Cuando diseñamos un sistema, tendemos a obsesionarnos con cosas que se ven bonitas en un diagrama: microservicios, colas, eventos, una base de datos súper escalable… y luego desplegamos todo en el servidor ya sea un VPS o en la nube y nos olvidamos.
Muchas veces pasamos por alto algo muy importante, la latencia. En muchos casos nos han vendido la ilusión de que la infraestructura es ubicua, pero la realidad es que dónde despliegas tu código importa tanto o más que cómo lo escribes. Hoy vamos a diseccionar cómo impacta la geografía en tu arquitectura.
Tabla de contenidos
Pero antes de hablar de milisegundos, hay que entender que la geografía de la red no solo afecta a la velocidad, sino al comportamiento y acceso a los datos. Y aquí es donde entra el patrocinador de este post: DataImpulse.com.
Cuando consumes APIs de terceros, haces scraping o construyes automatizaciones a nivel global, los servidores externos te tratan de forma distinta dependiendo de tu ubicación geográfica. Te pueden aplicar bloqueos regionales, límites de tráfico (rate-limiting) o devolverte datos alterados. DataImpulse es un proveedor de proxies diseñado para desarrolladores y empresas que necesitan resolver exactamente este problema. Te permiten enrutar tus peticiones a través de IPs en ubicaciones geográficas específicas, permitiéndote simular tráfico local para recolección de datos, testing o investigación de mercado, sin importar dónde esté físicamente tu servidor. Si trabajas con integraciones externas a escala, échales un vistazo.
Enlace a DataImpulse.
Dicho esto, volvamos a nuestra propia infraestructura. ¿Qué pasa con la latencia interna y la de nuestros usuarios?
1 - La distancia afecta a la experiencia tus usuarios
En muchas situaciones ponemos el servidor donde sea, en plan bah, ponlo ahí, si todo va bien y la realidad es que en muchos casos es cierto. Si mis usuarios están en europa lo normal es desplegar el sistema en uno de las regiones de europa. Para hacernos una idea, desplegar en eu-west-1 (irlanda) tiene una latencia de unos 12 milisegundos desde londres y unos 25 milisegundos desde madrid. Lo cual es completamente aceptable.
El problema es cuando tenemos clientes que están al otro lado del charco, en el caso de españa y LATAM es muy común tener una web en castellano y tener usuarios de todas las regiones, no solo eso, las distancias entre méxico y Santiago o Buenos aires son brutales, por lo que la experiencia afecta y mucho a nuestros usuarios.
En el caso de que nuestro contenido sea en inglés, al margen de ser el idioma del mundo, es la lengua oficial de Irlanda + UK, Estados Unidos y Australia, 3 zonas del mundo diferentes alejadas lo máximo posible unas de otras.
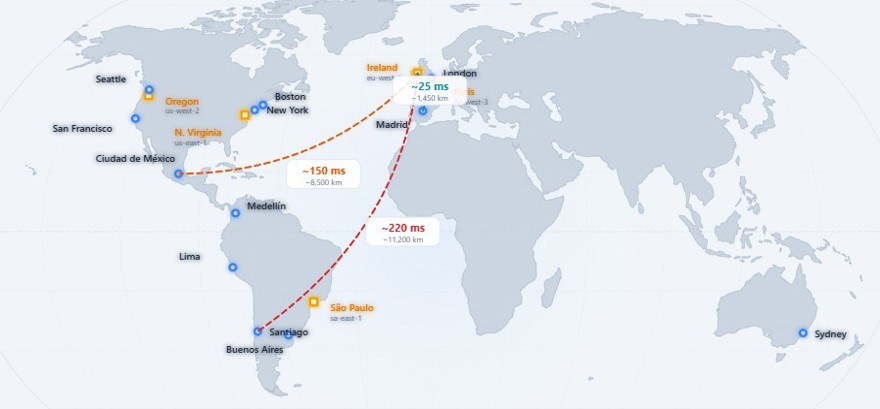
Esto se traduce en que un cliente europeo con un servidor en europa tiene una experiencia de usuario buenísima, pero si tenemos clientes en LATAM su experiencia de usuario va a ser mucho peor.
Y desafortunadamente ningún cambio en el software va a arreglar esta situación, ya podemos tener todo nuestro sistema con O(1) que si nuestros usuarios estan a 11mil kilometros de nada nos sirve toda esta optimización.
1.1 - usar “la nube” no es suficiente
Saber dónde poner nuestro servidor es una de las grandes preguntas cuando estamos empezando una empresa. Muchas veces se comete el error de de desplegar y comprobar que las cosas funcionan únicamente desde donde está el equipo de desarrollo
Si el equipo está en Madrid, y el servidor está en Irlanda, quizá todo parece razonable. Ves 20ms, 40 ms ó 60 ms, y das por hecho que la experiencia es buena.
Pero ese dato está sesgado porque si luego tu mercado está en LATAM o Australia, el mismo sistema se comporta como otro producto distinto. No porque el código haya cambiado, sino porque el camino de red sí ha cambiado.
Y seamos sinceros, se siente como un producto distinto.
Aquí podemos introducir el término de Latency budget, básicamente es el tiempo permitido para que un sistema procese una request y la devuelve al usuario. Actualmente se considera que:
- Una API debe responder en menos de 300 ms.
- Una página web debe cargar en menos de 1.2 segundos.
Greg Linden, un ex-Amazon dijo hace más de 10 años que sus ventas bajan un 1% por cada 100 milisegundos extra en el tiempo de carga.
Fuente: https://glinden.blogspot.com/2006/11/marissa-mayer-at-web-20.html
Si, 300ms es el tiempo máximo que disponemos y el grueso de nuestro usuarios está a miles de kilómetros de distancia, vamos a quemar este budget únicamente con la latencia, dejándonos poco margen de maniobra para realizar la lógica de negocio.
De hecho, llegado este punto ya podemos matarnos para optimizar el código 10 milisegundos que de poco o nada va a servir cuando el 80% de nuestro budget se quema por la distancia en sí.
La solución a este problema es multi-region, básicamente desplegar el sistema en múltiples regiones, en nuestro caso podríamos desplegar en Europa y en LATAM el servidor de méxico o en el de Brasil, dependiendo de donde estén nuestros usuarios.
2 - Arquitectura Distribuida: ¿Cómo y dónde desplegamos?
Una vez que aceptamos que la distancia importa, tenemos que decidir cómo organizar nuestros servidores. Aquí es donde pasamos de "un diagrama bonito" a decisiones que afectan al bolsillo y al rendimiento.
2.1 - El coste de multi-región
Todo parece fantástico verdad? Despliegas tu sistema en varias regiones y dirige a cada usuario a la más cercana (vía DNS geo, Anycast, CDN con compute en el edge, lo que sea), teniendo todo siempre disponible, pero introducimos 3 problemas críticos.
- Consistencia de Datos: Si un usuario en Madrid actualiza su perfil en el servidor de Europa y un segundo después alguien consulta sus datos desde el servidor de brasil, ¿están los datos sincronizados? Mantener una base de datos global requiere elegir entre latencia de escritura (esperar a que todas las regiones confirmen) o consistencia eventual.
- Costes de Salida de Datos (Egress): Las nubes no te cobran por meter datos, pero te cobran y mucho por sacarlos o moverlos entre regiones. Replicar bases de datos entre continentes puede disparar tu factura mensual.
- Complejidad Operativa: Ahora tienes n infraestructuras que monitorizar, n pipelines de despliegue y n posibles puntos de fallo.
2.2 - Latencia en sistemas cross región
Entender la latencia cliente-servidor es el primer paso, pero el error que veo cometer con más frecuencia a equipos con menos experiencia es ignorar la latencia servicio a servicio.
Qué es lo que sucede cuando tenemos la API en Irlanda, pero alguien (que puede ser un gobierno) ha decidido que la base de datos tiene que vivir en el país en concreto, por ejemplo, Alemania.
En una misma región, hacer la llamada a la api y de ahí ir a la base de datos o la caché puede ser 1 o 2 ms, lo que es virtualmente nada.
Pongamos que tu endpoint hace 3 consultas a DB y 2 a caché, el procesamiento interno son unos 8 ms. Sumando los 24 ms de viaje (ida y vuelta) del usuario, el tiempo total de respuesta es de unos 32 ms, algo completamente envidiable.
Pero cuando tienes ambos elementos de la infraestructura en alemania, el tiempo suma, y no es poco. Con la misma arquitectura cada simple consulta a la base de datos o caché sufre una penalización de red de 30 ms. Esos mismos 5 accesos a datos ahora añaden 150 ms de tiempo que no hace nada.
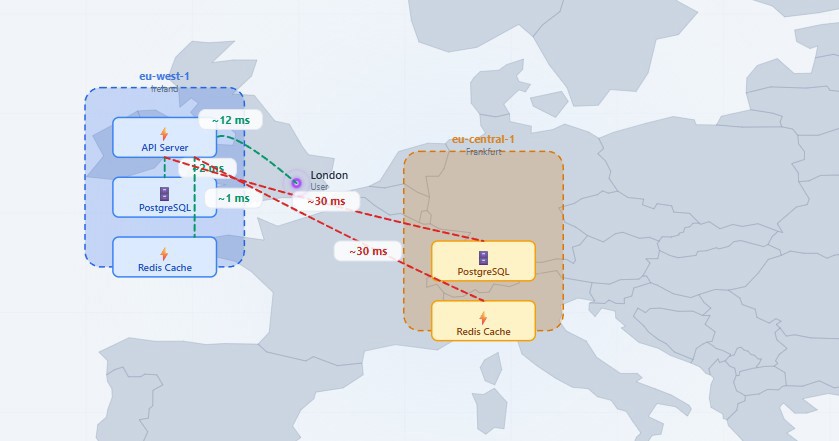
Está claro que hay formas de optimizar, pero esta arquitectura te genera un problema de latencia que si está todo en la misma zona no tenemos.
Tener sistemas distribuidos en multiples regiones que sean dependientes unos de otros no suele pasar porque no da beneficios, pero yo lo he visto y también me he visto obligado a implementarlo (lo que he mencionado de los datos en un país).
2.3 - La redundancia con Availability zones
Si lo que buscas es un sistema de réplica por si el servidor se pega fuego poder seguir teniendo tu aplicación, ahí es donde entran las availability zones.
Cuando trabajamos en una región, en realidad lo que estamos haciendo es trabajar en una zona geográfica que está compuesta por múltiples centros de datos independientes. En el caso de eu-west-1 la realidad es que tenemos eu-west-1a, eu-west-1b, y eu-west-1c, por simplificar podemos decir que entre ellas están separadas lo suficiente para que un fallo en una no afecte a otra, pero lo suficientemente cerca como para que apenas tengamos latencia entre las mismas (1-2 ms).
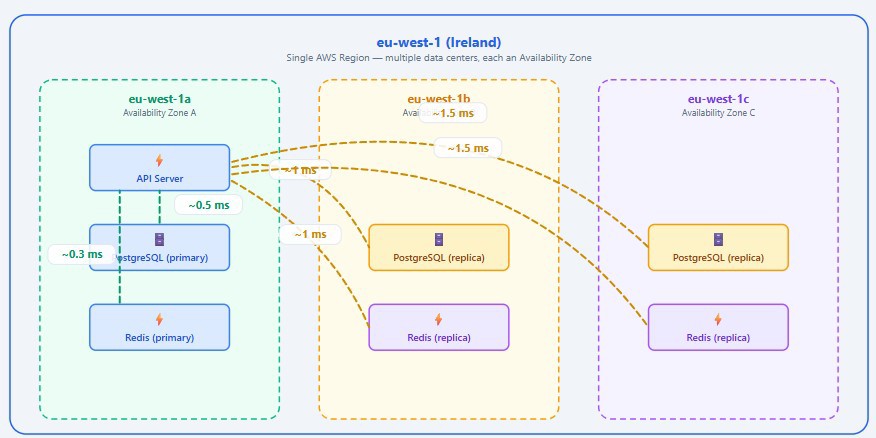
Lo mas normal es que estén a las afueras de una ciudad, repartidas en forma de triángulo. Pero como digo, es por simplificar, 3 AZ no significa 3 edificios, sino conjunto de edificios que juntos hacen el availability zone, y la diferencia de latencia es insignificatne para el 99% de aplicaciones.
Mi recomendación para cualquier sistema en producción (como vemos en mi libro Construyendo sistemas distribuidos) es desplegar siempre en un mínimo de dos AZs. La mayoría de los proveedores de nube ofrecen servicios gestionados (como RDS en AWS o Cloud SQL en Google) que gestionan la replicación entre zonas de forma automática.
lo que causa que si la AZ "A" sufre un fallo eléctrico masivo, tu balanceador de carga redirigirá el tráfico a la AZ "B" en milisegundos.
y para acabar con el ejemplo de antes con las 5 consultas, el sobrecoste de comunicarse entre diferentes zonas es de apenas +3 a +5 ms en total. Es un precio insignificante.

