar las lecturas de las escrituras.
Y esto aplica tanto al código o la ejecución del programa como a la ubicación de los datos.
Las siglas CQRS vienen del inglés y significan “Command query responsibility segregation”; Lo que viene a significar separación en la responsabilidad de las lecturas y los comandos (escrituras/actualizaciones).
El patrón CQRS es un patrón que no habíamos visto antes de la llegada de los microservicios ya que lo más normal era tener un monolito que lo hacía todo, incluido el conectarse a una única base de datos, pero en el mundo actual, las arquitecturas distribuidas estan empezando a coger popularidad.
1.1 - Ventajas de CQRS
El uso del patrón CQRS nos trae muchas ventajas pero nos podemos centrar principalmente en la escalabilidad de forma independiente.
Ello quiere decir que podemos escalar una parte de la aplicación en concreto. pongamos un ejemplo.
En el caso de tener productos, los comandos serán crear el producto y actualizarlo, mientras que las queries será leer dicho producto.
Si lo pensamos fríamente, cuando consultamos páginas webs, estamos entrando y saliendo de productos constantemente, te metes en una tienda y miras 45 productos de ahí descartas la mitad y vuelves a mirarlos todos para seguir con tu investigación.
Y así hasta que finalmente compras tu producto.
En el proceso de selección hemos hecho un montonazo de lecturas, mientras que una única modificación, y eso si hemos llegado a comprar el producto.
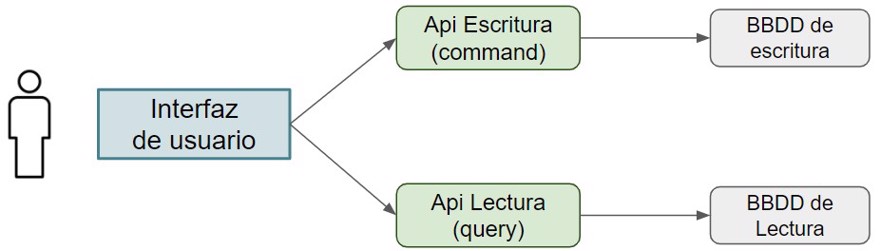
Si este escenario lo escalamos a miles o incluso millones de usuarios que acceden a nuestra tienda web podemos ver rápidamente los beneficios de implementar CQRS.
Así que si vemos que las web empieza a ir lenta, siempre podemos ampliar los recursos de la máquina donde ejecutamos la lectura o ampliar el número de pods en kubernetes detras de una api gateway, etc.
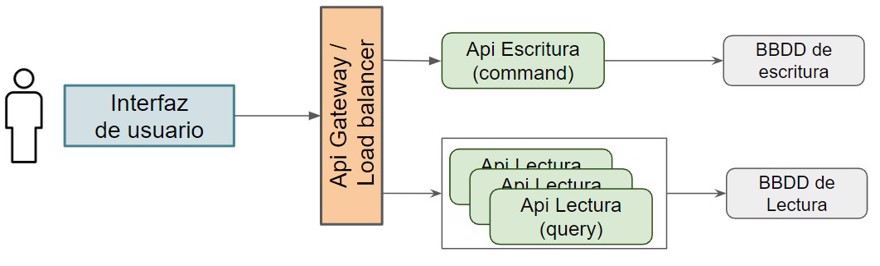
Cabe destacar cuatro puntos muy importantes que condicionarán la implementación del patrón.
- El uso de CQRS viene muy ligado al uso de
Event Sourcingen la base de datos de escritura. Pero veremos qué esEvent Sourcingen otro post, ya que son diferentes patrones, aunque muchas veces se explican juntos (junto a DDD)- Nota: las bases de datos de escritura/lectura pueden estar separadas físicamente o no, dependerá del caso de uso/carga.
- Hay que sincronizar la base de datos de escritura con la de lectura para que no haya ninguna información diferente. Por ello deberemos hacer uso de un service bus.
- Si el proyecto no es muy grande, o se espera el mismo nivel de lecturas que de escrituras, se suele hacer todo en el mismo código a través de
MediatR(en c#) como service bus en memoria ya que administrar múltiples microservicios tiene su complejidad adicional y no siempre es rentable. - En la parte de lectura, tenemos dos opciones, mantener copias de las tablas o tener ya preconstruido lo que necesita el usuario, así a la hora de hacer “get” simplemente son consultas por ID casi instantáneas.
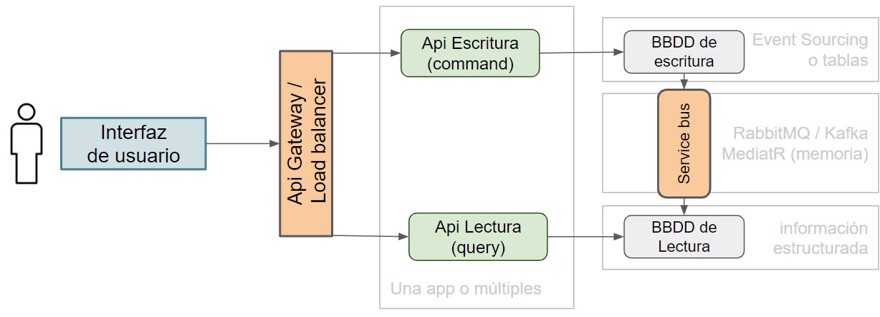
La elección de los casos anteriores como puede ser el get para la vista, o la división en dos aplicaciones dependerá exclusivamente de tu caso de uso y de tu empresa, ambas soluciones tienen beneficios y desventajas.
Mi recomendación personal es que hagas un código limpio y estructurado, así elijas una u otra migrar en caso de que la empresa crezca o de que no vaya tan bien como se esperaba será muy sencillo.
2 - Implementar CQRS
Cuando implementamos CQRS y tenemos las aplicaciones separadas no hay ningún motivo por el que debamos tener el mismo tipo de bases de datos, ¿es posible? si claro, pero no hay nada que nos obligue.
De hecho es muy común, como en el caso que he explicado de los productos tener la base de datos de escritura de tipo relacional mientras que la de lectura que sea no relacional (NoSQL).
Otro ejemplo muy común si trabajamos exclusivamente con MongoDb es tener la base de datos de escritura en “master” y lectura en las “réplicas” (replicaset).
Por ejemplo, si tenemos productos con las descripciones, precio y stock estamos relacionando 3 elementos que “no tienen nada que ver”.
Me explico, la descripción del producto no va a cambiar si actualizamos el precio, mientras que actualizar el precio no cambiará el producto.
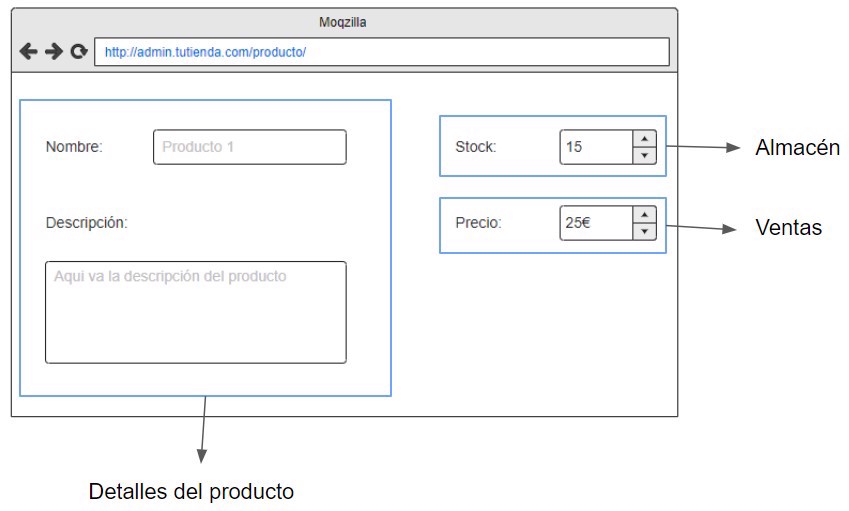
Son claramente diferentes entidades (y eso sin tener en cuenta si tenemos que mantener el historial) por lo tanto no deben estar en la misma tabla. Y posiblemente deberían estar en diferentes servicios también.
Mientras que cuando consultamos el producto, queremos ver toda esa información, así que agregaremos dicha información en una sola fila en la base de datos NoSQL.
- Nota: Haré un post/video sobre las diferencias entre SQL y NoSQL en el futuro.
Si no lo hiciéramos así, tendríamos dos opciones para consultar toda esa información, una consulta con muchos inner joins o muchas llamadas api dentro del propio backend, o muchas consultas a diferentes APIs desde el front end.
Este es otro de esos puntos donde no hay una opción mejor ni peor que la otra, para ciertos casos de uso es mejor una tabla que actúe como “vista” agregando múltiple información, mientras que en otros casos es mejor múltiples llamadas a las API.
Antes de terminar con este punto, si te fijas, no tenemos botón de guardar en la imagen anterior, eso es porque los comandos representan acciones únicas que el usuario puede realizar, si te fijas en todas las webs modernas cuando modificas información ya no tienes que ir al final de la página a guardar, sino que se actualiza al momento, ya sea automáticamente o través de un modal.
La idea es la misma, editamos únicamente la información que necesitamos actualizar.
De esta forma tu API se convierte en una capa que hace de intermediario entre el front end o cliente y la acción a ejecutar.
2.1 - Creación de la infraestructura
Como siempre este código está disponible en GitHub en el proyecto Distribt.
- Nota: Para simplificar en el ejemplo únicamente está creado el microservicio de productos, si veo que hay confusión o me llegan dudas al respecto, crearé los otros dos.
Para reproducir el ejemplo de lo que podría ser una aplicación real en producción voy a dividir la api de lectura de la de escritura. Por lo tanto crearé dos proyectos nuevos, además crearé un consumidor, el cual va a consumir los eventos que generamos y enviamos al Service bus.
Además de una capa extra que contendrá la lógica de negocio, y esta capa se podría dividir en múltiples proyectos, pero para este ejemplo no merece la pena.
Y como siempre toda esta configuración la tenemos que implementar en los servicios que hemos visto hasta ahora, en nuestro caso únicamente añadir la información a Consul:
docker exec -it consul consul services register -name=ProductsApiWrite -address=http://localhost -port=50320
docker exec -it consul consul services register -name=ProductsApiRead -address=http://localhost -port=50321Ahora voy a añadir tanto MySql como MongoDb a nuestro fichero docker-compose, en MySql mantendremos la versión de escritura y en MongoDb la de lectura.
mongodb:
image: mongo:latest
container_name: MongoDb
ports:
- 27017:27017
environment:
- MONGO_INITDB_ROOT_USERNAME=distribtUser
- MONGO_INITDB_ROOT_PASSWORD=distribtPassword
- MONGO_INITDB_DATABASE=distribt
volumes:
- ./tools/mongodb/mongo-init.js:/docker-entrypoint-initdb.d/mongo-init.js:ro
mysql:
image: mysql:8.0
container_name: MySql
environment:
MYSQL_DATABASE: 'distribt'
MYSQL_USER: 'distribtUser'
MYSQL_PASSWORD: 'distribtPassword'
MYSQL_ROOT_PASSWORD: 'distribtRootPassword'
ports:
- 3306:3306
volumes:
- ./tools/mysql/init.sql:/docker-entrypoint-initdb.d/init.sql
Y este es el contenido de mongo (mongo-init.js)
db.createUser({
user: "distribtUser",
pwd: "distribtPassword",
roles: [{
role: "readWrite",
db: "distribt"
}
],
mechanisms: ["SCRAM-SHA-1"]
});
db.createCollection("Products");
db.Products.insertOne({"Id": 1, "Details": {"Name": "Producto 1", "Description": "La descripción dice qu es el primer producto"}, "Stock": 32, "Price": 10 });
db.Products.insertOne({"Id": 2, "Details": {"Name": "Segundo producto", "Description": "Este es el producto numero 2"}, "Stock": 3, "Price": 120 });
db.Products.insertOne({"Id": 3, "Details": {"Name": "Tercer", "Description": "Terceras Partes nunca fueron buenas"}, "Stock": 10, "Price": 15 });
Y el de MySql (init.sql)
USE `distribt`;
CREATE TABLE `Products` (
`Id` int NOT NULL AUTO_INCREMENT,
`Name` VARCHAR(150) NOT NULL,
`Description` VARCHAR(150) NOT NULL,
PRIMARY KEY (`Id`)
) AUTO_INCREMENT = 1;
INSERT INTO `distribt`.`Products` (`Id`, `Name`, `Description`) VALUES ('1', 'Producto 1', 'La descripción dice qu es el primer producto');
INSERT INTO `distribt`.`Products` (`Id`, `Name`, `Description`) VALUES ('2', 'Segundo producto', 'Este es el producto numero 2');
INSERT INTO `distribt`.`Products` (`Id`, `Name`, `Description`) VALUES ('2', 'Tercer', 'Terceras Partes nunca fueron buenas');Como vemos ambos tienen un par de datos ya configurados, para así poder ver el ejemplo
Y por lo tanto las configuraciones de ambas bases de datos van a ir a Vault y a consul:
# VAULT
## User&Pass for mongoDb
docker exec -it vault vault kv put secret/mongodb username=distribtUser password=distribtPassword
##User&Pass for MySql
docker exec -it vault vault kv put secret/mysql username=distribtUser password=distribtPassword
# CONSUL
docker exec -it consul consul services register -name=MySql -address=localhost -port=3307
docker exec -it consul consul services register -name=MongoDb -address=localhost -port=27017Aunque en el caso de Vault podemos añadirlo como un engine.
Por ahora hemos creado toda la infraestructura necesaria para almacenar la información
Y si recordamos del post sobre el patrón productor consumidor cuando insertemos en la base de datos de escritura, crearemos un mensaje de dominio, para que el handler lo lea.
Para crear dicho mensaje de dominio, debemos crear en RabbitMQ un service bus, vamos a crear tanto la cola interna, que va a mantener los mensajes de dominio, como la externa para que otros servicios puedan acceder a la información que hemos actualizado.
"queues": [
{"name":"product-queue","vhost":"/","durable":true,"auto_delete":false,"arguments":{}},
{"name":"product-queue.dead-letter","vhost":"/","durable":true,"auto_delete":false,"arguments":{}},
{"name":"product-domain-queue","vhost":"/","durable":true,"auto_delete":false,"arguments":{}},
{"name":"product-domain-queue.dead-letter","vhost":"/","durable":true,"auto_delete":false,"arguments":{}}
],
"exchanges": [
{"name":"products.exchange","vhost":"/","type":"topic","durable":true,"auto_delete":false,"internal":false,"arguments":{}},
],
"bindings": [
{"source":"products.exchange","vhost":"/","destination":"product-queue","destination_type":"queue","routing_key":"external","arguments":{}},
{"source":"products.exchange","vhost":"/","destination":"product-domain-queue","destination_type":"queue","routing_key":"internal","arguments":{}}
]En el código hemos creado también la cola product-queue pero no la utilizaremos en este ejemplo.
- Nota: en este punto es donde entra
MediatR, en caso de que tengas todo en la misma aplicación.
3 - Implementación de CQRS en C#
El código en sí es muy sencillo, creamos dichas APIs y los endpoints correspondientes.
Uno para crear y otro para actualizar en la API Write:
[HttpPost(Name = "addproduct")]
public Task<IActionResult> AddProduct(CreateProductRequest createProductRequest)
{
throw new NotImplementedException();
}
[HttpPut("updateproductdetails/{id}")]
public Task<IActionResult> UpdateProductDetails(int id, ProductDetails productDetails)
{
throw new NotImplementedException();
}Como podemos observar create nos incluye CreateProductRequest el cual tiene todos los datos de stock y precio, mientras que update es únicamente los detalles, osea el nombre y la descripción.
public record CreateProductRequest(ProductDetails Details, int Stock, decimal Price);
public record ProductDetails(string Name, string Description);
public record FullProductResponse(int Id, ProductDetails Details, int Stock, decimal Price);
public record ProductUpdated(int ProductId, ProductDetails Details);
public record ProductCreated(int Id, CreateProductRequest ProductRequest);
- Haciendo referencia a lo mencionado anteriormente, sobre que depende como queramos hacer nosotros la orquestación, tendremos que configurar la aplicación de una forma u otra.
Otro para consultar los productos en la api Read:
[HttpGet("{productId}")]
public Task<IActionResult> GetProduct(int productId)
{
throw new NotImplementedException();
}
Command/Query en el nombre del tipo
Una de las batallas que siempre tienen lugar en las discusiones sobre CQRS es si debemos incluir o command o query en el nombre del tipo, por ejemplo, si estamos haciendo una consulta del producto, debemos llamar al tipo ProductQuery o cuando insertamos un producto CreateProductCommand.
Esta conversación da lugar a un montón de peleas en los equipos, y voy a dar mi opinión. A mi me da exactamente igual que ponga Query o Command o no ponga nada, siempre y cuando tenga un nombre que se entienda con facilidad.
Y volviendo al código…
Modificamos los controladores de la parte de escritura, así como crear un caso de uso:
[ApiController]
[Route("[controller]")]
public class ProductController
{
private readonly IUpdateProductDetails _updateProductDetails;
private readonly ICreateProductDetails _createProductDetails;
public ProductController(IUpdateProductDetails updateProductDetails, ICreateProductDetails createProductDetails)
{
_updateProductDetails = updateProductDetails;
_createProductDetails = createProductDetails;
}
[HttpPost(Name = "addproduct")]
public async Task<IActionResult> AddProduct(CreateProductRequest createProductRequest)
{
CreateProductResponse result = await _createProductDetails.Execute(createProductRequest);
return new CreatedResult(new Uri(result.Url), null);
}
[HttpPut("updateproductdetails/{id}")]
public async Task<IActionResult> UpdateProductDetails(int id, ProductDetails productDetails)
{
bool result = await _updateProductDetails.Execute(id, productDetails);
return new OkResult();
}
}- Nota: en este post esta solo el caso de uso de actualizar un producto, en github está el resto, completo.
public interface IUpdateProductDetails
{
Task<bool> Execute(int id, ProductDetails productDetails);
}
public class UpdateProductDetails : IUpdateProductDetails
{
private readonly IProductsWriteStore _writeStore;
private readonly IDomainMessagePublisher _domainMessagePublisher;
public UpdateProductDetails(IProductsWriteStore writeStore, IDomainMessagePublisher domainMessagePublisher)
{
_writeStore = writeStore;
_domainMessagePublisher = domainMessagePublisher;
}
public async Task<bool> Execute(int id, ProductDetails productDetails)
{
await _writeStore.UpdateProduct(id, productDetails);
await _domainMessagePublisher.Publish(new ProductUpdated(id, productDetails), routingKey: "internal");
return true;
}
}Llegados a este punto, ya tenemos nuestro mensaje en el service bus.
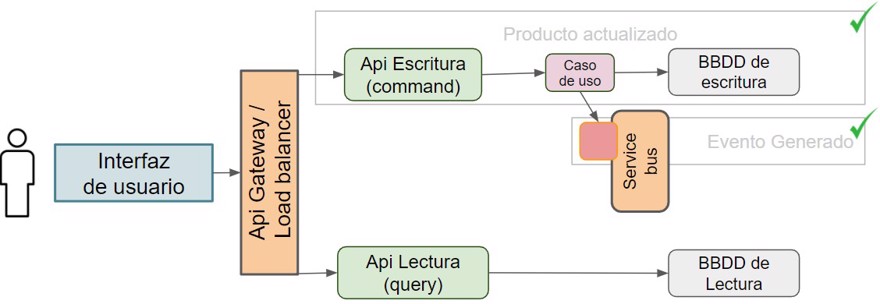
Con este código ya tenemos creada la mitad de la implementación, ahora solo nos queda la otra mitad, osea consumir el evento para actualizar la base de datos de lectura y así ser capaces de leer la información.
Para ello crearemos el handler que actualiza la información, y en nuestro caso en concreto crea un mensaje de integración.
public class ProductUpdatedHandler : IDomainMessageHandler<ProductUpdated>
{
private readonly IProductsReadStore _readStore;
private readonly IIntegrationMessagePublisher _integrationMessagePublisher;
public ProductUpdatedHandler(IProductsReadStore readStore, IIntegrationMessagePublisher integrationMessagePublisher)
{
_readStore = readStore;
_integrationMessagePublisher = integrationMessagePublisher;
}
public async Task Handle(DomainMessage<ProductUpdated> message, CancellationToken cancelToken = default(CancellationToken))
{
await _readStore.UpsertProductViewDetails(message.Content.ProductId, message.Content.Details, cancelToken);
await _integrationMessagePublisher.Publish(
new ProductUpdated(message.Content.ProductId, message.Content.Details), routingKey:"external", cancellationToken: cancelToken);
}
}En este caso la lógica es la misma, el evento es el trigger que causa la ejecución del comando.
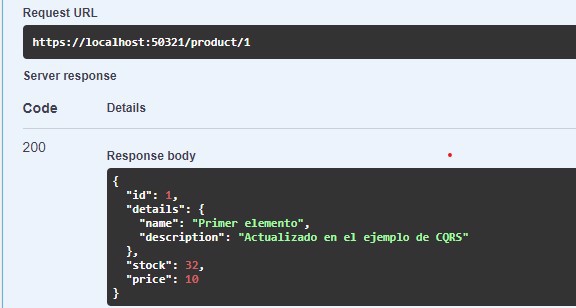
Por lo tanto ya tenemos el valor actualizado en la base de datos de lectura:
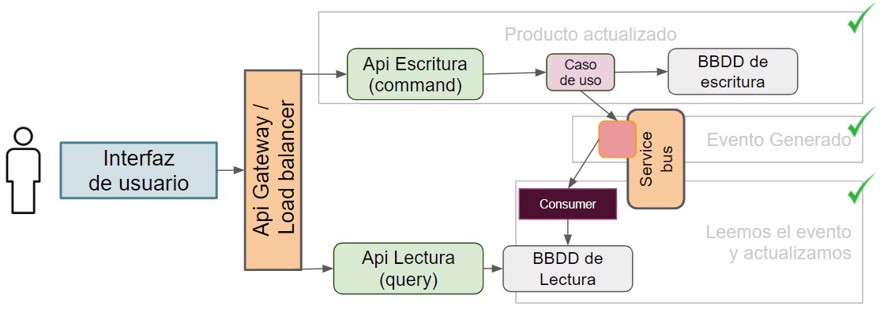
Y finalmente debemos crear el simple get, que podemos hacerlo en una minimal api si queremos, ya que no tiene lógica como tal.
app.MapGet("product/{productId}", async ( int productId, IProductsReadStore readStore)
=> await readStore.GetFullProduct(productId));
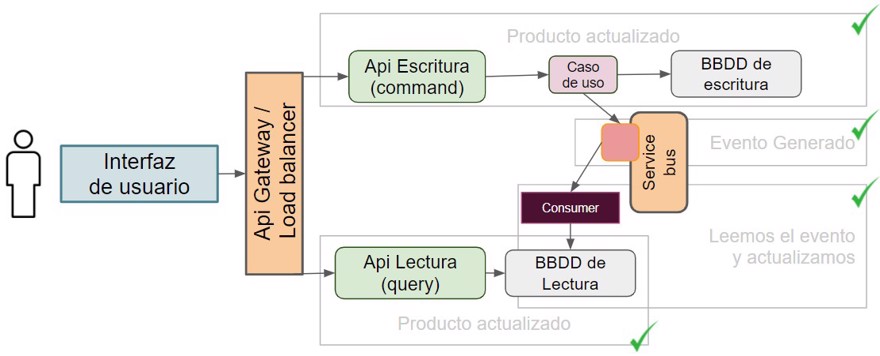
Y podemos ver como se ha actualizado el elemento
Conclusión
En este post hemos visto de forma rápida y clara que es CQRS.
Cuáles son las características principales de CQRS.
Cómo implementar CRQS en C#

