Hoy vamos a ver cómo ejecutar modelos directamente en tu propia máquina, sin pagar suscripciones mensuales, sin perder el control de tus datos y sin necesidad de estar conectado a internet.
Tabla de contenidos
1 - ¿Te gustaría usar inteligencia artificial sin depender de APIs caras ni enviar tus datos a terceros?
Si has seguido mi canal o mi blog habrás visto que he trabajado bastante con la inteligencia artificial. Tengo un vídeo probando codex y otro evaluando las 6 IAs online más populares con una comparación real entre ellas. Ambos vídeos gustaron bastante, pero hubo un comentario que se repitió de forma constante, el coste de estas herramientas, ya que para muchos es un problema;
Por eso, en este post (y posiblemente en el curso entero) voy a mostrarte cómo ejecutar modelos de IA con C# de forma local, para que puedas experimentar, aprender o incluso trabajar sin depender de servicios externos.
En muchos casos la empresa va a pagar estos costes, pero en otros no quieren la inteligencia artificial ni en pintura, o no podemos acceder a ella desde un dispositivo que no es el de la empresa, así que si quieres hacer pruebas o jugar un rato con ella no es posible.
Sin olvidar el tema de la privacidad, hay modelos y APIs gratuitas para aquellos que no pueden costearse el precio de la IA, donde vamos a estar mandando información, en muchos casos personal o incluso confidencial (si es de la empresa) a otras empresas para que sepan lo que estamos haciendo. Esto es claramente un problema y si no pagas por un producto el producto eres tú.
Finalmente, los modelos locales funcionan en local, lo que hace que no necesitemos conexión a internet para funcionar, aunque en este caso, necesitamos una máquina más potente ya que hay modelos muy grandes.
2 - Preparar nuestra máquina local para ejecutar Inteligencia artificial.
En este vídeo vamos a tratar con Llama, pero puedes utilizar DeepSeek, Gemma, Mistral o el que quieras.
Ahora para comunicarnos con los modelos tenemos dos formas. Invocar directamente a dicho modelo con la CLI, para ello necesitamos descargar dos cosillas, primero son los binarios de Llama, que lo podemos hacer desde GitHub (https://github.com/ggml-org/llama.cpp/releases) y seleccionar el de tu sistema Operativo.
Una vez los tenemos descargados necesitamos descargar el modelo ya entrenado, el cual lo puedes encontrar aquí: Enlace tinyLllama1.1b.
Ahora ponemos los DLL y la CLI de la release junto al modelo que hemos descargado de Llama en una carpeta.
Si corremos el siguiente comando nos debería de funcionar:
.\llama-cli.exe --model .\tinyllama-1.1b-chat-v1.0.Q8_0.gguf --prompt "reverse a binary tree in C#"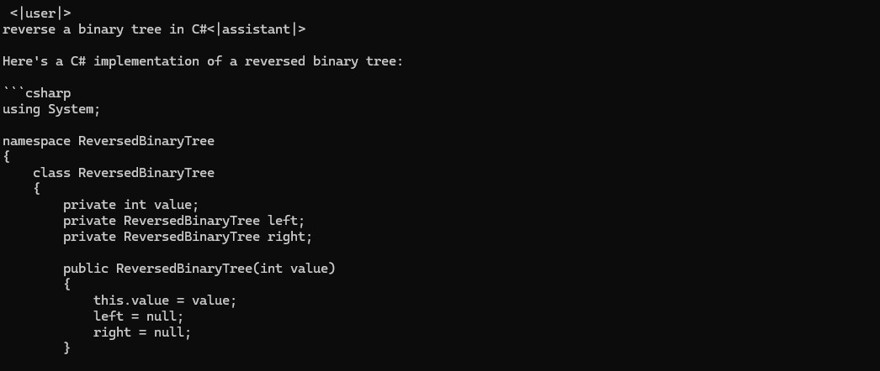
Pero claro, nosotros no queremos utilizar la CLI, por lo menos no directamente, para ello tenemos varias opciones.
2.1 - Ejecuta Inteligencia artificial a través de Ollama y C#
La primera opción (y la más popular) es instalar en tu máquina local ollama, un cliente de modelos el cual permite ejecutar dichos modelos de forma local.
Una vez instalas Ollama, tienes que descargarte los modelos, si ejecutas el comando que sale en la imagen descargarás gemma3, pero puedes cambiarlo para descargar el modelo que quieras como Llama3:

Una vez descargado, ya funciona desde la línea de comandos:
Nota: Alternativamente existen proyectos en github que ponen una interfaz encima de esta CLI.
Pero siguiendo con el contenido del post, la forma en la que nos vamos a comunicar desde una aplicación hacia Ollama es utilizando llamadas HTTP a través de la librería OllamaSharp que es la más popular
Uri uri = new Uri("http://localhost:11434");
OllamaApiClient ollama = new OllamaApiClient(uri);
// select a model which should be used for further operations
ollama.SelectedModel = "llama3";
Chat chat = new Chat(ollama);
while (true)
{
Console.Write(">>");
string? message = Console.ReadLine();
await foreach (string answerToken in chat.SendAsync(message))
Console.Write(answerToken);
}
Y si lo ejecutamos vemos como funciona perfectamente:

2.2 - ejecuta modelos de inteligencia artificial directamente desde C#
La segunda opción es hacerlo utilizando directamente el modelo, para este caso vamos a utilizar la librería LlamaSharp. En este caso utilizamos una librería porque facilita la vida, pero se puede hacer sin librerías.
Para ello debemos instalar llamasharp y llamasharp.backend.cpu y adaptar el siguiente código a nuestras necesidades, especialmente con el mensaje para el contexto del sistema y la ruta del modelo:
string modelPath = @"C:\Users\ivan\Downloads\tinyllama-1.1b-chat-v1.0.Q8_0.gguf"; // 👈 model path
var parameters = new ModelParams(modelPath)
{
ContextSize = 1024, // The longest length of chat as memory.
GpuLayerCount = 5 // How many layers to offload to GPU. Please adjust it according to your GPU memory.
};
using var model = LLamaWeights.LoadFromFile(parameters);
using var context = model.CreateContext(parameters);
var executor = new InteractiveExecutor(context);
// Add chat histories as prompt to tell AI how to act.
var chatHistory = new ChatHistory();
chatHistory.AddMessage(AuthorRole.System, "you are an expert in programmin and C#. You should answer all " +
"questions in a friendly manner and provide code examples if needed.");
ChatSession session = new(executor, chatHistory);
InferenceParams inferenceParams = new InferenceParams()
{
MaxTokens = 256, // No more than 256 tokens should appear in answer. Remove it if antiprompt is enough for control.
AntiPrompts = new List<string> { "User:" }, // Stop generation once antiprompts appear.
SamplingPipeline = new DefaultSamplingPipeline(),
};
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine("The chat session has started;");
Console.ForegroundColor = ConsoleColor.Blue;
Console.Write("User: ");
Console.ForegroundColor = ConsoleColor.Green;
string userInput = Console.ReadLine() ?? "";
while (userInput != "exit")
{
await foreach ( // Generate the response streamingly.
var text
in session.ChatAsync(
new ChatHistory.Message(AuthorRole.User, userInput),
inferenceParams))
{
Console.ForegroundColor = ConsoleColor.Blue;
Console.Write(text);
}
Console.ForegroundColor = ConsoleColor.Green;
userInput = Console.ReadLine() ?? "";
}
Ahora si lo ejecutamos vemos que funciona igual que antes:

Conclusión
Utilizar modelos locales para trabajar con la inteligencia artificial tiene un montón de ventajas como hemos mencionado al principio, no solo de privacidad pero también de coste.
El uso de los modelos de pago a través de una API puede llegar a ser muy costoso, tanto como el sueldo de un desarrollador, así que para la gran mayoría de escenarios, especialmente en programación los modelos gratuitos son prácticamente igual de eficientes a los modelos de pago.
Sobre si utilizar Ollama o directamente el modelo, es un poco a gustos, mi recomendación es que pruebes ambos y decidas cuál te gusta más!

