Entrenar un LLM lleva mucho tiempo, muchísimo, dependiendo del volumen de datos podría llevar días. Entonces, cómo hacen esas LLM que tienen datos recientes y no solo eso, saber de dónde saca la información, y citar fuentes.
Tabla de contenidos
1 - Qué es RAG?
RAG viene de las siglas Retrieval-Augmented Generation donde tenemos una LLM a la que no entrenamos, sino que le damos contexto propio encima en cada pregunta.
Esto trae ventajas como menores alucinaciones, saber de dónde saca la información y una implementación muy sencilla.
Un caso muy común del uso de RAG es el soporte y la documentación, podemos tener un modelo, al que le damos todo el contenido de una empresa y puede servirnos como primer nivel para un chatbot ya que nuestro modelo tiene todo el contexto y “sabe” todo lo que le alimentemos.
A RAG le podemos dar la información desde cualquier parte, o mas normal es una base de datos o un sistema de ficheros.
2 - Estructura de un sistema RAG
Para implementar RAG tenemos varios pasos que vamos a ver en este post.
Primero debemos leer los datos, extraer la información ya sea de una base de datos, de un fichero o de una web, tenemos que coger dichos datos y trocearlos o hacer lo que se denomina chunking.
Segundo debemos convertir cada trozo en representaciones numéricas llamadas embeddings. Un embedding es una lista de números (vector) que captura el significado semántico del texto.
Guardamos estos vectores en una base de datos vectorial. (id, texto, vector, metadatos)
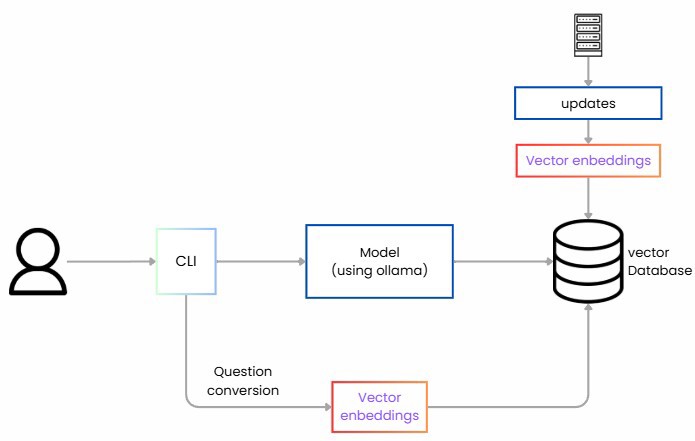
Posteriormente para las consultas hacemos lo mismo, convertimos la pregunta en un vector y recuperamos los trozos más similares.
Orquestramos el prompt con las instrucciones y generamos la respuesta del LLM únicamente con lo recuperado.
2.1 - Qué es una Base de datos vectorial?
La parte clave de RAG es la base de datos vectorial la cual es un tipo de base de datos diseñada para buscar eficientemente en vectores de alta dimensión.
Para ponerlo en comparación, cuando buscamos información en una base de datos mas tradicional como puede ser SQL o NoSQL buscamos normalmente con texto o identificadores exactos, ya bien sea por nombre, por texto, etc, la gran mayoría de búsquedas son exactas. En una base de datos vectorial no buscamos y encontramos resultados exactos sino “conceptualmente similares”.
Esto se consigue porque cuando almacenamos texto, o imágenes o cualquier cosa no almacenamos el valor como tal sino una representación numérica de su significado. Esta representación numérica es el vector.
Cuando decimos que dos vectores son “conceptualmente similares” nos referimos a lo siguiente.
Si tenemos una frase que dice: “El final de la serie de juego de tronos es malísimo” puede convertirse en un vector como [0.20, -4.45, 0.80 …]
Y luego la frase “Los últimos episodios de la serie de House son muy buenos” se convierte en un vector como el siguiente [0.22, -4.50, 0.7 …]
Pero en cambio la frase “La mejor tortilla es con cebolla” se puede convertir en un vector [0.8, 0.02, -0.3 …]
Estos vectores son la representación de lo que es conceptualmente similar, las dos primeras frases son muy similares entre sí, por lo que los vectores son similares. Mientras que la última no tiene nada que ver y se sitúa a una distancia muy lejana.
3 - Crear un sistema RAG en local
Aquí vamos a ver como crear RAG utilizando C#, para ello necesitamos varios elementos.
3.1 - El modelo a utilizar
El primer punto que necesitamos es un modelo, podemos utilizar cualquiera open source desde hugging face. O utilizar los propios de azure.
En mi caso voy a utilizar llama3 porque es un modelo pequeño que cumple con lo que necesito.
NOTA: Antes de continuar, mencionar que como vamos a ejecutar este proceso completamente en local necesitamos un modelo de embeddings que se especialice en convertir texto a vectores, en mi caso, estoy utilizando nomic-embed-text
3.2 - Base de datos vectorial
El segundo paso es una base de datos vectorial, para un ejemplo pequeño como el que vamos a ver hoy podríamos utilizar la memoria de nuestra máquina, pero se entiende que en producción debemos utilizar un sistema real donde tenemos varias opciones para la base de datos vectorial: Qdrant, weaviate, Pinecone o PostgresSQL con la extensión pgvector, o finalmente cualquier de las soluciones que nos dan los servicios en la nube.
Una vez tenemos elegido el sistema, en nuestro caso, la base de datos PostgresSQL, la montamos en un contenedor con el siguiente código y seguimos:
version: '3.8'
services:
postgres:
image: pgvector/pgvector:pg16
container_name: rag-db-local
environment:
POSTGRES_DB: rag_db
POSTGRES_USER: user
POSTGRES_PASSWORD: password
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
2.3 - Semantic Kernel
Finalmente necesitamos unir todas las piezas. Necesitamos coordinar la búsqueda de la base de datos junto a llamar a la base de datos y si bien plo podemos hacer todo manualmente, Microsoft nos proporciona una herramienta increíble, semantic kernel.
Semantic Kernel es un SDK que actúa como orquestador para ponerlo todo junto.
En nuestro caso:
- Se conecta a la base de datos vectorial para almacenar y buscar información.
- Define el flujo rag de recibir pregunta, generar los embeddings, buscar, construir el prompt y llamar al LLM
- Adicionalmente podemos integrar plugins y funcionalidades llamando y conectando otras APIs o servicios.
Con esto ya estamos capacitados para construir RAG en forma local.
3 - Implementar RAG en local con C#
Ahora simplemente ponemos todo lo que hemos visto en práctica.
3.1 - Preparar el entorno para RAG local
Lo primero de todo es preparar el entorno, donde tenemos que coger esa base de datos vectorial que hemos mencionado, en nuestro caso va a ser postgres con pgvector, personalmente la he puesto en un docker compose como hemos visto anteriormente, ahora únicamente debemos correrla con docker-compose up -d.
Si has estado siguiendo los capítulos anteriores sabrás que hemos estado utilizando ollama, y vamos a seguir con él, en mi caso, tengo instalado llama3, si no tienes ollama te recomiendo mirar el primer vídeo de la serie y para descargarlo simplemente ejecuta ollama pull llama3.
Además, necesitas un modelo de embeddings, el cual se especializa en convertir texto a vectores.
ollama pull nomic-embed-text
Una vez los tienes descargados y ollama corriendo en tu máquina ya están listos para recibir peticiones.
3.2 - Configurar el proyecto de C# para rag local
Ahora pasamos a configurar nuestro proyecto de C#, puedes utilizar cualquier tipo de proyecto, yo para mostrar el caso voy a utilizar un proyecto de consola, pero puede ser lo que quieras. Lo único que vas a necesitar son una serie de paquetes de nuget:
Microsoft.SemanticKernel
Microsoft.SemanticKernel.Connectors.Ollama // <- en preview
Microsoft.SemanticKernel.Plugins.Memory // <- en preview
Npgsql // postgress
Ahora en la misma carpeta, puedes crear un fichero que se llame data.txt, en mi caso he puesto un resumen sobre mi, porque luego mostrar que funciona es más sencillo, en el caso de estar en producción le darías datos sobre tus elementos del sistema.
NetMentor is the personal brand of Iván Abad, Microsoft MVP and backend engineer specialized in .NET, C#, and distributed systems. Through his blog, YouTube channel, and courses, NetMentor makes complex topics like architecture, microservices, cloud, testing, and AI/LLMs accessible to Spanish-speaking developers in a clear and practical way.
With a direct and educational style, NetMentor blends theory with real-world experience from large-scale projects, sharing best practices, common pitfalls, and lessons learned from day-to-day software engineering. He is also the author of books such as Construyendo Sistemas Distribuidos and Guía completa full stack con .NET, reinforcing his commitment to accessible, high-quality learning.
NetMentor is not just a technical resource—it’s a growing community that fosters continuous improvement, curiosity for new technologies, and a passion for building robust, scalable, and well-designed software.
Ahora voy a compartir el código, normalmente esto no se hace con C#, de hecho te habrás dado cuenta que la mayoría de paquetes están en preview, por lo que muchas de las funcionalidades son experimentales y tenemos que tener eso en cuenta ya que este código es válido hoy, pero puede que cambie. Aún así, la idea o el proceso seguirá siendo el mismo.
En el código hacemos lo siguiente, primero definimos toda la información por defecto, coonnection string, ollama endpoint, modelos, y los ficheros a leer.
var connString = "Host=localhost;Port=5432;Database=rag_db;Username=user;Password=password;";
var ollamaEndpoint = new Uri("http://localhost:11434");
var textModel = "llama3";
var embedModel = "nomic-embed-text";
var collection = "datos_collection";
var inputFileName = "datos.txt";
var inputFilePath = Path.Combine(AppContext.BaseDirectory, inputFileName);
var builder = Kernel.CreateBuilder();
builder.AddOllamaTextGeneration(modelId: textModel, endpoint: ollamaEndpoint);
builder.AddOllamaEmbeddingGenerator(modelId: embedModel, endpoint: ollamaEndpoint);
var kernel = builder.Build();
var textGen = kernel.GetRequiredService<ITextGenerationService>();
var embedGen = kernel.GetRequiredService<IEmbeddingGenerator<string, Embedding<float>>>();
En un mundo de producción toda esta información estará en ficheros de configuración o incluso tener más ficheros en vez de uno solo (es uno para simplificar).
3.3 - Conexión a la base de datos
Ahora viene a conectarse a la base de datos y asegurarse de que todo lo que necesitamos está disponible.
var dimProbe = await embedGen.GenerateAsync("probe");
var dimensionLenght = dimProbe.Vector.Length;
var tableName = "rag_items";
var createSql = $"CREATE TABLE IF NOT EXISTS {tableName} (\n id TEXT PRIMARY KEY,\n content TEXT,\n embedding vector({dimensionLenght})\n);";
await using (var cmd = new NpgsqlCommand(createSql, conn))
await cmd.ExecuteNonQueryAsync();Igual que antes, en un entorno de producción, esta sección estaría abstraído de este proceso.
3.4 - Ingesta de datos
La parte más compleja viene ahora, porque es la ingesta de nuestros ficheros en la tabla de vectores.
En este caso leemos el fichero y lo convertimos en chunks para introducirlo a la base de datos:
Console.WriteLine($"Reading and ingesting '{inputFileName}' into table '{tableName}'...");
var text = await File.ReadAllTextAsync(inputFilePath);
var chunks = ChunkText(text, maxChars: 1000, overlap: 100).ToList();
int i = 0;
foreach (var chunk in chunks)
{
var id = $"doc-{i++}";
var emb = await embedGen.GenerateAsync(chunk);
var embStr = ToPgVectorLiteral(emb.Vector.Span);
var upsert = $"INSERT INTO {tableName} (id, content, embedding) VALUES (@id, @content, CAST(@emb AS vector({dimensionLenght})))\n ON CONFLICT (id) DO UPDATE SET content = EXCLUDED.content, embedding = EXCLUDED.embedding;";
await using var cmd = new NpgsqlCommand(upsert, conn);
cmd.Parameters.AddWithValue("id", id);
cmd.Parameters.AddWithValue("content", chunk);
cmd.Parameters.AddWithValue("emb", embStr);
await cmd.ExecuteNonQueryAsync();
}
Console.ForegroundColor = ConsoleColor.Green;
Console.WriteLine($"Ingested {chunks.Count} chunks. Ready for questions.\n");
Console.ResetColor();
static string ToPgVectorLiteral(ReadOnlySpan<float> vector)
{
// Format like: [0.1, -0.2, ...] with invariant culture
var sb = new StringBuilder();
sb.Append('[');
for (int i = 0; i < vector.Length; i++)
{
if (i > 0) sb.Append(',');
sb.Append(vector[i].ToString("G9", CultureInfo.InvariantCulture));
}
sb.Append(']');
return sb.ToString();
}Donde tenemos un método ChunkText que convierte el texto a chunks
static IEnumerable<string> ChunkText(string text, int maxChars = 1000, int overlap = 100)
{
if (maxChars <= 0) throw new ArgumentOutOfRangeException(nameof(maxChars));
if (overlap < 0) throw new ArgumentOutOfRangeException(nameof(overlap));
// Simple paragraph-aware chunker with character limit and overlap
var paras = text.Replace("\r\n", "\n").Split("\n\n", StringSplitOptions.RemoveEmptyEntries | StringSplitOptions.TrimEntries);
var current = new StringBuilder();
foreach (var p in paras)
{
var toAdd = p.Trim();
if (toAdd.Length == 0) continue;
if (current.Length + toAdd.Length + 2 > maxChars)
{
if (current.Length > 0)
{
yield return current.ToString();
// create overlap from end of previous chunk
if (overlap > 0)
{
var prev = current.ToString();
var tail = prev.Length <= overlap ? prev : prev.Substring(prev.Length - overlap);
current.Clear();
current.Append(tail);
}
else
{
current.Clear();
}
}
}
if (current.Length > 0) current.AppendLine().AppendLine();
current.Append(toAdd);
}
if (current.Length > 0)
{
yield return current.ToString();
}
}
En esta parte sería ideal que tuviéramos una librería que lo hiciera por defecto. Y en teoría existe que es Microsoft.SemanticKernel.Connectors.PgVector, pero esta en preview y o bien no funciona como está esperado o está incompleta, porque no tenía forma de hacerlo automáticamente así que por ahora, estos pasos son manuales, en el futuro espero que cambie.
3.5 - Creación de chat con RAG en local
Finalmente solo nos queda crear el chat, donde en un bucle continuo vamos a estar realizando preguntas. Observa qué estamos consultando la base de datos cada vez que estamos haciendo una pregunta.
Console.WriteLine("Ask a question (empty line to exit):");
while (true)
{
Console.ForegroundColor = ConsoleColor.Cyan;
Console.Write("Question> ");
Console.ResetColor();
var question = Console.ReadLine();
if (string.IsNullOrWhiteSpace(question)) break;
// Retrieve top-k relevant chunks using cosine distance
var embeddedQuestion = await embedGen.GenerateAsync(question);
var ebbeddedQuestionString = ToPgVectorLiteral(embeddedQuestion.Vector.Span);
var searchSql = $"SELECT id, content, (1 - (embedding <=> CAST(@qemb AS vector({dimensionLenght})))) AS similarity\n FROM {tableName}\n ORDER BY embedding <=> CAST(@qemb AS vector({dimensionLenght}))\n LIMIT 4;";
await using var sCmd = new NpgsqlCommand(searchSql, conn);
sCmd.Parameters.AddWithValue("qemb", ebbeddedQuestionString);
var sb = new StringBuilder();
await using (var reader = await sCmd.ExecuteReaderAsync())
{
while (await reader.ReadAsync())
{
var content = reader.GetString(reader.GetOrdinal("content"));
sb.AppendLine("- " + content.Trim());
}
}
var prompt = $@"You are a helpful assistant. Respond strictly based on the provided context.
If the answer is not in the context, reply that you don’t know.
Context:
{sb}
Question: {question}
Answer:";
try
{
var response = await textGen.GetTextContentAsync(prompt, kernel: kernel);
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine("Answer> " + (response?.ToString() ?? "(no answer)"));
Console.ResetColor();
}
catch (Exception ex)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("Error: " + ex.Message);
Console.ResetColor();
}
}
Además al prompt le hemos pasado un contexto y este es el resultado final:

NOTA: ten en cuenta que correr estos sistemas en local es algo lento, pero al margen de eso, funciona todo a la perfección

