Este vídeo viene a raíz de un comentario que hicieron en mi canal en el vídeo sobre Runtime async, donde un usuario decía que, si necesitaba la respuesta de una base de datos o de un servicio, no hacía falta utilizar async await y que no usara un método asíncrono.
Ahí le contesté que esa afirmación no era correcta. En este blog tengo ya algún que otro vídeo sobre async await, pero hoy vamos a ir más en profundidad y ver cómo funciona por detrás, en la parte física, ya que se ve y entiende mucho más fácil.
Gran parte de este post es agnóstico al lenguaje de programación que utilices. Como este blog es de .NET, el código y el caso específico es con sintaxis de C#, pero la idea es la misma. No vamos a hablar del state machine de .NET o de cualquier otro lenguaje, ni de cómo las variables se ponen en el heap. En vez de eso, vamos a comprender el flujo que await hace desde el código a través del thread pool, cómo interacciona con el sistema operativo e incluso con el hardware de la máquina.
Si alguna vez te has preguntado por qué tu API se cae con 100 usuarios si "no está haciendo nada", este post es para ti.
Tabla de contenidos
1 - El coste de esperar al código síncrono
Antes de entender async await tenemos que entender el problema que arregla.
Si has trabajado en .NET deberías estar haciendo async/await en todos las llamadas que van fuera de tu servicio o de tu código, ya sea para acceder al sistema de ficheros, a la base de datos, a un servicio externo o donde sea.
Y el motivo por el que usamos async await es para evitar que el thread esté bloqueado. Pero, ¿Qué significa estar bloqueado? Lo mejor es verlo con un ejemplo;
Cuando tenemos una llamada a una base de datos con el siguiente código:
var data = repository.getByID(id);Esto es lo que sucede por detrás:
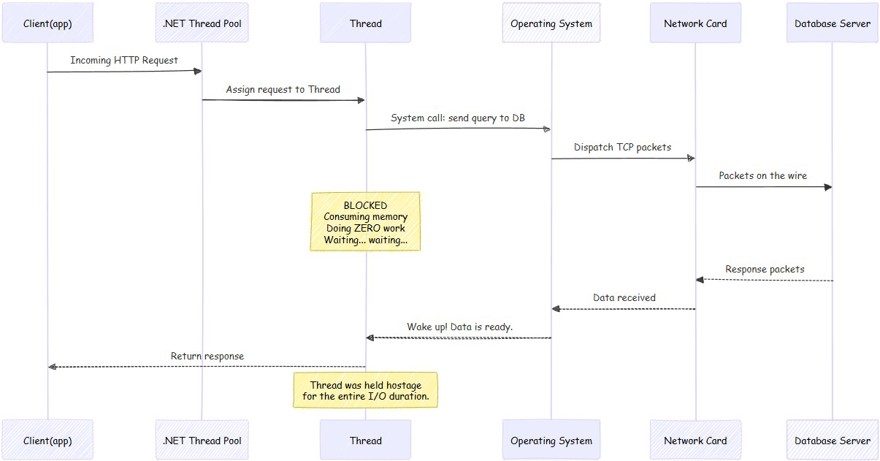
A - El thread pool de .NET le dice al sistema operativo que tiene que hacer una llamada a la base de datos.
B - El sistema operativo, se encarga de enviar la información a través de la tarjeta de red, que es la que pone los datos en el cable como tal.
C - Esperamos a que la base de datos conteste. Y esto puede ser desde milisegundos como a esperas mucho más largas.
D - Durante el tiempo de espera, el thread que se encarga de hacer la llamada en tu máquina no está haciendo nada, simplemente esperando a que la llamada vuelva. El thread no está únicamente esperando, sino que consume memoria también.
Como siempre digo, el gran problema viene cuando tenemos un gran número de requests por minuto, ya que ahí es donde más notaremos el impacto, si de repente empiezas a recibir cientos o miles de request por minuto, es muy probable que termines teniendo thread pool starvation un tema que ya vimos en este blog.
La clave a entender aquí es que la CPU está esperando, sin hacer nada mientras nuestro proceso está en otra máquina y al volver a la nuestra simplemente continua con el proceso.
2 - Qué cambia realmente cuando usamos código asíncrono?
Ahora vamos a ver qué pasa cuando utilizamos async/await de forma correcta:
var data = await repository.getByID(id);
Como vemos simplemente hemos añadido la palabra clave await en la llamada, y luego el método como tal tiene async Task, pero la parte importante es await ya que cambia la parte física de lo que pasa por detrás.
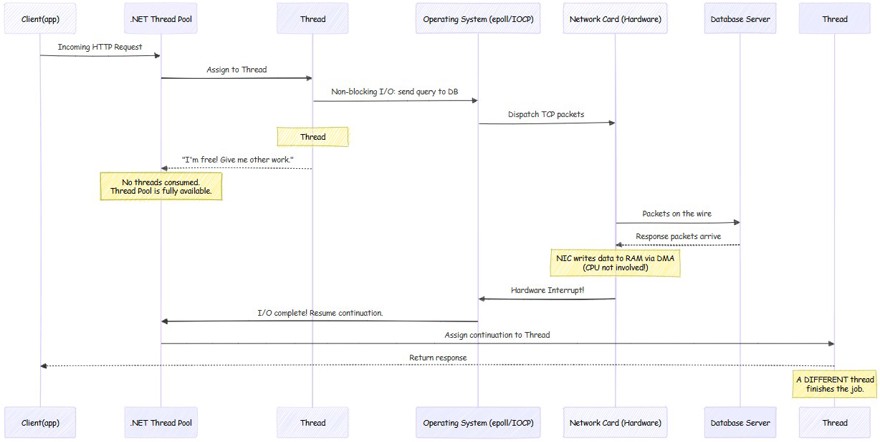
A- al utilizar async await en .NET el propio runtime de .net hace una llamada no bloqueante al sistema operativo (linux: epoll, Windows IOCP). Esta llamada no bloqueante es un mecanismo a nivel del kernel generado para este caso de uso exactamente, donde nuestra aplicación indica que quiere hacer una llamada y que no va a esperar por la respuesta, es el propio sistema operativo quien tiene que notificar a la aplicación.
B- El thread vuelve al pool, y este es el punto esencial para entender la diferencia entre uno y otro. En el ejemplo anterior veíamos cómo el thread se quedaba esperando; En este caso devolvemos el thread al thread pool de forma inmediata y está disponible para hacer cualquier otro trabajo.
C - Es el Sistema operativo a través de la interfaz de la tarjeta de red quien está esperando a que la llamada sea devuelta. Para quien no lo sepa, las interfaces de red (NIC) llevan un pequeño procesador para realizar esta función. Y notifica al sistema operativo a través de un hardware interrupt (wikipedia: https://en.wikipedia.org/wiki/Interrupt) de que la operación I/O ha sido completada. Finalmente el sistema operativo notifica al runtime de .NET.
D - Todo esto es posible porque el thread pool de .NET tiene threads en sí mismo que monitorean estas notificaciones. Al recibir la notificación del sistema operativo, el runtime de .NET coge cualquier thread del threadpool para continuar con el proceso, no tiene por qué ser el mismo.
Ahora que puedes ver la diferencia física entre utilizar métodos asíncronos o no, puedes comprender la importancia de utilizarlos de forma correcta. Ya que si ponemos un extremo donde la base de datos tarda 1 segundo en responder, en el primer ejemplo tenemos un thread parado sin hacer nada durante un segundo, mientras que utilizando async await durante el tiempo de espera, el thread puede realizar otras tareas.
3 - El hardware como cuello de botella
Por norma general solemos tener los mayores problemas o bloqueos debido al hardware, en concreto a la CPU. La CPU determina cuántos threads pueden ejecutarse a la vez, determinados por cuántos cores tiene dicha CPU.
Ojo, esto no quiere decir que solo puedas tener un único thread, una aplicación puede crear threads, pero únicamente uno (en el caso de 1vCPU) va a ser ejecutado de forma simultánea en la CPU.
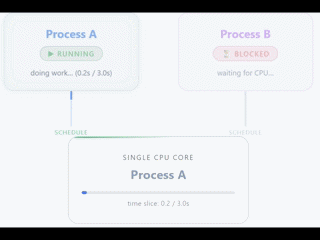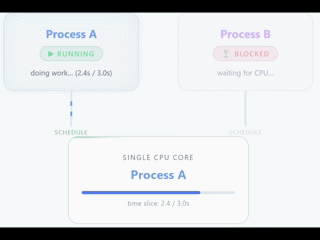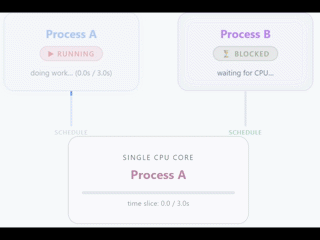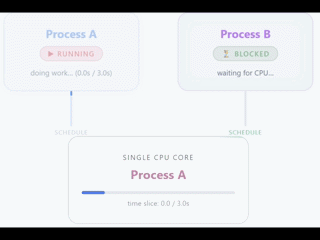
El resto de threads van a estar esperando hasta que la CPU esté liberada. Con 1vCPU puedes tener una sensación de trabajo en simultáneo porque la CPU cambia entre threads de una forma muy rápida y eficiente, pero en verdad es únicamente una ilusión.
Si lo que buscas es paralelismo, lo que necesitas es 2vCPU (o más), lo que significa que 2 threads pueden realizar tareas en la CPU de forma simultánea.
3.1 - El bloqueo en máquinas pequeñas
Aquí hay que tener en cuenta que más threads no significa más poder de computación. Añadir threads no crea procesamiento adicional de la nada simplemente crea más threads que van a estar compitiendo por un número finito de CPUs.
Pongamos el ejemplo de una API: recibimos una petición y tenemos que consultar la base de datos o un servicio externo. El thread realiza la llamada y a partir de ese momento, deja de hacer trabajo útil. Pero sigue existiendo, lo que significa que ocupa memoria y ocupa un slot en el thread pool. Está simplemente esperando, consumiendo recursos que podrían estar siendo utilizados por otras requests.
Por eso utilizar async/await o programación asíncrona en tu lenguaje de programación importa tanto. Porque evita que tengamos threads ahí perdidos gastando recursos de hardware y del sistema operativo durante la espera.
La gran mayoría de problemas que te vas a encontrar de thread pool starvation son muy difíciles de detectar e incluso de debugear, porque necesitas una carga muy alta de peticiones y saber que es lo que puede estar pasando.
4 - La paradoja de los VPS de 5$
Todos los desarrolladores, donde me incluyo, tenemos un montón de apps en GitHub, una forma de darles vida es con un VPS, donde los tenemos disponibles desde 5$ al mes por 1 vCPU, aunque yo, personalmente recomiendo 2 vCPU para poner todas tus aplicaciones.
Enlace a VPS barato con descuento del 10% con el código NETMENTOR
Y con este VPS de 5$ que tiene 1 o 2 vCPU somos capaces de tener docker, múltiples aplicaciones,una o más bases de datos y además recibir miles de usuarios recurrentes diarios sin que todo colapse. ¿Cómo es esto posible?
La respuesta es simple, la gran mayoría de trabajo no es trabajo heavy de CPU, sino que es esperar.
Pongamos como ejemplo mi blog, cuando un usuario consulta una página, qué es lo que hace el sistema? Parsear la request HTTP, correr algo de lógica y validaciones, llamar a la base de datos y transformar el objeto en el DTO que va a ser devuelto a la interfaz.
Exceptuando el trabajo de la base de datos, el resto de acciones suceden en microsegundos. Si la llamada desde el punto de vista del usuario son 200ms, la realidad es que eso no es 200ms de tiempo de CPU, sino que la gran mayoría es tiempo de espera, ya sea para el motor de la base de datos, u otra llamada a un servicio externo.
Ahora entra la velocidad del procesador, o los Gigahercios (GHz) a cuantos más GHz más ciclos de reloj por segundo podemos hacer, un procesador normalito de un VPS medio va a ser en torno a 2 o 2.5GHz, esto quiere decir que va a procesar 2.5 mil millones de ciclos de reloj cada segundo, que en la práctica da para una cantidad enorme de instrucciones procesadas.
Así que por eso, para niveles de tráfico bajo, tenemos suficiente con 1 o 2vCPU, aunque yo recomiendo 2 para cualquier desarrollador que tenga varias apps de hobby, porque incluso aunque tengamos algo de bloqueo, va tan rápido que pasa inadvertido para nuestros usuarios.
En aplicaciones empresariales, con clientes de pago, obviamente tendremos que escalar, tener réplicas y hacer las mejores prácticas posibles para que nuestros usuarios no se vean afectados por bloqueos.
Si quieres saber mas sobre escalado y replicas, puedes verlo en mi libro de sistemas distribuidos.

