Lo que empezó como un simple autocompletado está evolucionando a unos niveles nunca vistos. Hoy a la vista de que mi último contenido sobre IA os gustó muchísimo he decidido ampliar con algo que se me ha pedido constantemente. Comparaciones con otras Inteligencias artificiales a la hora de trabajar de forma profesional como desarrollador.
Ínidice
Nota: este post está generado a julio de 2025, en el futuro las cosas pueden cambiar y seguramente lo hagan.
1- Descripción del escenario problema
Vamos a realizar una única tarea técnica pensada para replicar una situación real de nuestro día a día laboral.
En este caso, le voy a pedir que implemente el patrón outbox a un microservicio en concreto dentro de mi proyecto de Distribt, el cual para lo que no lo conocéis, es un proyecto que muestra sistemas distribuidos.
Todas las IAs van a recibir el mismo prompt inicial y ya de ahí veremos a dónde nos lleva el experimento.
La tarea/Promp inicial es el siguiente

La cual es esta tarea de GitHub, y TODOS los resultados se pueden ver en las PR enlazadas, tanto en este post, como en la propia tarea.
La traduccion al español es la siguiente:
Los productos son una parte fundamental del sistema. Debemos asegurarnos de que, cuando se cree o actualice un Producto, el evento se propague correctamente.
Hay varios pasos para lograrlo:
- Crear una tabla para almacenar los mensajes de la outbox.
- La inserción en la tabla de outbox debe ocurrir dentro de la misma transacción que la creación o modificación del Producto.
- Necesitamos un procesador en segundo plano que lea esa tabla y publique el mensaje; una vez publicado, el registro debe actualizarse marcándolo como enviado.
- No olvides añadir pruebas unitarias.
Siéntete libre de modificar cualquier parte del sistema, pero asegúrate de no provocar cambios incompatibles.
El evento se genera en estos dos lugares:
Creación: https://github.com/ElectNewt/Distribt/blob/main/src/Services/Products/Distribt.Services.Products.BusinessLogic/UseCases/CreateProductDetails.cs#L40
Actualización: https://github.com/ElectNewt/Distribt/blob/main/src/Services/Products/Distribt.Services.Products.BusinessLogic/UseCases/UpdateProductDetails.cs#L27Podemos argumentar que es un tiquet muy bien escrito, y lo que estoy pidiendo es claro, pero esque esa es la realidad de pedirle elementos a la IA, debemos ser concisos en lo que buscamos.
1.1 - Criterios de evaluación
Para evaluar a las diferentes inteligencias artificiales voy a utilizar baremos muy simples, pero que yo considero básicos.
- Corrección funcional (0-20)
- Cumpla con los requisitos (0-10)
- Mantenible (0-10)
- Fácil de entender y actualizar (0-5)
- Valoración de los test unitarios (0-2)
- Consistencia en estándares y estilo (0-3)
- Resta puntos si veo algún tema de eficiencia que sea terrible, aunque en este caso no creo.
- Resta puntos tener problemas de seguridad, aunque en este caso no debería.
- Experiencia de desarrollo (0-10)
- Velocidad de entrega. (0-6)
- Interacciones necesarias. (0-4)
Como podemos ver cada sección tiene un peso distinto en la evaluación. Y creo que es bastante justa.
No estoy comparando el número de tokens o el consumo porque sinceramente todo son subscripciones de coste fijo, así que tanto da. De todas formas, si lo miramos desde un punto de vista empresarial, da igual que cueste $20 que $200, si mejora el rendimiento un 20/30% sale a cuenta.
2 - Evaluación de Asistentes de código para tareas técnicas
He elegido los siguientes asistentes de código para realizar la tarea.
- Codex
- Copilot dentro de Github
- Cursor
- Claude CLI
- Warp Terminal
- Gemini code assist
¿Por qué? Porque son los más famosos, y más comunes, también he querido ignorar otros como Grok, ya que son simplemente un chat en la web, y eso no es un asistente de código aunque sea capaz de programar bien.
En resumen, si le tengo que pasar código de forma manual, no lo quiero.
Antes de empezar con las evaluaciones, como no quiero que este post sea un scroll infinito, no voy a poner todos los pasos. Pondré una explicación de cada uno de los asistentes durante la evaluación, recuerda que en cada sección tendrás una PR enlazada con los cambios que cada asistente ha realizado.
En caso de que necesites más contexto, lo puedes encontrar en el vídeo enlazado.
También me he puesto como límite 45 minutos de tiempo, para ver si de verdad ayudan.
2.1 - Codex como asistente de código, Evaluación
Empecemos con el que ya he trabajado anteriormente como pudimos ver en este post.
Está incluido en la suscripción plus de ChatGPT (la de $20) y para configurarlo le tienes que dar acceso a tu GitHub, todo desde su interfaz y de una forma muy sencilla, desde ahí, tienes un chat donde le puedes pedir una tarea.
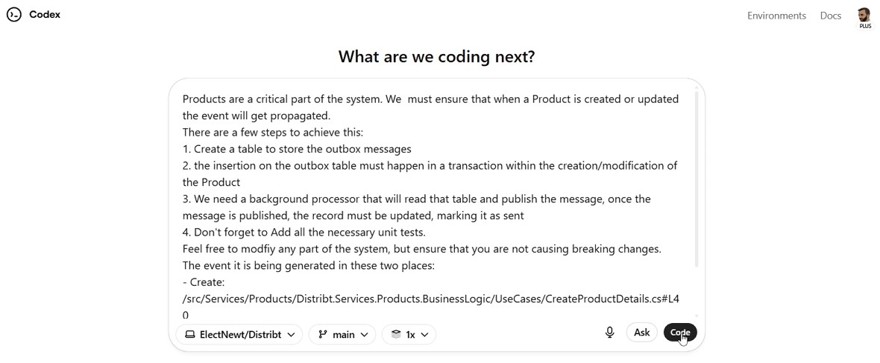
Una vez la envías, se pone a trabajar.
Código -> https://github.com/ElectNewt/Distribt/pull/47
NOTA: Codex tiene una CLI que podría haber utilizado, pero está en modo experimental para windows, y personalmente prefiero la interfaz web.
2.2 - Copilot como asistente de código
Muchos conocéis copilot como el asistente que está dentro de un IDE, ya que lleva siendo utilizado varios años, es posiblemente el asistente más antiguo de todos.
Y la verdad a mi me suele ir bien, tiene el modo que actúa en el código escribiendo y el modo chat que va muy bien en vez de buscar la solución directamente en internet.
Pero eso no es lo que vamos a probar en este vídeo. Desde hace un tiempo, Microsoft añadió en GitHub la posibilidad de asignarle tareas a Copilot para las cuentas pro y enterprise.
Para trabajar con él, lo único que tenemos que hacer es asignar una tarea a copilot en GitHub:
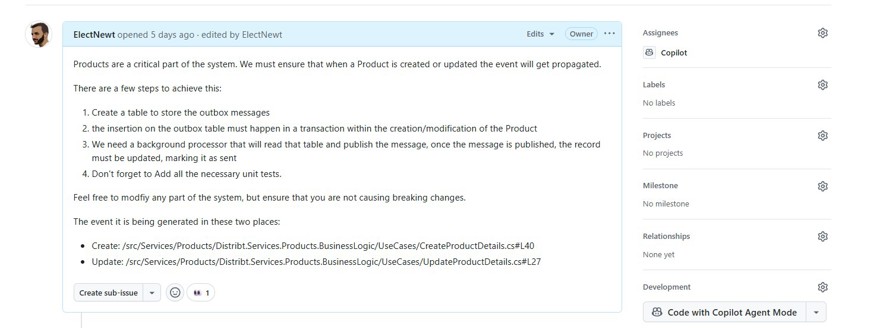
Y con esto se pone a trabajar.
Código -> https://github.com/ElectNewt/Distribt/pull/48
2.3 - Cursor como asistente de código
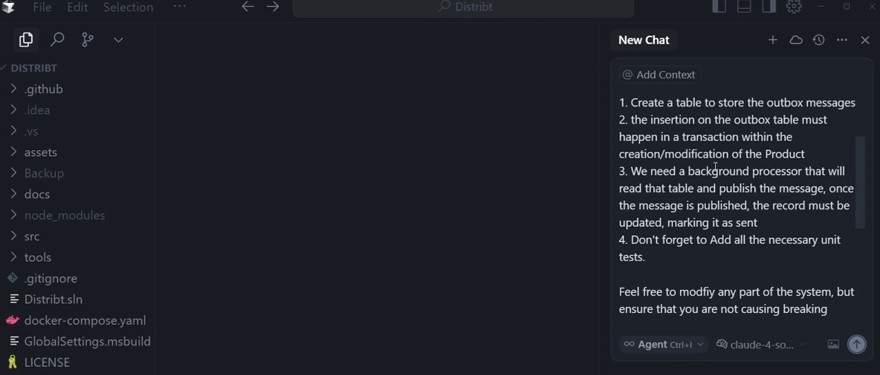
Desde el primer momento que salió la IA y salieron los asistentes de código hemos tenido nuevos IDEs que han intentado aprovechar esto. El más famoso de todos es Cursor, donde tienes un chat interactivo y le puedes pedir acciones. Este chat tiene cargados múltiples modelos de lenguaje, en nuestro caso vamos a utilizar claude.
Si alguien está interesado, la versión pro de cursor cuesta $20 al mes, y es la que yo tengo ahora mismo. El agente que voy a utilizar es Claude 4 Sonet.
Una vez le pones el prompt, empieza a trabajar.
2.4 - Claude Code como asistente de código
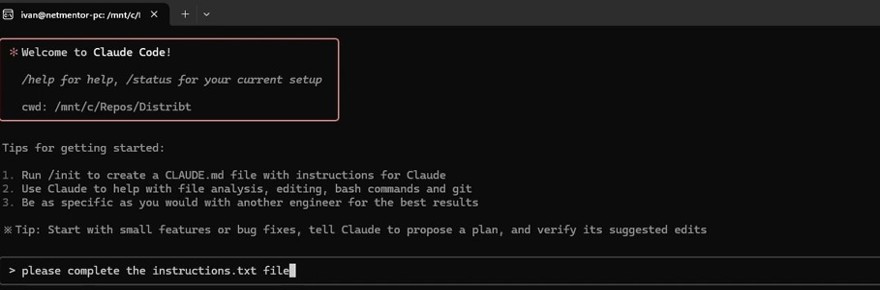
Anthropic es la empresa tras Claude, el LLM más popular y que siempre “gana” en todos los benchmarks de programación, recientemente han sacado una CLI, Claude code, que por $17 te permite integrar el asistente de código y realizar consultas.
Así que nuestras interacciones son con una terminal directamente.
2.5 - Warp CLI como asistente de código
En este canal la he mencionado varias veces, la terminal mas poderosa del mercado es Warp, y con su reciente lanzamiento de Warp 2 siguen en la cima en lo que a terminales se refiere.
En esta terminal le podemos indicar un modo agente, donde un agente, en nuestro caso claude (aunque soporta más) nos puede ayudar a completar nuestra tarea de una forma efectiva. Por detrás no va directamente a claude, sino que tiene ciertas implementaciones (no es lo mismo que utilziar claude code)
Tiene una versión de pago, pero para proyectos de hobby, con la versión gratuita nos sobra, para el entorno profesional no. Y tengo un código de referido si quieres utilizarlo.
De hecho con la gratuita nos ha indexado el proyecto sin ningún problema.
Código -> https://github.com/ElectNewt/Distribt/compare/ai-test/202507-Baseline...ai-test-202507-Warp?expand=1
2.6 - Gemini Code Assist como asistente de código
Para terminar, vamos a probar el asistente de código que se lanzó el último, en este caso también es una CLI y es la de google. Y para la gran mayoría de desarrolladores nos sirve con la versión gratuita ya que trae 1000 requests diarios, mientras que la de pago trae únicamente 1500 además de funcionalidades extras que no necesitamos para este vídeo.
Así que le pasamos el prompt y vamos al lío.
3 - Evaluación de los resultados
Como he indicado antes, si necesitas ver el proceso, está disponible en el vídeo.
3.1 - Experiencia de desarrollo
Voy a empezar analizando la experiencia de desarrollo. La tarea en sí es sencilla, pero tiene un par de detalles importantes como convertir ciertas acciones en una transacción, eso hace que la IA sufra, lo que puede hacer que tengamos que poner más interacciones de las necesarias.
Los criterios de evaluación aquí son los siguientes:
- Experiencia de desarrollo (0-10)
- Velocidad de entrega. (0-6)
- Interacciones necesarias. (0-4)
Nota: en la velocidad de entrega, también cuenta el tiempo que utilizo en revisar el código, no me sirve de nada que sea muy rápido si luego tardo 10 veces más en revisarlo.
Este es el resultado de esta prueba:

La explicación a cada punto la tienes a continuación.
3.1.1 - Experiencia de desarrollo con Cursor
Cursor ha sido una de las peores experiencias. cada cambio que necesita implementar, te pide que lo apruebes. Lo cual puede no estar mal, pero no espera a que lo aceptes para seguir, lo que puede generar código que directamente no compila, y si asumes que lo vas a aceptar todo, simplemente haz el cambio sin necesitar input del usuario.
En el tema de la velocidad, Cursor en sí ha sido muy rápido en hacer los cambios, el problema principal es que eran erróneos y ha llevado muchísimo tiempo la revisión y por supuesto varias iteraciones. Contando con el tiempo invertido revisando el código Cursor no está entre los más rápidos, eso seguro.
Pequeñas modificaciones manuales fueron necesarias para que el código compilara, lo que lleva tiempo.
Experiencia de desarrollo: 4
- Velocidad de entrega. 3
- Interacciones necesarias. 1
3.1.2 - Experiencia de desarrollo con Gemini
Gemini es una CLI, y la experiencia en general está bien, es aceptable, el prompt inicial, no deja especificar intros o un prompt largo, aunque se soluciona con especificar las instrucciones en un fichero, no es ideal, pero es una solución.
La velocidad de las iteraciones ha sido buena, muy buena, y la implementación también ha estado bien. aún así, en el código hacia cosas que no necesitaba para el proceso, incluso después de haberle dicho en otro prompt que no lo hiciera. De hecho el producto final no funciona como es esperado.
Pequeñas modificaciones manuales fueron necesarias para que el código compilara, lo que lleva tiempo.
Experiencia de desarrollo: 3
- Velocidad de entrega. 1
- Interacciones necesarias. 2
3.1.3 - Experiencia de desarrollo con Github Copilot
A diferencia de cualquier otra IA del mercado, GitHub copilot está directamente integrado en GitHub, y para que se ponga a trabajar en una tarea simplemente hay que asignarle dicho ticket.
De ahí, empieza a trabajar en segundo plano y te notifica cuando termina. Es algo lento en comparación al resto de soluciones.
El propio agente no tiene permisos para correr las github actions, pero internamente ejecuta los tests y se asegura de que todo funciona. Al terminar, crea una pull request que se puede revisar y permite comentarios que el propio agente arreglará.
En este caso únicamente necesité 3 comentarios y esa fue la única interacción junto con correr la build de forma manual. No hubo ninguna otra intervención manual al código.
Experiencia de desarrollo: 8
- Velocidad de entrega. 4
- Interacciones necesarias. 4
3.1.4 - Experiencia de desarrollo con Warp
Warp es una terminal, así que la experiencia es similar a las otras aplicaciones de consola, la diferencia es que no me iba preguntando todo el rato permiso para cambiar código.
Desafortunadamente el proceso no fue rápido. Y aquí entra el tema de los tests. El proceso de desarrollo de la lógica principal fueron 3 minutos, que es nada, pero los test tienen complicación y se tardó aproximadamente unos 18 minutos para escribir dichos tests. Además a mitad del proceso hizo timeout (código de estado 504), que si bien no fue un problema muy gordo, requiere una acción del usuario.
Dejando al margen esos 18 minutos inesperados, el código requiere unos cambios y la segunda iteración únicamente tardó 2 minutos, aunque la paré cuando ví que quería escribir los tests. Lo que significa que el usuario tiene que estar pendiente de lo que la IA está haciendo.
Pequeñas modificaciones manuales fueron necesarias para que el código compilara.
Experiencia de desarrollo: 5
- Velocidad de entrega. 3
- Interacciones necesarias. 2
3.1.5 - Experiencia de desarrollo con Claude
Claude es otra CLI, y tampoco permite prompts largos, así que la solución es crear un fichero con el prompt. No es ideal, pero funciona. Claude es con diferencia el más rápido de todos, y hace un trabajo decente con esa velocidad pero no perfecto.
Requiere un input constante por parte del usuario cada vez que tiene que ejecutar un comando aunque puedes especificar aceptar todos una vez por cada comando.
En una primera interacción ha creado la mayoría del código, aunque no compila, y tiene varias cosas mal así como una capa extra que en mi opinión no es necesaria.
En una segunda iteración esos cambios están arreglados, pero detecté varios fallos, de hecho, si habéis visto la parte anterior, hemos tenido bastantes interacciones, cuatro en total, y pedía mas.
Pequeñas modificaciones manuales fueron necesarias para que el código compilara.
Experiencia de desarrollo: 3
- Velocidad de entrega. 3
- Interacciones necesarias. 0
3.1.6 - Experiencia de desarrollo con Codex
Volvemos a las interfaces web, esta vez con OpenAI Codex donde podemos integrar repositorios de GitHub. Aquí tenemos un chat, tanto para hablar del proyecto como para pedirle tareas.
Con el prompt inicial, fue capaz de devolverme algo muy estructurado y fácil de leer, que necesitaba unos pequeños cambios, los cuales se pueden especificar en la propia interfaz web. Con esta segunda iteración todo estaba bien y se puede crear la PR desde la propia interfaz.
La única pega que yo le veo es que no puedes ver la diferencia entre las iteraciones de codex, cada vez que revisas el código lo tienes que revisar entero porque no sabes qué es lo que ha cambiado.
Y es relativamente rápido, la primera iteración fueron 13 minutos y la segunda 4 minutos. Sin tener ningún input más que el par de comentarios en la revisión. Todo el código compila bien y los test pasan.
Una pega con respecto a la velocidad es que tienes que estar pendiente de la web para revisar, aunque esto es con todos menos con github coding agent que te llega un email.
Experiencia de desarrollo: 8
- Velocidad de entrega. 5
- Interacciones necesarias. 3
3.2 - Puede la inteligencia artificial generar código funcional?
Una de las preguntas más comunes en el mundo IT ahora mismo es si el código de la IA es mantenible. Eso es lo que vamos a verificar en este punto.
He de decir, que la implementación es muy similar en todos ellos.
- Corrección funcional (0-20)
- Cumpla con los requisitos (0-10)
- Mantenible (0-10)
- Fácil de entender y actualizar (0-5)
- Valoración de los test unitarios (0-2)
- Consistencia en estándares y estilo (0-3)
Resta puntos si veo algún tema de eficiencia que sea terrible, aunque en este caso no creo.
Resta puntos tener problemas de seguridad, aunque en este caso no debería.

El apartado de cumplir con los requisitos es muy sencillo, tanto actualizar como crear tienen que usar una tabla outbox, dando igual como se implemente. Que el Background worker esté presente y finalmente que tengamos tests de los casos de uso y funcionen.
3.2.1 - Puede Cursor crear código funcional?
La experiencia con Cursor ha sido confusa para mi, de primeras generó una cantidad ingente de ficheros, sin mantener ningún tipo de estilo comparado a lo que ya había.
Ha creado código duplicado y que no se usa, fuera del código también ha puesto varios readme que explican la misma idea y los que personalmente pienso que no aportan nada.
Ha creado nuevas clases sin quitar las viejas, aunque esto es algo que fallaron la mayoría. Los test unitarios son muchos, y la gran mayoría no pasan debido al punto extra de entity framework y la implementación de la base de datos en memoria.
Corrección funcional 12
- Cumpla con los requisitos 8 (faltan unit tests que funcionen)
- Mantenible 4
- Fácil de entender y actualizar 3
- Valoración de los test unitarios 0
- Consistencia en estándares y estilo 1
3.2.2 - Puede Gemini crear código funcional?
De primeras todo parecía super bien con Gemini, pero ha terminado siendo un proceso muy frustrante debido a que no entendía bien las instrucciones que se le solicitaban.
Estaba constantemente creando un sistema para publicar eventos con rabbitMQ, pese a que la aplicación ya lo tiene, no ha sido capaz de leer el contexto.
Además ha creado dos test unitarios los cuales no son ejecutados porque el tema de las transacciones, parece que no tiene el conocimiento (que otras IAs si tienen) para arreglar ese problema. Con respecto a la base de datos, también ha creado una relación de las entidades entre la tabla producto y la de outbox, que no es del todo necesaria.
Aún así ha intentado crear el sistema de outbox en un proyecto compartido. Es la única IA que ha intentado algo así, cumpliendo con las prácticas del proyecto. \
En la práctica esto no funciona y necesita de corrección manual.
Corrección funcional 9
- Cumpla con los requisitos 6 (test no funcionan, y la implementación del backgroundworker con el rabbitMQ que ha creado no es correcta)
- Mantenible 3
- Fácil de entender y actualizar 2
- Valoración de los test unitarios 0
- Consistencia en estándares y estilo 1
3.2.3 - Puede GitHub Copilot crear código funcional?
Respuesta rotunda sí, es cierto que ha sido un poco lento, pero Copilot agent ha trabajado igual que si fuera otro desarrollador, al terminar te pone la PR, es más, dentro de Github puedes ver los diferentes commits y la lógica que ha seguido.
Revisando el código, la implementación es buena. Ha creado la nueva entidad para la tabla de outbox así como modificar el SQL. En una primera interacción ha creado un par de elementos de código que no eran necesarios, y eso fue todo lo que había que cambiar. Al margen de esto, El backgroundworker está bien montado, de hecho es el único que ha separado la lógica que debe ir dentro del backgroundWorker de la propia ejecución.
Respecto a los test es uno de los que han funcionado a la primera. Al igual que con Codex no he tenido que realizar ningún cambio de código de forma manual.
Lo único discutible es que dentro de la capa de la base de datos hay un par de IFs para valorar si es una base de datos en memoria o no, los cuales son muy grandes y se puede reducir para mejorar la mantenibilidad.
Corrección funcional 19
- Cumpla con los requisitos 10
- Mantenible 9
- Fácil de entender y actualizar 4
- Valoración de los test unitarios 2
- Consistencia en estándares y estilo 3
3.2.4 - Puede Warp crear código funcional?
La implementación final de Warp es buena, ha actualizado los casos de uso para utilizar transacciones dentro del propio caso de uso, que es mi forma preferida de implementar la solución.
Esto le ha permitido hacer mock de la capa de la base de datos en los tests, haciendo dichos test mucho más sencillos, aunque son muy extensos, podrían ser acortados un poco.
Ha creado un par de elementos que no son completamente necesarios, como una interfaz con el contrato del Background processor, pero la implementación del procesador está bien, hubiera estado ideal separar el processor de la lógica que va a ser ejecutada..
En general es un buen código.
Corrección funcional 16
- Cumpla con los requisitos 10
- Mantenible 6
- Fácil de entender y actualizar 3
- Valoración de los test unitarios 1
- Consistencia en estándares y estilo 2
3.2.5 - Puede Claude crear código funcional?
La implementación final de claude ha sido bastante buena, también es cierto que tuvimos varias interacciones más que en utilizando otros agentes. Es cierto que podría pasar a eliminar código que ya no es necesario, como pasa en la gran mayoría de las implementaciones.
La implementación del backgroundworker es correcta, desafortunadamente los tests no funcionan por el tema de las transacciones en memoria. Quizá con más prompt hubiera sido posible arreglar el problema, pero Claude es el único que ha utilizado cuatro prompts para implementar el ticket, y sigue sin estar perfecto.
Corrección funcional 13
- Cumpla con los requisitos 8 (problema con los test)
- Mantenible 5
- Fácil de entender y actualizar 3
- Valoración de los test unitarios 0
- Consistencia en estándares y estilo 2
Personalmente estoy bastante decepcionado con claude, ya que tenía unas esperanzas muy altas.
3.2.6 - Puede Codex crear código funcional?
Antes de empezar con el test, tenía una pequeña idea de lo que me iba a encontrar cuando probase a Codex, y la verdad que no ha decepcionado, ha sido un éxito.
La implementación de la tarea es correcta, podría eliminar el código de la capa de datos que ya no se utiliza pero esto es algo en lo que todos menos Warp han fallado.
Los test han sido creados correctamente y funcionan, lo único que está creando todos los tests en un único fichero en vez de tenerlos separados por clases.
La implementación del backgroundworker también es correcta.
Corrección funcional 17
- Cumpla con los requisitos 10
- Mantenible 7
- Fácil de entender y actualizar 5
- Valoración de los test unitarios 1
- Consistencia en estándares y estilo 2
4 - Conclusion final.
Estas son las evaluaciones finales:

Llevo trabajando con IA para mi día a día laboral, principalmente con Copilot bastante tiempo, entiendo que como la mayoría de quien lea hasta aquí.
De todas las IAs que he probado, todas se venden como asistentes de código o que pueden hacer programación real por sí solas. En mi opinión, solo dos de ellas cumplen con este paradigma, que son Copilot Agent y Codex, el resto, necesitan muchísimo input manual.
Lo que yo buscaba era que todos los agentes fueran capaz de programar más o menos bien de forma independiente, y si bien programan, no están ahí, dejando al margen Copilot y Codex, solo Warp ha creado el código de forma correcta, tanto los tests, como el fichero del sql, así como crear el código sin problemas de compilación.
El resto de IAs, Claude, Gemini, Cursor, o bien no entienden bien C# o no entienden el proyecto correctamente, y esto es un proyecto sencillo.
Sirven para utilizarlos de patito de goma y hacerles preguntas, pero no están capacitadas, ni de lejos para realizar las implementaciones que están haciendo Codex o Copilot.
Si yo tuviera que pagar por uno exclusivamente mi duda sería si pagar por codex, ya que viene con Chat GPT incluido en el precio, o pagar por GitHub Pro que incluye Copilot en el propio IDE. Ya es cuestión de evaluar cual nos sirve más, y si la vamos a utilizar para algo más que programar.
El resto, quizá Warp, que va muy bien si haces mucho tema en la consola o te conectas a servidroes, ya que la IA también puede actuar sobre tu conexión ssh. Pero las otras ni me lo plantearía.

