En este post vamos a ver la continuación del curso de Distribt, y digo continuación porque CQRS que fue el post anterior y Event Sourcing suelen ir siempre de la mano, aunque no siempre.
Aquí vamos a ver qué es Event Sourcing en detalle y cómo implementarlo en C#
- Nota: EventSourcing y DDD (domain driven design) se suelen ver juntos ya que es muy común utilizar
aggregatesen Event Sourcing los cuales son parte del patrón DDD.
Índice
Por supuesto el código lo tienes siempre disponible en GitHub en la librería de Distribt.
1 - Situación actual
Antes de empezar con el nuevo post vamos a ver como funciona nuestro actual sistema, tenemos una base de datos, la cual actualizamos cada vez que cambiamos el valor.
En nuestro caso, tenemos los endpoints addproduct y updateproductdetails/{id} los cuales nos permiten crear un producto y modificarlo.
Así que si creamos un producto con el nombre “item1” y la descripción como “descripcion1” y luego lo actualizas tendremos el siguiente escenario:
Tenemos una tabla con un registro y al actualizarlo actualizamos el valor de dicho registro, por lo tanto el valor antiguo desaparece de la propia base de datos.
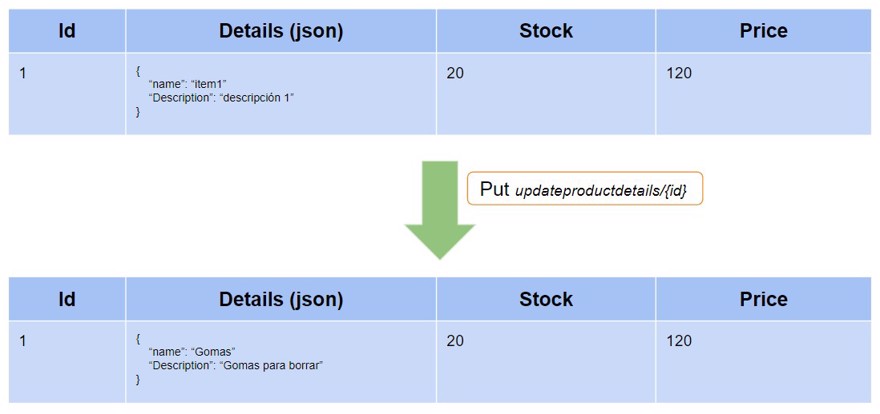
Y esto funciona, es una actualización normal de la base de datos. lo que se denomina el estado actual.
- Es común tener logs, ya bien sea en la base de datos o en ficheros que indican los cambios, o incluso, una copia de la propia tabla cada vez que algo cambia.
2 - Qué es Event Sourcing
Con event sourcing lo que hacemos es tener una base de datos que va a contener todos los eventos que suceden en nuestro sistema.
Por eventos, nos referimos a las acciones del usuario. Y cuando los combinas todos llegas al estado actual.
Por ejemplo, si tenemos múltiples eventos, el primero donde tenemos la creación del producto y posteriormente sus actualizaciones.
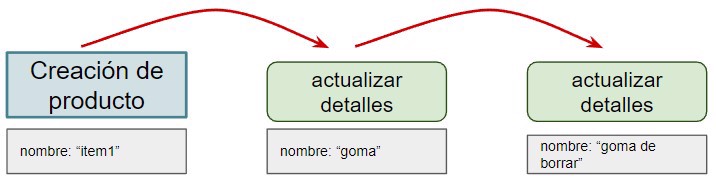
Con lo que también llegamos al estado actual
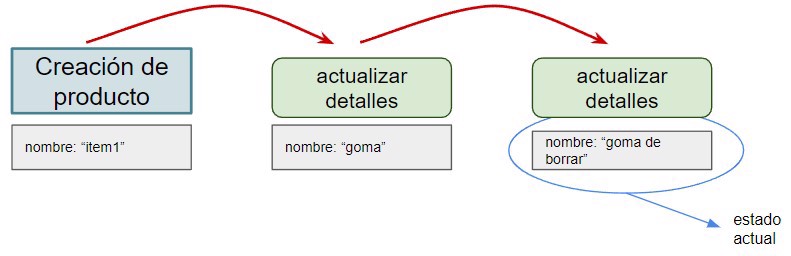
Tecnicamente podemos guardar únicamente el evento en la base de datos, pero puede ser buena idea almacenar otra información como la fecha, o como veremos en la implementación el orden en el que suceden dichos eventos.
2.1 - Importancia de los nombres en event sourcing
Quiero hacer una mención especial a los nombres de los eventos, y es que, como con las variables cuando programamos, los nombres de los eventos tienen que ser autoexplicativos y claros.
Imagina que tenemos nuestro microservicio de Pedidos (Distribt.Orders). Podríamos tener un evento que se llamase, “OrderUpdated” o podríamos tener varios tipos de eventos, uno para indicar que se ha generado una venta “OrderCreated” otro para indicar que el pedido se ha pagado “OrderPaid” otro para cuando el pedido ha sido enviado desde el almacén “OrderDispatched” y así hasta el infinito. Cuantos más tengamos más claro va a ser.
Además como vemos el primero es “OrderUpdated” lo que implica (normalmente) enviar toda la información en cada evento, mientras que si especificamos cada evento lo que es, podemos enviar únicamente la información necesaria.
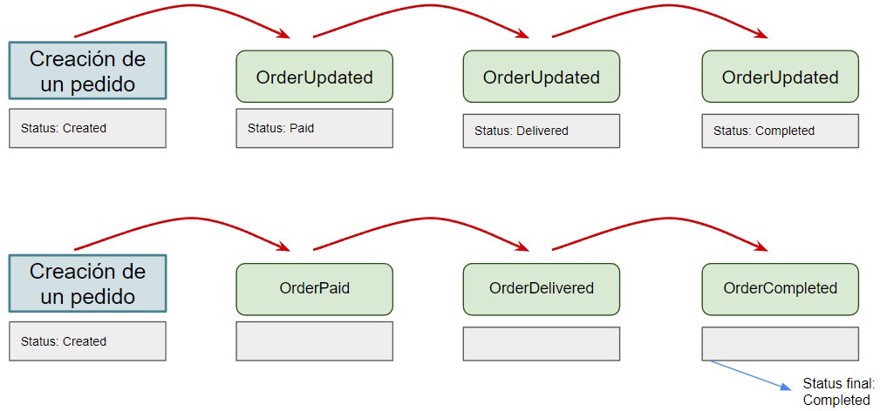
Y esto lo digo con experiencia en el asunto, ya que tuve que entrar a un proyecto donde había más de 20 eventos llamados “created” o “updated”, obviamente el namespace te daba la pista, pero no era intuitivo para nada.
También es importante intentar reducir al mínimo la cantidad de información que almacenamos, por ejemplo si estamos cambiando el estado del pedido, no tiene sentido que mandemos los ítems, o la dirección de envío.
2.2 - Fuente de fiabilidad en Event Sourcing
Con este cambio lo que conseguimos es utilizar nuestros eventos como acciones que han pasado en el sistema. Y por ello denominamos a los eventos “source of truth” o fuente de la verdad. ya que contienen todo lo que ha sucedido en el sistema para un ID en concreto.
Para almacenar los eventos utilizamos lo que se llama la “eventStore” podemos utilizar cualquier tipo de base de datos, aunque lo normal va a ser una base de datos basada en documentos como mongodb, documentdb, eventsotreDb, etc.
Nosotros en este ejemplo utilizaremos MongoDb con una colección llamada “events”.
Si vas a utilizar Event Sourcing junto a CQRS, recuerda que esto es únicamente para la base de datos de escritura, y lo utilizaremos para guardar un registro del estado.
2.3 - Agregar los eventos
Como has visto estamos creando eventos muy centrados en un producto, estos eventos van todos “enlazados” y se enlazan en lo que llamamos aggregate, cuando trabajamos con Event Sourcing y queremos leer el estado actual de un objeto, en este caso un producto, debemos leer todos los elementos de la base de la eventStore que referencian a dicho objeto y con ello montar el aggregate con la información final.
Puedes preguntarte si esto no es malo para la base de datos, si influye en el rendimiento. Y obviamente sí, al final estas cargando muchos más datos de que si únicamente tuvieses un único elemento o fila.
Pero, aún con esto, en la práctica la diferencia es mínima. En caso de que tardara mas de algo aceptable siempre puedes hacer lo que se llaman snapshots de los datos, decir, desde el día X el estado actual de cada aggregate es el “nuevo primero” y así puedes limpiar toda la información anterior.
Perderás el historial (lo puedes mover a un cold storage) pero ganarás en velocidad. Personalmente he trabajado con Event Sourcing los últimos años y nunca he tenido este problema.
Al final no hay una solución única para todo, cada empresa/equipo tiene unas prioridades que definen la solución final.
3 - Cuándo utilizar el patrón event sourcing
Después de esta complejidad añadida, te preguntarás si de verdad tiene ventajas utilizar este patrón. Aquí te las voy a nombrar y luego deberás decidir si quieres implementar el patrón o no. Ya que como en todo, hay escenarios donde sí nos va a beneficiar mucho, y otros donde no lo hará tanto, se suele ver ligado también a DDD
Así que vamos a utilizarlo siempre y cuando podamos sacar ventaja del mismo con los siguientes beneficios.
3.1 - Beneficios de utilizar event sourcing
- Observabilidad, Al tener todos los eventos somos capaces de identificar porque un registro tiene dicho valor, sabemos dónde, cuándo y porqué cada registro ha sido modificado por lo que nos da seguridad para saber que la información es completamente fiable.
- Tolerancia a fallos, Para mi esta ventaja es la gran ventaja de Event sourcing, al guardar registro de cada evento que sucede en nuestro sistema, podemos corroborar que la información es correcta en la read store, lo que también podemos hacer es experimentos en la read store, y si algo va mal. únicamente debemos volver a ejecutar todos los eventos otra vez.
- Comunicación asíncrona, Utilizar Event sourcing the obliga (más o menos) a tener que construir las apis para tus clientes con dicha idea. Lo cual puede traernos muchos beneficios si implementamos buenas prácticas.
- Auditar/logs, si bien es cierto que su propósito principal no es auditar acciones en un sistema, se pueden utilizar perfectamente para ello. Es una mejor alternativa a tener una tabla con los logs.
4 - Implementación de Event sourcing en C#
Para seguir ampliando el contenido del proyecto y demostrar que diferentes patrones pueden convivir en un mismo sistema, para mostrar Event Sourcing vamos a trabajar en el microservicio de Distribt.Orders.
Hasta ahora todo lo que tenemos es una api que nos devuelve información falsa y es lo que vamos a cambiar. Lo primero que tenemos que hacer es crear la conexión entre nuestro código y la base de datos.
4.1 - Persistir un aggregate usando MongoDb
El código es bastante extenso, me voy a centrar en lo principal. Toda la lógica de Event Sourcing está en el proyecto Distribt.Shared.EventSourcing el cual está enlazado a MongoBD. Esto es una decisión personal, podríamos haber elegido cualquier otra base de datos o eventStore para trabajar con los eventos.
Y para utilizar dicha libreríra, desde la aplicación cliente debes llamar a webappBuilder.Services.AddEventSourcing(webappBuilder.Configuration);
Cuando indicas dicho servicio, se nos inyectará al contenedor de dependencias la interfaz IEventStore, que es la que se utilizará en el aggregate la cual es la que se comunica con MongoDb
A - El Aggregate
El aggregate es el tipo que vamos a utilizar para realizar toda la lógica de nuestro objeto.
Este tipo Aggregate (también llamado AggregateRoot) contiene la lista de los eventos, el Id, y la “versión” actual, osea el número de eventos.
Finalmente, cierta lógica para saber cuando un elemento es un cambio que viene de la base de datos o es un cambio nuevo para ser almacenado
namespace Distribt.Shared.EventSourcing;
public class Aggregate
{
private List<AggregateChange> _changes = new List<AggregateChange>();
public Guid Id { get; internal set; }
private string AggregateType => GetType().Name;
public int Version { get; set; } = 0;
/// <summary>
/// this flag is used to identify when an event is being loaded from the DB
/// or when the event is being created as new
/// </summary>
private bool ReadingFromHistory { get; set; } = false;
protected Aggregate(Guid id)
{
Id = id;
}
internal void Initialize(Guid id)
{
Id = id;
_changes = new List<AggregateChange>();
}
public List<AggregateChange> GetUncommittedChanges()
{
return _changes.Where(a=>a.IsNew).ToList();
}
public void MarkChangesAsCommitted()
{
_changes.Clear();
}
protected void ApplyChange<T>(T eventObject)
{
if (eventObject == null)
throw new ArgumentException("you cannot pass a null object into the aggregate");
Version++;
AggregateChange change = new AggregateChange(
eventObject,
Id,
eventObject.GetType(),
$"{Id}:{Version}",
Version,
ReadingFromHistory != true
);
_changes.Add(change);
}
public void LoadFromHistory(IList<AggregateChange> history)
{
if (!history.Any())
{
return;
}
ReadingFromHistory = true;
foreach (var e in history)
{
ApplyChanges(e.Content);
}
ReadingFromHistory = false;
Version = history.Last().Version;
void ApplyChanges<T>(T eventObject)
{
this.AsDynamic()!.Apply(eventObject);
}
}
}
Cuando creas un objeto tuyo de dominio, debes implementar Aggregate para que este funcione como un aggregate, además de utilizar la interfaz IApply<T> por cada evento que dicho objeto vaya a trabajar con
public class OrderDetails : Aggregate, IApply<OrderCreated>, IApply<OrderPaid>, IApply<OrderDispatched>, IApply<OrderCompleted>
{
//Código
}
Como vemos en ejemplo, tenemos el aggregate OrderDetails, y luego un IApply<T> por cada evento de los mostrados anteriormente.
B - Guardar el Aggregate en MongoDb
Cuando almacenamos información lo hacemos de una forma especial, ya que no almacenamos únicamente el evento, sino que almacenamos información que hacen que podamos identificarlo o agruparlo junto a otros.
Esa información es la que puedes ver en los tipos AggregateChange y AggregateChangeDto este tipo contiene información como
Content: para el contenido del objeto (incluye el evento).AggregateId: ID del aggregate, en nuestro caso el ID del pedido.AggregateType: para saber que tipo es.Version: versión del aggregate, cada nuevo evento añade 1)TransactionId: combinación entre el Id y la versión
Al ser esta información la que vamos a guardar, creamos un index en MongoDb con el Id, el tipo y la versión (se hace en la librería de forma automática).
Dentro de la propia librería hay una clase llamada AggregateRepository<TAggregate> la cual deberá ser implementada por tu repositorio.
El tipo AggregateRepository<TAggregate> tiene dos métodos
GetByIdAsync: Lee de la base de datos por ID y monta el Aggregate en orden y de forma correcta.SaveAsync: Guarda en la base de datos los nuevos eventos.
Esto te da la posibilidad de ya bien sea inyectar IAggregateRepository<TAggregate> en tus servicios o bien crear tu propio repositorio e implementar el AggregateRepository<TAggregate> (mi opción recomendada):
public interface IOrderRepository
{
Task<OrderDetails> GetById(Guid id, CancellationToken cancellationToken = default(CancellationToken));
Task Save(OrderDetails orderDetails, CancellationToken cancellationToken = default(CancellationToken));
}
public class OrderRepository : AggregateRepository<OrderDetails>, IOrderRepository
{
public OrderRepository(IEventStore eventStore) : base(eventStore)
{
}
public async Task<OrderDetails> GetById(Guid id, CancellationToken cancellationToken = default(CancellationToken))
=> await GetByIdAsync(id, cancellationToken);
public async Task Save(OrderDetails orderDetails, CancellationToken cancellationToken = default(CancellationToken))
=> await SaveAsync(orderDetails, cancellationToken);
}Como vemos la implementación es muy sencilla.
Nota: La versión actual tiene un bug/feature y los eventos tienen que ser registrados en el BsonSerializer manualmente durante la inicialización de la aplicación.
public static class MongoMapping
{
public static void RegisterClasses()
{
//#22 find a way to register the classes automatically or avoid the registration
BsonClassMap.RegisterClassMap<OrderCreated>();
BsonClassMap.RegisterClassMap<OrderPaid>();
BsonClassMap.RegisterClassMap<OrderDispatched>();
}
}Si puedes ayudar a encontrar el problema estaré muy agradecido, gracias.
Finalmente, la información de a qué base de datos y a que colección nos conectaremos debemos indicarla la configuración utilizando el fichero appsettings, con la siguiente sección.
"EventSourcing": {
"DatabaseName" : "distribt",
"CollectionName" : "EventsOrders"
},
4.2 - Creación de un Aggregate
Ahora vamos a pasar a la lógica de nuestro tipo, o a como nuestro tipo va a cambiar dependiendo del evento.
Nuestro caso de uso es cuando creamos un pedido, y sus posibles modificaciones, por ello creamos el tipo OrderDetails y le incluimos la información que nuestro Pedido va a contener.
Por supuesto indicamos el Aggregate y nos obligará a tener un constructor con un Id único.
Con esto lo único que tenemos es objeto por defecto y un Id, por lo tanto ahora debemos empezar a aplicar los eventos que pueden suceder a nuestro objeto.
El primero de ellos, es la creación de dicho objeto:
public class OrderDetails : Aggregate, IApply<OrderCreated>
{
public DeliveryDetails Delivery { get; private set; } = default!;
public PaymentInformation PaymentInformation { get; private set; } = default!;
public List<ProductQuantity> Products { get; private set; } = new List<ProductQuantity>();
public OrderStatus Status { get; private set; }
public OrderDetails(Guid id) : base(id)
{
}
public void Apply(OrderCreated ev)
{
Delivery = ev.Delivery;
PaymentInformation = ev.PaymentInformation;
Products = ev.Products;
Status = OrderStatus.Created;
ApplyChange(ev);
}
}
Como ves, al implementar la interfaz, creamos un método llamado Apply que recibe el evento. Dentro del método, modificamos el objeto a placer y llamamos al método ApplyChange el cual, almacenará el evento como un nuevo evento y cuando guardemos el aggregate a través de AggregateRepository detectara que es un nuevo evento y lo guardara.
Ahora debemos repetir la misma acción con el resto de los eventos
public class OrderDetails : Aggregate, IApply<OrderCreated>, IApply<OrderPaid>, IApply<OrderDispatched>, IApply<OrderCompleted>
{
public DeliveryDetails Delivery { get; private set; } = default!;
public PaymentInformation PaymentInformation { get; private set; } = default!;
public List<ProductQuantity> Products { get; private set; } = new List<ProductQuantity>();
public OrderStatus Status { get; private set; }
public OrderDetails(Guid id) : base(id)
{
}
public void Apply(OrderCreated ev)
{
Delivery = ev.Delivery;
PaymentInformation = ev.PaymentInformation;
Products = ev.Products;
Status = OrderStatus.Created;
ApplyChange(ev);
}
public void Apply(OrderPaid ev)
{
Status = OrderStatus.Paid;
ApplyChange(ev);
}
public void Apply(OrderDispatched ev)
{
Status = OrderStatus.Dispatched;
ApplyChange(ev);
}
public void Apply(OrderCompleted ev)
{
Status = OrderStatus.Completed;
ApplyChange(ev);
}
}
4.3 - Creación de los casos de uso con Event Sourcing
Para simplificar en el post no voy a especificar todos, únicamente el de crear el pedido, y el de indicar que está pagado, pero todos siguen la misma lógica.
- Nota: En el código si que están todos los casos de uso.
Lo primero es cambiar el endpoint para que en vez de devolver información aleatoria llamemos al servicio que hemos creado y devolvamos información real:
[HttpPost("create")]
public async Task<ActionResult<Guid>> CreateOrder(CreateOrderRequest createOrderRequest,
CancellationToken cancellationToken = default(CancellationToken))
{
OrderDto orderDto = new OrderDto(Guid.NewGuid(), createOrder.orderAddress, createOrder.PersonalDetails,
createOrder.Products);
await _domainMessagePublisher.Publish(orderDto, routingKey: "order");
return new AcceptedResult($"getorderstatus/{orderDto.orderId}", orderDto.orderId);
}
[ApiController]
[Route("[controller]")]
public class OrderController
{
private readonly ICreateOrderService _createOrderService;
[HttpPost("create")]
public async Task<ActionResult<Guid>> CreateOrder(CreateOrderRequest createOrderRequest,
CancellationToken cancellationToken = default(CancellationToken))
{
Guid orderId = await _createOrderService.Execute(createOrderRequest, cancellationToken);
return new AcceptedResult($"getorderstatus/{orderId}", orderId);
}
}Y ahora creamos nuestro OrderService, como ves en el endpoint, además de guardar los datos en la base de datos, también genera un mensaje de dominio.
En la lógica lo que hacemos es crear un nuevo aggregate a través de OrderDetails y le aplicamos el cambio, que en nuestro caso es OrderCreated con el método .Apply(), para posteriormente guardarlo en el repositorio.
- Nota: por ahora dejamos la publicación del evento de dominio, pero si no vamos a utilizar CQRS lo más probable es que debamos cambiarlo a mensaje de integración.
4.3.1 - Añadir un nuevo evento
Una vez tenemos el aggregate creado y guardado (lo podemos comprobar en la base de datos) vamos a crear otro evento, este caso para indicar que está pagado.
Para ello creamos el caso de uso OrderPaidService; Y únicamente debemos aplicar el evento OrderPaid y guardar:
public interface IOrderPaidService
{
Task<bool> Execute(Guid orderId, CancellationToken cancellationToken = default(CancellationToken));
}
public class OrderPaidService : IOrderPaidService
{
private readonly IOrderRepository _orderRepository;
public OrderPaidService(IOrderRepository orderRepository)
{
_orderRepository = orderRepository;
}
public async Task<bool> Execute(Guid orderId, CancellationToken cancellationToken = default(CancellationToken))
{
OrderDetails orderDetails = await _orderRepository.GetById(orderId, cancellationToken);
orderDetails.Apply(new OrderPaid());
await _orderRepository.Save(orderDetails, cancellationToken);
return true;
}
}Si ahora vamos a la base de datos, podremos ver que tenemos únicamente dos eventos.
Además veremos que dichos eventos sólo contienen la información a modificar, no la totalidad del objeto. En el caso de OrderPaid, no contiene datos, ya que es el evento en sí, el que hace cambiar el estado.

Y si leemos el pedido a través de GetOrder vemos como la información es la correcta:
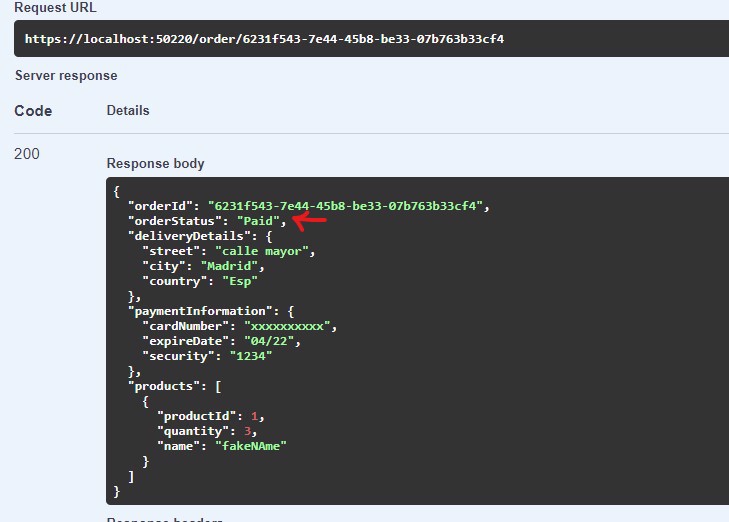
5 - Event sourcing vs Event driven
Finalmente no confundir event sourcing que es mantener un estado o la información de los eventos que tenemos con Event driven que es utilizar eventos para comunicarnos con otras partes del sistema, ya sea interno, con eventos de dominio, o externos con eventos de integración.
Conclusión
En este post hemos visto Que es Event Sourcing
Cual es la diferencia entre event sourcing y event driven
Cómo aplicar event Sourcing a nuestro código
Cómo implementar Event Sourcing con .NET y MongoDb

