Hoy voy a hablar de un tema bastante importante, en el que voy a hacer un pequeño resumen sobre el tema de las APIs y el diseño de las mismas.
Hay varias formas de abarcar esta información, en este post voy a ir de fuera hacia dentro, donde creo que todo quedará bastante claro.
1- Entrada y salida en una API
Desde mi punto de vista es mejor empezar por el punto de entrada de dicha API, esto significa empezar por la parte agnóstica al lenguaje de programación que vayas a utilizar para la implementación de la API y es la única parte donde tus usuarios o tus consumidores van a interactuar, ya sea enviando datos o recibiendolos.
Aquí tenemos varios puntos importantes.
1.1 - Formato de una URL
Puede parecer una chorrada, pero hay que mantener unos estándares. El mayor problema que yo veo es que no hay nada que fuerce una URL a ser de cierta forma. Si encima trabajas en el ecosistema de .NET, aquí hemos vivido como Microsoft ha intentando forzar su estilo a todo el mundo en vez de adaptarse a lo ya existente.
Con esto qué quiero decir?
Cuando tenemos una URL donde queremos consultar una lista de productos el standard que se utiliza es el siguiente: url.com/api/v1/products
En .NET por defecto la cosa funciona algo diferente.
Para implementar esa funcionalidad necesitarás un controlador y un método dentro del controlador, el controlador lo llamas Products, lo que convierte a url en url.com/api/v1/Products (con mayuscula) y luego viene el método, si lo llamas "GetAllProducts" de url será url.com/api/v1/Products/GetAllProducts lo cual si bien funciona, no es ideal. Ya que debemos mantener una consistencia y no depender de un lenguaje o framework.
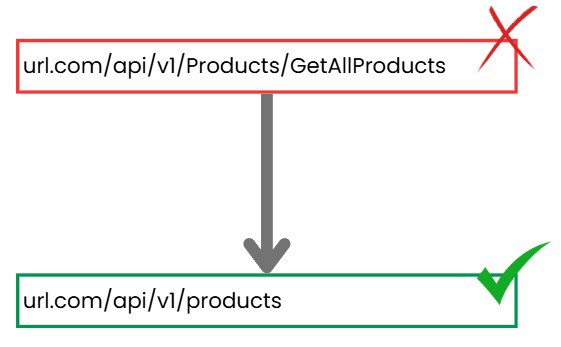
Elementos a tener en cuenta:
- La Url completa tiene que ser en minúscula
- No debe incluir elementos innecesarios
Por supuesto, en cualquier lenguaje, etas configuraciones se pueden cambiar de una forma muy sencilla, pero no todo el mundo lo hace.
El estilo de url "GetAllProducts" está más enfocado a RPC. Hay donde se hace RPC sobre http, pero eso da para otro post, o si quieres una introducción, puedes hacerlo con mi libro Construyendo Sistemas Distribuidos.
1.2 - Nombres compuestos
El tema de las URL no termina ahí, cuando tienes una ruta que contiene un nombre compuesto, por ejemplo url.com/api/v1/Products/{id}/UpdatePrice para actualizar el precio de un producto debemos separar los nombres con un guión (no guion bajo) de la siguiente forma: url.com/api/v1/products/{id}/update-price
Elementos a tener en cuenta:
- Separar los nombres compuestos con un guión
Nota: {id} representa el identificador único del recurso.
1.3 - Utilizar el método correcto
Como todos sabemos cuando realizamos una llamada HTTP tenemos múltiples métodos que podemos utilizar; Estos métodos están ahí para indicar una funcionalidad esperada. Aunque hay más, los más comunes son los siguientes:
GETpara leer recursosPOSTpara crear recursosPUTpara actualizer recursosDELETEpara eliminar recursos
Con estos, tienes el 99.99% de los casos de uso cubiertos. y como podemos ver es muy sencillo, aún así, hay gente que lo hace mal.
Habrás visto casos donde se utiliza un POST para actualizar recursos o incluso eliminar, porque claro, no estás eliminando el registro de la base de datos (si usas soft delete) así que se hace un POST o un PUT. Este diseño es erróneo, porque de cara al usuario final o cliente el registro queda eliminado ya que no pueden acceder a él.
Por lo tanto la forma de eliminar un registro es la siguiente [DELETE] url.com/api/v1/products/{id} como vemos hemos aplicado los puntos anteriores en el diseño de este endpoint.
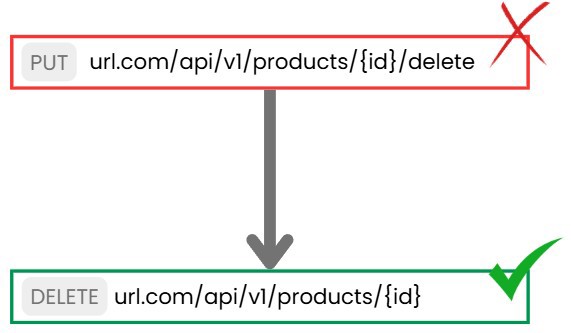
Ahora viene el caso de leer registros, cuando leemos un único registro no suele haber ninguna duda, pasamos el identificador por la URL y ya está [GET] url.com/api/v1/products/{id}.
Pero qué sucede cuando queremos obtener una lista de elementos, o algo más loco aún, cuando tenemos una búsqueda.
Para estos casos hay dos opciones que se suelen ver por igual, aunque no siempre se utilizan bien.
La primera opción es enviar un POST o un PUT aunque no estamos creando ni actualizando nada, esto se hace porque en el cuerpo del mensaje que enviamos,vamos a indicar todos los elementos de la búsqueda.
Esta opción no es errónea si estás utilizando un enfoque RPC en tu API.
Por el contrario, si estás utilizando RESTFul (que es lo más común para cualquier API que venga del Front End) estas llamadas deberían ser con el método GET, donde pasamos los parámetros como parte de la URL.
Incluso si estamos hacienda una selección de múltiples elementos, debemos mandarlos en la URL simplemente los separamos por comas, como podemos ver en el ejemplo sería el siguiente:
[GET] url.com/api/v1/products?ids=product1,product2,product3,product4
Elementos a tener en cuenta:
- Uso del método correcto a la hora de interactuar con los recursos del Sistema.
1.4 - Una única acción por recurso
Cada recurso de una API debe estar diseñado para realizar una única acción en el Sistema.
Por ejemplo, si tenemos un endpoint que se llame [POST] url.com/api/v1/products/update-price lo utilizaremos únicamente para actualizar el precio de un producto.
Este endpoint no debe actualizar otros valores como puede ser el nombre o las imágenes.
Lo mismo aplica en un servicio de pedidos si quitamos un producto [DELETE] url.com/api/v1/orders/remove-item, en ese caso si estamos un Sistema de microservicios o distribuido temenos que realizar dos acciones. La primera será eliminar el producto del pedido. La segunda es actualizar el stock, porque ese producto que ya no tenemos en este pedido debe pasar a estar disponible. La acción de actualizar el stock del producto no se hace desde el servicio de los pedidos, sino que generamos un evento, el cual será escuchado por el servicio correspondiente. Ver más sobre event sourcing.
Elementos a tener en cuenta:
- Atomicidad del funcionamiento de los recursos
1.5 - GraphQL y RPC
En caso de que utilices graphql o incluso RPC siempre trabajaras con POST y con estándares más marcados, por eso no he ido en detalle en este post.
aún así, tengo posts donde hablo de ambos
1.6 - Otros elementos clave
Hay otros elementos a tener en cuenta en el diseño de una API, pero no los considero dentro de lo que podríamos llamar diseño básico ya que van a cambiar entre caso y caso, así que no voy a entrar en ellos, además, este post sería del tamaño de un libro.
Estos elementos son los siguientes
1.7 - Códigos de estado de respuesta
El más importante es el uso correcto de los códigos de estado. Estoy Seguro de que muchos habéis visto una respuesta de una API erronea, pero luego lees la respuesta y resulta que hay un error. Esto es una cagada. Lo que hay que hacer es utilizar los códigos de estado correctos. para ello los Podemos separar en arias categorias
- 100-199 -> Códigos de información
- 200-299 -> Códigos de éxito
- 300-399 -> Códigos de redirección
- 400-499 -> Códigos de error del cliente
- 500-599 -> Códigos de error del servidor

Si indicas correctamente el Código de estado HTTP, los consumidores sabrán si el recurso HTTP que han ejecutado ha funcionado como se esperaba.
Muchas aplicaciones tienen sistemas de monitorización, observabilidad y alertas de forma automática, por lo que indicar el código correcto es clave.
Elementos a tener en cuenta:
- Usa el Código de estado HTTP en la respuesta
1.8 - Objeto de la respuesta en una API
A la hora de responder hay dos estrategias que a mi me gustan, y las podemos diferenciar si lo que estamos programando es una API o es una API + SDK.
Desde mi punto de vista, cuando tenemos una api y estamos devolviendo valores debemos devolver un objeto, da igual si la llamada ha fallado o ha sido satisfactoria.
En caso de que falle, debemos utilizar el standard ProblemDetails, donde incluimos información del error para que el consumidor de la API sea capaz de leer y entender el problema. Este estándar está siendo adoptado por la gran mayoría de empresas en la actualidad.
En caso de que la llamada funcione, debemos responder con el objeto resultante. Ojo, cuando haces la respuesta, incluso si la respuesta es una lista, no devuelvas únicamente dicha lista, ponle un objeto alrededor para que puedas extender el endpoint si fuera necesario.
Lo que es intolerable es, cuando algo falla responder con nulo, o un string con el texto del error y ya está, eso no es una buena práctica.
1.8.1 - El caso SDK
Cuando desarrollamos un SDK lo que estamos haciendo es desarrollar un pequeño paquete o librería el cual abstrae las llamadas a la API. En este caso los clientes no actúan directamente con la API, sino que lo hacen a través de nuestro SDK.
En estas situaciones, cambiamos un poco el nombre de las acciones, ya que el cliente trabajará con objetos dentro el Código en vez de con los recursos HTTP directamente. Lo que haremos aquí será añadir los sufijos Request y Response a todos los objetos. Por ejemplo, si estamos consultando un producto en concreto, la llamada será GetProductRequest el cual aceptará un ID. por detrás sucede una llamada a a [GET]url.com/api/v1/Products/{id}.
A su vez, la respuesta será GetProductResponse y contendrá un objeto, el cual internamente ya habrá validado si la respuesta de la API tiene algún error o no, por lo que los usuarios pueden acceder sin problemas.
Elementos a tener en cuenta:
- Devuelve ProblemDetails para los errores
- Devuelve un objeto para los casos que funcionan.
1.9 - Open API
Open API es una especificación sobre cómo debemos escribir APIs Rest, con esta especificación lo que estamos haciendo es documentar en un fichero, con un estandard, nuestro punto de entrada a la API, por lo que es crucial tenerlo bien.
Aquí podemos especificar todas las reglas que queramos y servirá de referencia para todos los consumidores.
Además hay herramientas que convierten el fichero en código, por lo que la integración en cualquier lenguaje es mínima.
Finalmente, la gran mayoría de lenguajes de programación tienen herramientas para convertir código a la especificación de OpenAPI de forma automática sin tener que añadir apenas configuración.
2 - Diseño interno de una API
El diseño interno de una API es algo muy subjetivo, en este mismo blog hemos visto un montón de soluciones completamente válidas y unas pueden tener más sentido que otras, en unos lenguajes se priorizan ciertas arquitecturas sobre otras.
De hecho, en este canal hemos visto varias de estas arquitecturas
2.1 - Keep it Simple, Stupid Please
Quizá hayas escuchado alguna vez el acrónimo KISS que significa Keep It Simple Stupid, el cual en programación significa que hagas algo de forma sencilla y para tontos. A mi me gusta cambiar un poco ese acrónimo y decir KISP, ya que lo único que pido es que lo mantengas simple y sin sobre ingenieria, por favor.
Así que ya está, cuantas menos capas internas tengas mejor, no estoy hablando de llamar a la base de datos desde el controlador, pero en mi opinión hay muy pocas aplicaciones que merezcan tener algo más complejo a la arquitectura core-driven(https://www.netmentor.es/entrada/core-driven-architecture).
Por supuesto esta parte incluye el utilizar librerías que no tiene sentido utilizar o que no dan valor. Por ejemplo, la que siempre se critica en .NET es mediatr (y va a recibir otra vez) que en muchos proyectos se añade, pero pregúntate lo siguiente, Necesito en este proyecto el patrón mediador? Puede ser que sí, pero sí no lo necesitas, no incluyas la librería simplemente porque todos los proyectos lo hacen.
En otros casos, necesito la mejora de rendimiento que proporciona Dapper con respecto a Entity Framework? Cuando toda la empresa usa EF… O la contrapartida, necesito EF y todo su ecosistema cuando todo lo que hago es invocar Store procedures en la Base de datos.
Comparación entre dapper y entity framework aquí.
Cada paquete, librería y práctica tiene un motivo para existir y tenemos que comprender esos motivos para poder elegir las mejores opciones. Elegir únicamente la que conocemos y no estar abiertos a nuevas soluciones, o a dejar de utilizar ciertas librerías no es una buena solución a largo plazo.
2.2 - Breaking changes
Un breaking change es cuando una librería, sistema o API cambia y deja de funcionar como lo hacía, por lo que cada consumidor debe cambiar y actualizarse.
Para mi, esto es prácticamente injustificable, tener que hacer un breaking change significa una de las dos siguientes cosas:
- El proceso es completamente diferente
- Se diseñó inicialmente de forma errónea
Ambas son un problema, el primero está más enfocado en la parte de producto, el segundo está más enfocado en nosotros, los desarrolladores.
Lo ideal es evitar tener breaking changes, alguna vez es completamente inevitable, pero no suele ser el caso cuando algo se diseña bien desde un principio.
Cualquiera que haya tratado con breaking changes sabe lo que molesta, por no decir algo peor, tener que cambiar código porque a fulanito se le ha antojado que una propiedad no exista en un endpoint a partir de un día.
Dicho esto, depende en qué industria trabajes y que contratos tenga tu empresa firmados con clientes, hacer un breaking change puede ser legalmente imposible.
2.3 - API First Vs Front End Driven development
El último punto que quiero mencionar en este post es hablar sobre la forma en la que diseñamos nuestras API.
Sin entrar mucho en detalles, ya que podéis encontrar más información en mi libro construyendo sistemas distribuidos. Para resumir, podemos crear las APIs de dos formas.
La primera es como API First, esto significa que vamos a crear los endpoints y las decisiones sobre la misma sin importar los consumidores, pensando únicamente en las acciones del dominio sobre esa API y serán los consumidores quienes se tienen que adaptar a la misma. Esta implementación es muy popular en sistemas muy maduros donde muchos sistemas se comunican entre sí ya que de esta forma las APIs o sistemas son independientes entre sí.
Para el caso de FDD o front end driven development, es cuando desarrollamos las APIs para cubrir las necesidades del front end o de los clientes de la API, de esta forma el desarrollo total de todas las funcionalidades suele ser más rápido, en contra, tienes algo de acoplamiento entre los sistemas. Esta suele ser una solución que es muy útil como primer paso y yo la he vivido bastante, por ejemplo, si estamos migrando de un sistema monolítico a microservicios, hacer FDD es lo más sencillo, pues lo que hacemos es extraer el código lo más rápido posible.

