Desde hace más de una década la gran mayoría de nosotros no trabaja con ficheros locales, lo hacemos a través de la nube, para evitar, que si el ordenador se rompe, perder el trabajo. Alguna vez te has preguntado cómo funcionan este tipo de sistemas?
En este vídeo veremos cómo funcionan los sistemas de ficheros como Google Drive o Dropbox.
índice
Igual que digo en cada uno de estos vídeos, no hay una única solución válida, sino que hay varias, y lo importante es que entiendan el proceso y cómo funciona para poder debatir los aspectos en las entrevistas.
1 - Requerimientos de un sistema para de ficheros online
Para nuestro escenario, los requerimientos funcionales básicos son:
- Subir ficheros.
- Descargar ficheros.
- Compartir ficheros.
- Propagar los cambios en ficheros con todos los clientes.
Este es un funcionamiento básico para lo que sería un sistema de compartir ficheros, donde tienes una app corriendo en tu máquina, vamos, lo que hace Google Drive o Dropbox.
Además, nuestro sistema debe tener las siguientes características, que serían los requerimientos no funcionales:
- La aplicación debe estar siempre disponible (99.99 uptime).
- Soportar ficheros de gran tamaño.
- Baja latencia.
- La aplicación debe ser capaz de escalar.
NOTA: La colaboración en tiempo real no se va a tratar en este post ya que esa funcionalidad es un diseño en sí mismo.
2 - Trabajar con ficheros grandes
Una de las partes más importantes de cómo funcionan este tipo de aplicaciones es comprender que los ficheros no se envían como tal por la red. Me explico, si tienes un documento de texto, con imágenes, etc y pesa 100 megas y haces un pequeño cambio, no vas a enviar el fichero entero al servidor para que se cambie, ya que eso significa tener que enviar esos 100 megas a todos los clientes, cada vez que actualizas algo.
Para evitar esta situación lo que se hace es partir el fichero en lo que se denomina chunks o bloques vaya, de cierto tamaño y lo que hacemos es sincronizar únicamente los bloques que han cambiado.
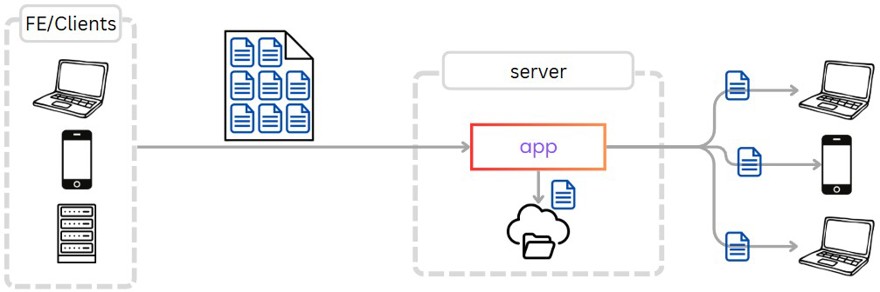
Como puedes imaginar, esto trae consigo complejidad a la hora de diseñar las aplicaciones clientes, ya que es la aplicación la que tiene que montar la diferencia entre lo que había antes y lo que hay ahora para sincronizar los ficheros correctamente.
De igual manera debemos mantener la información de los chunks en la base de datos del sistema.
Esta base de datos debe contener la información del ID del fichero así como cada uno de sus chunks, que sería su hash, pero lo he simplificado para el ejemplo, y la localización de los mismos en el sistema de ficheros que utilicemos.
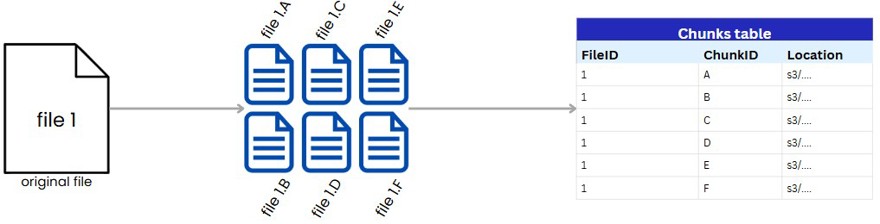
NOTA: si quisieras añadir versionado, aquí sería donde lo puedes poner, ya que cada vez que sincronizas un chunk le puedes indicar una versión, y simplemente la indicas en la tabla. O incluso si quisieras puedes tener una fila de la tabla por versión con todos los chunks dentro, pero bueno la idea está clara.
3 - Entidades del sistema
Ya se que he mencionado una de las entidades que nuestro sistema va a incluir en el punto anterior, pero me parecía crucial separar ese punto para entender cómo funciona este tipo de aplicaciones.
Con ello en mente, tenemos varias entidades principales
- Fichero: que más adelante partiremos en chunks, pero seguimos necesitando el fichero como tal.
- Metadatos del fichero: contiene la información como puede ser el usuario, nombre del fichero, la última vez que se cambió, etc.
- Usuario: Usuarios de nuestro sistema.
- Dispositivos: Estamos diseñando dropbox/google drive lo que quiere decir que tenemos aplicaciones tanto en el PC como en el móvil, etc, podemos almacenar el ID de la máquina, a que usuario están enlazadas y lo mas importante, la fecha de la última sincronización.
- Compartir: una tabla (soy terrible para los nombres) donde indicamos que usuarios tienen acceso a otros ficheros. Puedes ir más allá e incluso añadir equipo, que sería un funcionamiento similar a google workspace, donde X usuarios están dentro de un equipo y puedes compartir ficheros dentro de dicho equipo.
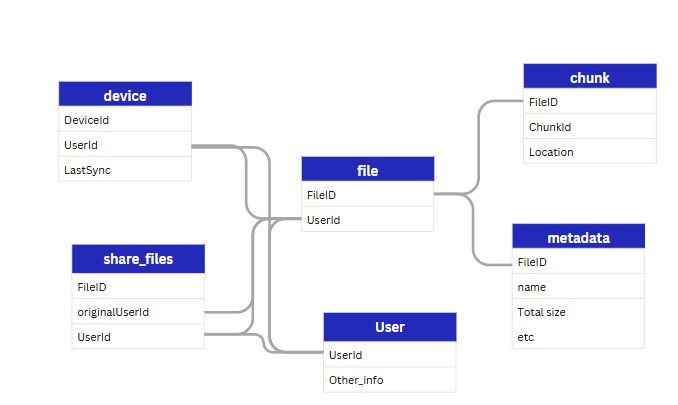
NOTA: Metadatos y fichero se pueden combinar en una sola tabla.
4 - Diseño de la arquitectura de un sistema de ficheros
Vamos a empezar por la parte de subir ficheros, hemos visto antes qué debemos partir los ficheros y cuando descargamos debemos volverlos a juntar.
Para partirlos no hay otra que hacerlo en la aplicación cliente. Por ello el cliente debe ser capaz de recibir el fichero, partirlo e ir subiendo al servidor los chunks que hay nuevos. Por lo que la app en si tiene 3 secciones.
Una sección que monitorea los ficheros que tenemos, esto funciona tanto para los ficheros locales, como para los ficheros en el servidor remoto, ya que los queremos siempre sincronizados.
Para identificar qué ficheros locales han sido modificados tenemos que utilizar funciones específicas del sistema operativo que estamos utilizando. Para los que cambian en el servidor, lo veremos más adelante.
Una sección que se encarga de partir y unir los ficheros.
Y otra sección que se encarga de sincronizar los ficheros, para asegurarnos que siempre tenemos la última versión de cada uno de los ficheros.
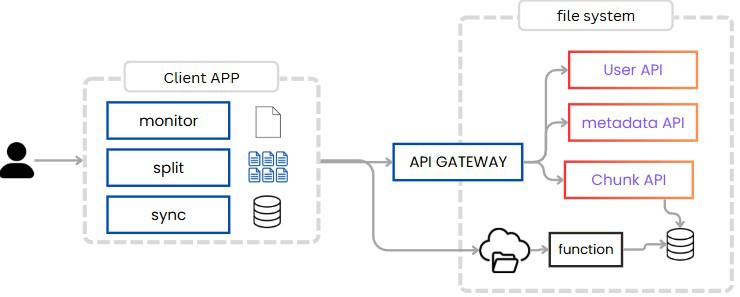
Como vemos mantenemos la información de lo que estamos haciendo en local, eso quiere decir que podemos parar las subidas y completarlas más adelante, el motivo por el que esto es posible es porque tenemos los ficheros partidos en chunks.
De la misma forma, a la hora de subir los ficheros no los subimos a traves de nuestra aplicación, sino que mandamos una petición desde la app cliente a la app web, indicando que tenemos que subir un chunk, esta llamada va a través de la api gateway a nuestro chunk service.
El chunk service se encarga de almacenar en la base de datos el estado del proceso, recibe una llamada como la siguiente:
//request
{
id: 1,
name: "file1"
size_in_kb: 100000,
status: in_progress,
chunks:[
{
id: 1_A,
},
{
id: 1_B,
},
{
id: 1_C,
},
]
}
->
//response
{
chunks:[
{
id: 1_A,
location: s3....
},
{
id: 1_B,
location: s3....
},
{
id: 1_C,
location: s3....
},
]
}Aquí vemos que contiene los metadatos del fichero, y cierta información así como los chunks.
Para cada uno de esos chunks, la app responde con un enlace, el cual es un enlace directo al servicio de almacenamiento, si por ejemplo estamos utilizando S3 de AWS, es un enlace directo a S3, a través de lo que se denomina pre-signed url, lo que quiere decir que el fichero como tal no tiene que pasar por nuestro sistema.
Esta misma funcionalidad existe en AWS, Azure, GCP, etc. y la url que te dan tiene un tiempo de vida limitado, por ejemplo una hora.
Cada vez que subimos un chunk completo tenemos que notificar a la chunk api que dicho fichero está subido, para ello hay dos opciones, la primera es desde la app del cliente realizar una llamada indicando que dicho chunk está subido. La segunda es usando los eventos de S3 (imagino que se puede en Azure/GCP/etc), que notificarán que dicho elemento está subido, así que podemos tener una cola, o una función de la nube escuchando a dichos eventos.
Por supuesto si estáis en una entrevista tenéis que decir que delante de cada uno de estos servicios hay un load balancer y múltiples instancias.
Si no estás familiarizado con estos términos o su importancia te recomiendo leerte mi libro Construyendo sistemas distribuidos.
Además por cada chunk generamos un evento donde el objetivo final de dicho evento es notificar a todos los clientes que hay un fichero o un chunk disponible. Por supuesto, si el fichero no tiene todos los chunks disponibles aún no hay motivo para notificar, pero esta acción sucede sólo durante la primera subida.
Para ello debemos consultar nuestro sistema de metadatos, para asegurarnos de que todos los chunks están subidos y con el sistema de permisos, saber que usuarios tienen permisos para dicho fichero, ya que ellos también deben ser capaces de leer dicho fichero.
Ello lo hacemos con una función nativa que podemos llamar chunk post-processor
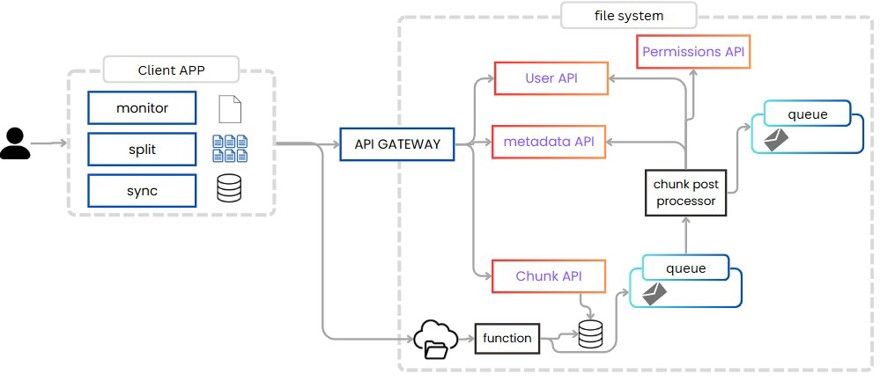
Y aquí tenemos varias opciones para implementarlo.
Una es generar un evento y escucharlo desde un sistema de notificaciones, los cuales se comunican con la aplicación cliente y le pide al servidor los chunks y ficheros que le faltan.
Y mi idea aquí sería enviar una notificación a la aplicación y a partir de ahí, la aplicación refresca los datos, esto se puede conseguir con Websockets o SSE, lo que significa tener una conexión abierta con cada cliente cuando una notificación sucede.
Alternativamente, podemos hacer polling desde la aplicación, cada minuto realizamos una llamada al servidor preguntando si hay algún chunk nuevo desde la última vez que sincronizamos con este dispositivo. Algo más lento pero es mucho más simple que websockets y funciona.
O como opción final podríamos hacer long polling, que significa que la request del usuario se va a quedar abierta hasta que reciba datos nuevos o haga timeout.
Las tres opciones son válidas y correctas, lo importante es que sepas mostrarle al entrevistador los pros y contras de la que elijas en comparación con las otras.
4.1 - Flujo de la aplicación
Con esto ya tenemos el diseño completado, ahora solo nos queda explicar el proceso:
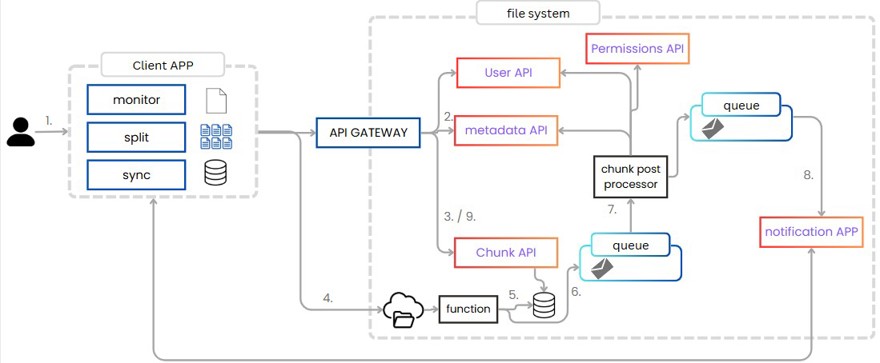
1 - El usuario añade un archivo en la aplicación. Aquí suceden varias acciones, primero el fichero se parte en chunks y de ahí sincronizamos con “la nube”.
2 - Si el fichero es nuevo añadimos la información en el metadata, si no lo es, validamos que el usuario, con permisos si lo hemos implementado, devolviendo el ID del fichero, que será utilizado para identificar los chunks.
3 - Cada chunk funciona de forma individual, es añadido en la base de datos con el estado en proceso y devolvemos una URL autofirmada.
4 - Desde el cliente, utilizamos la URL autofirmada para subir el fichero.
5 - Cada vez que un fichero se ha subido, tenemos una función nativa que actualiza la base de datos con la información del chunk.
6 - Cada vez que un chunk es subido, debemos propagar la información, para ello generamos un evento.
7 - Leemos dicho evento con un consumidor, el cual lee toda la información del fichero, incluyendo qué usuarios tienen permisos para el mismo y por cada uno, genera un evento.
8- Ese evento es propagado a una app que tiene los clientes de los usuarios conectados y les indica que hay una nueva versión de uno de los ficheros.
9 - La app le pide a la api que le de todos los enlaces a los chunks nuevos desde la última vez que hizo una sincronización. Los descarga y actualiza los ficheros correctamente.
4.2 - Detalles avanzados de diseño en un sistema de ficheros
Ahora voy a mencionar una serie de elementos clave dentro de estos sistemas que tenéis que mencionar en las entrevistas mientras los hacéis.
Tamaño de los chunks
Saber que tipo de tamaño tiene que tener cada chunk no es tarea sencilla, Dropbox por ejemplo utiliza 4MB pero durante una entrevista puedes discutir pros y contras de tener chunks de 1 mega, o incluso de 10.
CDN
Se puede dar el caso de que cierto fichero es accedido por miles de personas en varias partes del mundo, para ello puedes utilizar un CDN y tener copias de esos ficheros populares en dichos CDN de esa forma, aunque el usuario principal esté en europa, el acceso desde cualquier parte del mundo sería muy rápido. Ojo que para acceder a los datos del CDN también hay que estar logueado y tener permisos.
Seguridad
La app debería cifrar los chunks durante el trayecto, tanto para subir ficheros como para descargarlos. Para ello puedes indicar que viajan con TLS 1.3 y una vez están almacenados se les aplica AES-256 + KMS (por lo menos en AWS). Y si son datos muy muy sensibles, quizá interese cifrar en el lado del cliente, aunque puede ser que pierdas funcionalidades extra como la vista previa.
Conflictos
En este post no hemos trabajado con que dos usuarios tienen acceso de escritura al mismo fichero. Pero te has llegado a preguntar qué pasaría si dos personas modifican un mismo fichero a la vez? Para ello debemos elegir que opción tomar, si simplemente el último que escribe es válido o ir por una estrategia CRDT, la cual es más costosa de implementar.
De hecho hay una tercera, que sería un bloqueo optimista con un merge manual, la app avisa del conflicto y el usuario decide qué hacer, si no me equivoco es lo que hace Dropbox
Versiones
Y como hemos indicado antes, podríamos tener un versionado si versionamos los chunks, de esa forma podemos coger cada fichero en diferentes versiones. Siempre con un hash de cada versión (lo que he llamado chunkid) y así podemos evitar duplicidad de los chunks.
Dominar todos estos términos, comprenderlos y por supuesto saber explicarlos te puede permitir marcar la diferencia en una entrevista técnica.

