When we design a system, we tend to obsess over things that look nice on a diagram: microservices, queues, events, a super scalable database… and then we deploy everything on a server, whether that is a VPS or in the cloud, and forget about it.
Many times we overlook something very important: latency. In many cases we have been sold the illusion that infrastructure is ubiquitous, but the reality is that where you deploy your code matters as much as, or more than, how you write it. Today we are going to break down how geography impacts your architecture.
Table of contents
But before talking about milliseconds, we need to understand that network geography does not only affect speed, but also behavior and access to data. And this is where this post's sponsor comes in: DataImpulse.com.
When you consume third-party APIs, scrape sites, or build automations on a global level, external servers treat you differently depending on your geographic location. They may apply regional blocks, traffic limits (rate-limiting), or return altered data. DataImpulse is a proxy provider designed for developers and companies that need to solve exactly this problem. They let you route your requests through IPs in specific geographic locations, allowing you to simulate local traffic for data collection, testing, or market research, no matter where your server is physically located. If you work with external integrations at scale, take a look at them.
That said, let us get back to our own infrastructure. What happens with internal latency and the latency of our users?
1 - Distance affects your users' experience
In many situations we place the server wherever, like, well, just put it there, if everything works, and the reality is that in many cases that is true. If my users are in Europe, the normal thing is to deploy the system in one of the European regions. To get an idea, deploying in eu-west-1 (Ireland) gives you a latency of around 12 milliseconds from London and around 25 milliseconds from Madrid. That is completely acceptable.
The problem is when we have customers on the other side of the Atlantic. In the case of Spain and LATAM, it is very common to have a website in Spanish and users from all regions. Not only that, but the distances between Mexico and Santiago or Buenos Aires are enormous, so the experience affects our users a lot.
If our content is in English, aside from being the world's language, it is the official language of Ireland + the UK, the United States, and Australia, 3 different parts of the world as far away from each other as possible.
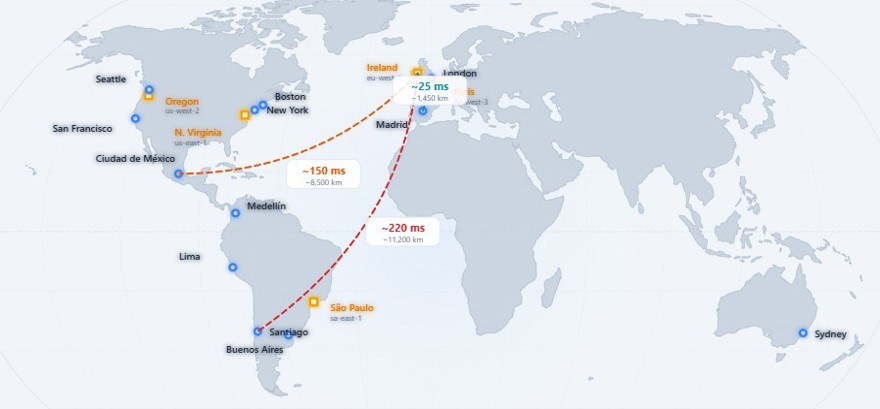
This means that a European customer with a server in Europe gets a great user experience, but if we have customers in LATAM their user experience is going to be much worse.
And unfortunately, no software change is going to fix this situation. We can have our whole system at O(1), but if our users are 11 thousand kilometers away, all that optimization is useless.
1.1 - using “the cloud” is not enough
Knowing where to place our server is one of the big questions when we are starting a company. A very common mistake is to deploy and verify that things work only from where the development team is located
If the team is in Madrid, and the server is in Ireland, maybe everything looks reasonable. You see 20ms, 40 ms, or 60 ms, and assume the experience is good.
But that data is biased because if your market is later in LATAM or Australia, the exact same system behaves like a different product. Not because the code changed, but because the network path did.
And let us be honest, it feels like a different product.
Here we can introduce the term Latency budget, which is basically the allowed time for a system to process a request and return it to the user. Today it is considered that:
- An API should respond in less than 300 ms.
- A web page should load in less than 1.2 seconds.
Greg Linden, a former Amazon employee, said more than 10 years ago that their sales drop by 1% for every extra 100 milliseconds in load time.
Source: https://glinden.blogspot.com/2006/11/marissa-mayer-at-web-20.html
If 300ms is the maximum time we have and the bulk of our users are thousands of kilometers away, we are going to burn that budget on latency alone, leaving us very little room to execute business logic.
In fact, at this point we can kill ourselves optimizing the code by 10 milliseconds and it will do little or nothing when 80% of our budget is burned by distance itself.
The solution to this problem is multi-region, basically deploying the system across multiple regions. In our case, we could deploy in Europe and in LATAM on the Mexico or Brazil server, depending on where our users are.
2 - Distributed Architecture: How and where do we deploy?
Once we accept that distance matters, we have to decide how to organize our servers. This is where we go from a nice diagram to decisions that affect both cost and performance.
2.1 - The cost of multi-region
Everything sounds fantastic, right? You deploy your system in several regions and send each user to the nearest one (via geo DNS, Anycast, CDN with edge compute, whatever), keeping everything always available, but we introduce 3 critical problems.
- Data Consistency: If a user in Madrid updates their profile on the Europe server and one second later someone checks their data from the Brazil server, is the data synchronized? Maintaining a global database requires choosing between write latency (waiting for all regions to confirm) or eventual consistency.
- Data Egress Costs (Egress): Cloud providers do not charge you for putting data in, but they do charge you, and a lot, for taking it out or moving it between regions. Replicating databases across continents can blow up your monthly bill.
- Operational Complexity: You now have n infrastructures to monitor, n deployment pipelines, and n possible points of failure.
2.2 - Latency in cross-region systems
Understanding client-server latency is the first step, but the mistake I most often see less experienced teams make is ignoring service-to-service latency.
What happens when we have the API in Ireland, but someone, which could be a government, has decided that the database has to live in a specific country, for example, Germany?
Within the same region, making the API call and then going to the database or cache can take 1 or 2 ms, which is virtually nothing.
Let us say your endpoint makes 3 DB queries and 2 cache queries, internal processing is around 8 ms. Adding the user's 24 ms travel time (round trip), the total response time is around 32 ms, something completely enviable.
But when you have both infrastructure elements in Germany, time adds up, and not by a little. With the same architecture, every single query to the database or cache suffers a 30 ms network penalty. Those same 5 data accesses now add 150 ms of time doing nothing.
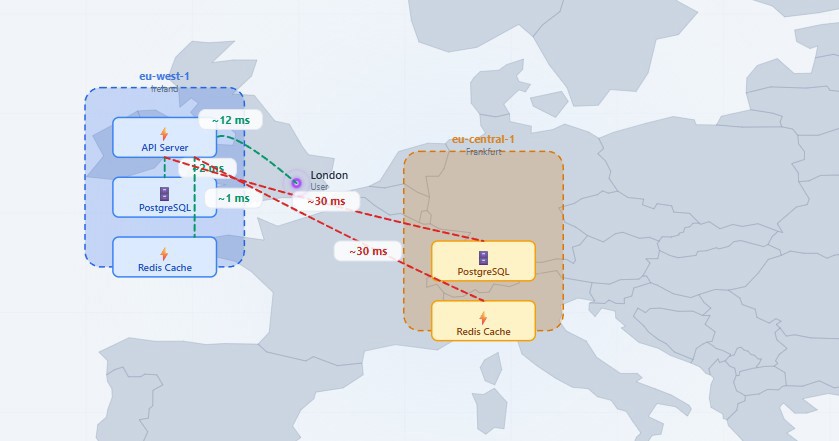
It is clear there are ways to optimize, but this architecture creates a latency problem that we simply do not have if everything is in the same zone.
Having distributed systems in multiple regions that depend on one another does not usually happen because it brings no benefits, but I have seen it, and I have also been forced to implement it myself (what I mentioned about data living in one country).
2.3 - Redundancy with Availability Zones
If what you are looking for is a replica system so that if the server catches fire you can keep your application running, that is where availability zones come in.
When we work in one region, what we are really doing is working in a geographic area made up of multiple independent data centers. In the case of eu-west-1, the reality is that we have eu-west-1a, eu-west-1b, and eu-west-1c. To simplify, we can say they are far enough apart that a failure in one does not affect another, but close enough that we barely have any latency between them (1-2 ms).
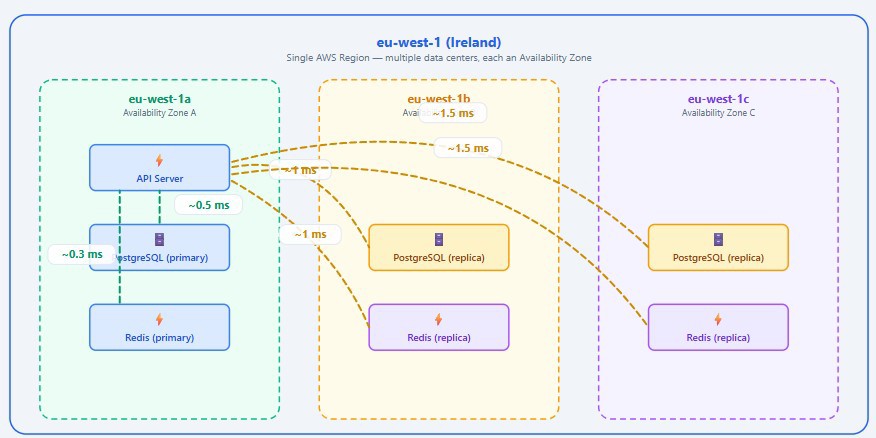
The most common setup is for them to be on the outskirts of a city, distributed in a triangle shape. But as I said, that is just to simplify it. 3 AZs do not mean 3 buildings, but rather groups of buildings that together make up an availability zone, and the latency difference is insignificant for 99% of applications.
My recommendation for any production system (as we see in my book Building Distributed Systems) is to always deploy across at least two AZs. Most cloud providers offer managed services (such as RDS on AWS or Cloud SQL on Google) that handle replication between zones automatically.
which causes that if AZ "A" suffers a massive power failure, your load balancer will redirect traffic to AZ "B" in milliseconds.
and to finish the earlier example with the 5 queries, the extra cost of communicating across different zones is only about +3 to +5 ms in total. It is an insignificant price.
